
深度學習分割網路U-net的pytorch模型實現
阿新 • • 發佈:2018-12-31
原文:http://blog.csdn.net/u014722627/article/details/60883185
pytorch是一個很好用的工具,作為一個python的深度學習包,其介面呼叫起來很方便,具備自動求導功能,適合快速實現構思,且程式碼可讀性強,比如前陣子的WGAN1
好了回到Unet。
原文 arXiv:1505.04597 [cs.CV]
主頁 U-Net: Convolutional Networks for Biomedical Image Segmentation
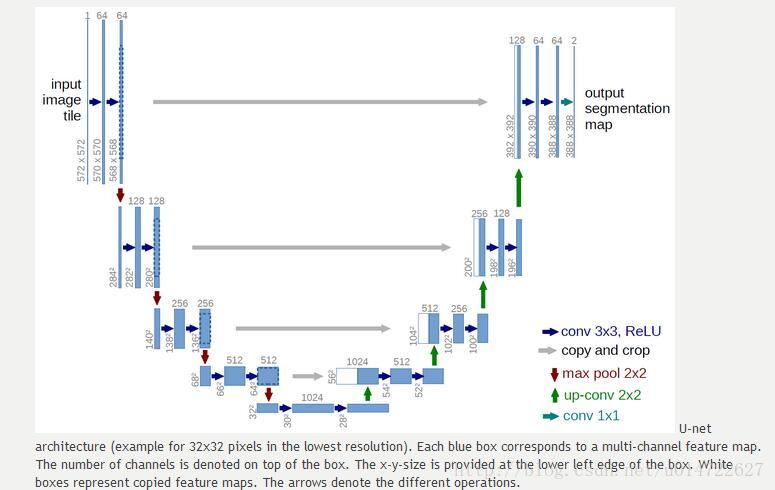
該文章實現了生物影象分割的一個網路,2015年的模型,好像是該領域的冠軍。模型長得像個巨大的U,故取名Unet,之前很火的動漫線稿自動上色 2就是用的這個模型。當然,該模型也許比不上現在的各種生成式模型了,不過拿來在pytorch裡練練手,當做boundary提取,還是可以的。注意這個網路的輸出size與輸入size不一致,所以應用起來需要額外的處理。
模型長這個鬼樣:
參考pytorch的tutorial程式碼,實現如下:
#unet.py:
from __future__ import division
import torch.nn as nn
import torch.nn.functional as F
import torch
from numpy.linalg import svd
from numpy.random import - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
訓練集。。因為沒找到原先的庫,就先用著BSDS500了。。。這裡的BSD500是我上一篇博文處理過的那樣的
但是由於訓練集很少,可以做隨機中心裁剪和隨機水平翻轉的資料增廣, 注意在torchvision.transforms這個包裡,不支援對多幅輸入影象做相同的裁剪操作,所以把這個增廣的步驟放到train.py了
#BSDDataLoader.py
#這裡主要是想說明pytorch的訓練集load操作,簡直傻瓜式操作!媽媽再也不用擔心我的預處理了!
from os.path import exists, join
from torchvision.transforms import Compose, CenterCrop, ToTensor, Scale
import torch.utils.data as data
from os import listdir
from PIL import Image
def bsd500(dest="/dir/to/dataset"):#自行修改路徑!!
if not exists(dest):
print("dataset not exist ")
return dest
def input_transform(crop_size):
return Compose([
CenterCrop(crop_size),
ToTensor()
])
def get_training_set(size, target_mode='seg', colordim=1):
root_dir = bsd500()
train_dir = join(root_dir, "train")
return DatasetFromFolder(train_dir,target_mode,colordim,
input_transform=input_transform(size),
target_transform=input_transform(size))
def get_test_set(size, target_mode='seg', colordim=1):
root_dir = bsd500()
test_dir = join(root_dir, "test")
return DatasetFromFolder(test_dir,target_mode,colordim,
input_transform=input_transform(size),
target_transform=input_transform(size))
def is_image_file(filename):
return any(filename.endswith(extension) for extension in [".png", ".jpg", ".jpeg"])
def load_img(filepath,colordim):
if colordim==1:
img = Image.open(filepath).convert('L')
else:
img = Image.open(filepath).convert('RGB')
#y, _, _ = img.split()
return img
class DatasetFromFolder(data.Dataset):
def __init__(self, image_dir, target_mode, colordim, input_transform=None, target_transform=None):
super(DatasetFromFolder, self).__init__()
self.image_filenames = [x for x in listdir( join(image_dir,'data') ) if is_image_file(x)]
self.input_transform = input_transform
self.target_transform = target_transform
self.image_dir = image_dir
self.target_mode = target_mode
self.colordim = colordim
def __getitem__(self, index):
input = load_img(join(self.image_dir,'data',self.image_filenames[index]),self.colordim)
if self.target_mode=='seg':
target = load_img(join(self.image_dir,'seg',self.image_filenames[index]),1)
else:
target = load_img(join(self.image_dir,'bon',self.image_filenames[index]),1)
if self.input_transform:
input = self.input_transform(input)
if self.target_transform:
target = self.target_transform(target)
return input, target
def __len__(self):
return len(self.image_filenames)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
#train.py
'''
因為原文中網路的input和output size不一樣,不知道他是怎麼搞的loss
簡單起見,我就將groundtruth中心crop到和output一樣大,然後求MSE loss了
結果還是收斂的,做過增廣的資料用於訓練,得到的測試集loss要大一點,因為訓練時的尺度不一樣,估計影響了泛化效果
'''
from __future__ import print_function
from math import log10
import numpy as np
import random
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from unet import UNet
from BSDDataLoader import get_training_set,get_test_set
import torchvision
# Training settings
class option:
def __init__(self):
self.cuda = True #use cuda?
self.batchSize = 4 #training batch size
self.testBatchSize = 4 #testing batch size
self.nEpochs = 140 #umber of epochs to train for
self.lr = 0.001 #Learning Rate. Default=0.01
self.threads = 4 #number of threads for data loader to use
self.seed = 123 #random seed to use. Default=123
self.size = 428
self.remsize = 20
self.colordim = 1
self.target_mode = 'bon'
self.pretrain_net = "/home/wcd/PytorchProject/Unet/unetdata/checkpoint/model_epoch_140.pth"
def map01(tensor,eps=1e-5):
#input/output:tensor
max = np.max(tensor.numpy(), axis=(1,2,3), keepdims=True)
min = np.min(tensor.numpy(), axis=(1,2,3), keepdims=True)
if (max-min).any():
return torch.from_numpy( (tensor.numpy() - min) / (max-min + eps) )
else:
return torch.from_numpy( (tensor.numpy() - min) / (max-min) )
def sizeIsValid(size):
for i in range(4):
size -= 4
if size%2:
return 0
else:
size /= 2
for i in range(4):
size -= 4
size *= 2
return size-4
opt = option()
target_size = sizeIsValid(opt.size)
print("outputsize is: "+str(target_size))
if not target_size:
raise Exception("input size invalid")
target_gap = (opt.size - target_size)//2
cuda = opt.cuda
if cuda and not torch.cuda.is_available():
raise Exception("No GPU found, please run without --cuda")
torch.manual_seed(opt.seed)
if cuda:
torch.cuda.manual_seed(opt.seed)
print('===> Loading datasets')
train_set = get_training_set(opt.size + opt.remsize, target_mode=opt.target_mode, colordim=opt.colordim)
test_set = get_test_set(opt.size, target_mode=opt.target_mode, colordim=opt.colordim)
training_data_loader = DataLoader(dataset=train_set, num_workers=opt.threads, batch_size=opt.batchSize, shuffle=True)
testing_data_loader = DataLoader(dataset=test_set, num_workers=opt.threads, batch_size=opt.testBatchSize, shuffle=False)
print('===> Building unet')
unet = UNet(opt.colordim)
criterion = nn.MSELoss()
if cuda:
unet = unet.cuda()
criterion = criterion.cuda()
pretrained = True
if pretrained:
unet.load_state_dict(torch.load(opt.pretrain_net))
optimizer = optim.SGD(unet.parameters(), lr=opt.lr)
print('===> Training unet')
def train(epoch):
epoch_loss = 0
for iteration, batch in enumerate(training_data_loader, 1):
randH = random.randint(0, opt.remsize)
randW = random.randint(0, opt.remsize)
input = Variable(batch[0][:, :, randH:randH + opt.size, randW:randW + opt.size])
target = Variable(batch[1][:, :,
randH + target_gap:randH + target_gap + target_size,
randW + target_gap:randW + target_gap + target_size])
#target =target.squeeze(1)
#print(target.data.size())
if cuda:
input = input.cuda()
target = target.cuda()
input = unet(input)
#print(input.data.size())
loss = criterion( input, target)
epoch_loss += loss.data[0]
loss.backward()
optimizer.step()
if iteration%10 is 0:
print("===> Epoch[{}]({}/{}): Loss: {:.4f}".format(epoch, iteration, len(training_data_loader), loss.data[0]))
imgout = input.data/2 +1
torchvision.utils.save_image(imgout,"/home/wcd/PytorchProject/Unet/unetdata/checkpoint/epch_"+str(epoch)+'.jpg')
print("===> Epoch {} Complete: Avg. Loss: {:.4f}".format(epoch, epoch_loss / len(training_data_loader)))
def test():
totalloss = 0
for batch in testing_data_loader:
input = Variable(batch[0],volatile=True)
target = Variable(batch[1][:, :,
target_gap:target_gap + target_size,
target_gap:target_gap + target_size],
volatile=True)
#target =target.long().squeeze(1)
if cuda:
input = input.cuda()
target = target.cuda()
optimizer.zero_grad()
prediction = unet(input)
loss = criterion(prediction, target)
totalloss += loss.data[0]
print("===> Avg. test loss: {:.4f} dB".format(totalloss / len(testing_data_loader)))
def checkpoint(epoch):
model_out_path = "/home/wcd/PytorchProject/Unet/unetdata/checkpoint/model_epoch_{}.pth".format(epoch)
torch.save(unet.state_dict(), model_out_path)
print("Checkpoint saved to {}".format(model_out_path))
for epoch in range(141, 141+opt.nEpochs + 1):
train(epoch)
if epoch%10 is 0:
checkpoint(epoch)
test()
checkpoint(epoch)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
如果想要看看網路的結構 還可以這樣
from graphviz import Digraph
from torch.autograd import Variable
from unet import UNet
def make_dot