
cs231n筆記1:影象分類
幾個術語初步瞭解下:影象分割、面部檢測(Adaboost)、object recognization、SIFT(SIFT演算法是一種提取區域性特徵的演算法,在尺度空間尋找極值點,提取位置,尺度,旋轉不變數 )、語義分割(將畫素按照影象中表達語義含義的不同進行分組)
影象分類是計算機視覺領域的核心問題之一,並且有著各種各樣的實際應用。其實在計算機視覺領域中很多看似不同的問題(比如物體檢測和分割),都可以被歸結為影象分類問題。
對於計算機來說,影象是一個由數字組成的巨大的3維陣列。比如對一個貓的影象大小是寬248畫素,高400畫素,有3個顏色通道,分別是紅、綠和藍(簡稱RGB)。如此,該影象就包含了248X400X3=297600個數字,我們的任務就是把這些上百萬的數字變成一個簡單的標籤,比如“貓”。
在實際中,視角變化、大小變化、遮擋、光照條件、背景干擾、類內差異(貓有多種)等等,這些因素對計算機視覺演算法的影象識別造成了困難的。一個好的識別模型必須對這些因素有魯棒性。
一、KNN
為了對影象分類有個基本的認識,我們來介紹下一個簡單的分類演算法:KNN。使用kaggle競賽題目CIFAR-10 - Object Recognition in Images
資料集中共60000張影象,其中訓練集包含50000張影象,測試集包含10000張影象。一共有10個標籤。Nearest Neighbor演算法將會拿著測試圖片和訓練集中每一張圖片去比較,然後將它認為最相似的那個訓練集圖片的標籤賦給這張測試圖片。
那麼怎麼比較影象之間的相似性呢?
最簡單的方法就是逐個畫素比較,最後將差異值全部加起來。換句話說,就是將兩張圖片先轉化為兩個向量和,然後計算他們的距離:
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)
注意,在使用分類器訓練之前,要把資料變換為行向量(一張影象就是一個向量):
Xtr_rows = Xtr.reshape(Xtr.shape[0], 32 * 32 * 3) #原影象大小是50000x32x32x3
除了距離,還可以用距離:
distances = np.sqrt(np.sum(np.square(self.Xtr - X[i,:]), axis = 1))
注意在實際中可以把np.sqrt這一步去掉。因為求平方根函式是一個單調函式,它對不同距離的絕對值求平方根雖然改變了數值大小,但依然保持了不同距離大小的順序。
。L2對兩個向量之間的差異性容忍度更低。也就是說,對於1個巨大的差異,L2距離更傾向於接受多箇中等程度的差異(平方之後會把那個巨大差異放大)。在課程裡說到,距離(曼哈頓距離)對座標有依賴性,也就是說,向量的各個維度是有不同意義的.
把找最相似的一個影象變為找K個最相似的影象就變成了K-近鄰演算法,這樣,在K-近鄰演算法中,超引數就變為:K、距離度量的選擇,所謂超引數,就是不能直接從資料中學習到的,怎麼確定超引數呢?這就用到了訓練集、驗證集、測試集的劃分。
大致過程就是:在訓練集上用不同的超引數訓練演算法,然後在驗證集上評估,選擇表現最好的一組超引數,再拿這組超引數構成的分類器在測試集上執行,這個執行結果才是我們要寫到論文或報告上的。
在這個過程中要特別注意:決不能使用測試集來進行調優。當你在設計機器學習演算法的時候,應該把測試集看做非常珍貴的資源,不到最後一步,絕不使用它。測試資料集只使用一次,即在訓練完成後評價最終的模型時使用。測試集的存在,就是為了模擬分類器在線上的效果,儘可能的提高泛化效能。
有時候,訓練集數量較小,這時我們通常使用交叉驗證的方法,將訓練集平均分成5份,迴圈取其中4份用來訓練,1份用來驗證,最後取所有5次驗證結果的平均值作為演算法驗證結果。
question 訓練集和驗證集的區別?
在訓練集中,label是參與我們的訓練的,我們通過特徵向量與label來使得分類器能儘可能的好。
而在驗證集中,label對於分類器來說是不可見的,它只是用來驗證分類器的分類效果。
但是KNN對影象分類卻不適用,為什麼呢?
1)KNN訓練過程不用花太長時間(just儲存資料集就ok),但是測試集就要花很長時間(O(n),要依次計算與每個影象的相似度)
2)基於畫素比較的相似和感官上以及語義上的相似是不同的,所以說僅僅使用畫素差異來比較影象是不夠的。比如說,狗的圖片可能和青蛙的圖片非常接近,僅僅因為兩張圖片都是白色背景。
二、線性分類器
前面學習了把KNN用在影象分類上,但是效果並不好,最高也只有28%,這一節我們將要實現一種更強大的方法來解決影象分類問題,該方法可以自然地延伸到神經網路和卷積神經網路上。這種方法主要有兩部分組成:一個是評分函式(score function),它是原始影象資料到類別分值的對映。另一個是損失函式(loss function),它是用來量化預測分類標籤的得分與真實標籤之間一致性的。該方法可轉化為一個最優化問題,在最優化過程中,將通過更新評分函式的引數來最小化損失函式值。
從影象到標籤分值的引數化對映
線性分類器的評分函式就是一個從影象資料到類別分值的一個線性對映。
線性分類器是引數化方法中最簡單的演算法,用一個函式,計算出每個類別的得分。例如,x是32x32x3的影象所轉化的數字陣列(展開是個3072x1長列向量),W是10x3072的矩陣,相乘得到10個類的評分,即 f 為10x1的列向量,有時會給這10個類的分數加一個偏置項b,它是一個10x1元素的常數向量,它是僅針對一類的獨立的偏好值,不與訓練資料互動,如當資料集中貓的數量很多時,貓的偏差元素就會高一點。
預告:卷積神經網路對映影象畫素值到分類分值的方法和上面一樣,但是對映(f)就要複雜多了,其包含的引數也更多。
線性分類器的理解
線性分類器計算影象中3個顏色通道中所有畫素的值與權重的矩陣相乘,從而得到分類分值。根據我們對權重設定的值,對於影象中的某些位置的某些顏色,函式表現出喜好或者厭惡(根據每個權重的符號而定)。舉個例子,可以想象“船”分類就是被大量的藍色所包圍(對應的就是水)。那麼“船”分類器在藍色通道上的權重就有很多的正權重(它們的出現提高了“船”分類的分值),而在綠色和紅色通道上的權重為負的就比較多(它們的出現降低了“船”分類的分值)。
為了方便理解,假設影象只有4個畫素(都是黑白畫素,這裡不考慮RGB通道),有3個分類(貓,狗,船)。首先將影象畫素拉伸為一個列向量,與W進行矩陣乘,然後得到各個分類的分值。但是這裡這個W一點也不好:貓分類的分值非常低。從上圖來看,演算法倒是覺得這個影象是一隻狗。

線性分類器的理解1:模板匹配
訓練線性分類器可以理解為通過訓練得到每個類別的模板(W的一行就對應一個類的模板,一行中的每一項就說明哪個畫素該類別有多少影響),然後通過使用內積(或點積)將每個模板與影象進行比較來獲得影象的每個類的得分逐個找到“最適合”的那個類。如果將權重W分解回影象的大小(每一行得到一個影象,每個影象就代表了一個類別),就可以視覺化看到每個類的模板。

但是線性分類器每個類別只能學習一個模板,如果這個類別出現了變體,他將求取所有不同變體的平均值來作為這個類別的模板。如在horse分類器中,像是有兩個頭(分別朝左和朝右),就是因為它取了兩個類別的一個平均作為它的模板。神經網路和更復雜的模型能夠得到更好的準確率,因為它能夠在其隱藏層中開發中間神經元,可以檢測特定的汽車型別(例如,面向左側的綠色汽車,面向前方的藍色汽車等),下一層的神經元可以將這些組合在一起通過各個汽車探測器的加權總和得到更準確的汽車得分。
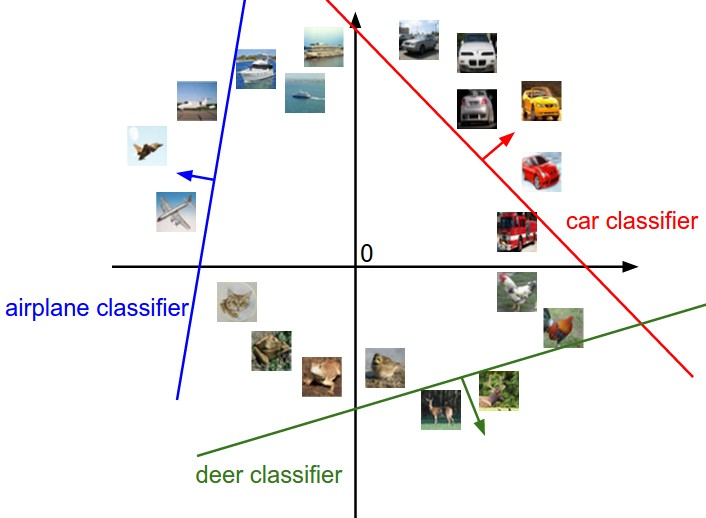
線性分類器的理解2:高維空間上的點的線性劃分
將每張圖片看作是高維空間中單個點(例如CIFAR-10中的每個影象是3072維空間中的點),線性分類器在這些線性決策邊界上嘗試畫一個線性分類面來劃分一個類別和剩餘其他類別。舉例,在二維空間上的線性分類器:
偏差b和權重w的合併技巧:這個技巧是經常使用的,回想一下分類評分函式定義為:,分開處理這兩個引數有點笨拙,一般常用的方法是把兩個引數放到同一個矩陣中,同時x向量就要增加一個維度,這個維度的數值是常量1,這就是預設的偏差維度。這樣新的公式就簡化成
以CIFAR-10為例,那麼x的大小就變成[3073x1],而不是[3072x1]了,多出了包含常量1的1個維度)。W大小就是[10x3073]了。w中多出來的這一列對應的就是偏差值,具體見下圖:

這樣我們就只需要學習一個權重矩陣,而不用去學習兩個分別裝著權重和偏差的矩陣了。
影象資料預處理:在上面的例子中,所有影象都是使用的原始畫素值(從0到255)。在機器學習中,對於輸入的特徵做歸一化(normalization)處理是常見的套路。而在影象分類的例子中,影象上的每個畫素可以看做一個特徵。在實踐中,對每個特徵減去平均值來中心化資料是非常重要的。在這些圖片的例子中,該步驟意味著根據訓練集中所有的影象計算出一個平均影象值,然後每個影象都減去這個平均值,這樣影象的畫素值就大約分佈在[-127, 127]之間了。下一個常見步驟是,讓所有數值分佈的區間變為[-1, 1]。零均值的中心化是很重要的,等我們理解了梯度下降後再來詳細解釋。
總結:
通過KNN演算法和線性分類器對影象分類有了一個基本的認識
1、KNN:如何比較兩個影象的相似度,同時學習了L1距離和L2距離,KNN在影象分類上的不適用性。
2、為了保證分類器的評估效果的公正性,採用訓練集+驗證集+測試集的劃分,尤其注意測試集是在最後一步使用的。
3、對線性分類器的兩種理解,在作業中庸svm和softmax兩種方式實現一個線性分類器。