
常用的幾種神經網路
原文連結
Feed forward neural networks (FF or FFNN) and perceptrons(P)
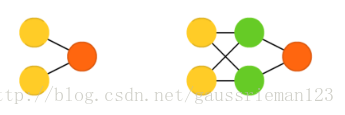
前向反饋網路和感知器是直線向前的,資訊從前向後(分別是輸入和輸出)傳播。神經網路通常被描述成多層,其中每一層都由輸入、隱藏層、輸出單元構成。一層單一網路內部絕對不會有任何連線而通常在相鄰的層之間,神經元是完全相連的(每層的每個神經元都與另外一層的每個神經元相連線)。最簡單某種程度上也是最實用的網路由兩個輸入單元和一個輸出單元,這種網路可以被用作邏輯閘模型。通常FFNNs是通過向後傳播訓練的,給網路成組的資料集包括“輸入”和“預想的輸出”。這種方式稱為有監督學習,與無監督學習相反。誤差被向後傳播,而誤差可以通過MSE或者線性誤差來度量。假設網路由足夠多的隱藏神經元,它理論上來說總是可以模擬輸入和輸出之間的關係的。實際上這種網路本身用途很首先,但是它們通常和別的網絡合並來生成其他型別的網路。
Hopfield network(HN)

霍普菲爾網路的每個神經元都與其他神經元相連線;它是一碗完全糾纏在一起的義大利麵。每個節點在訓練前都是輸入點,然後訓練中都是隱藏節點,訓練結束後又是輸出節點。這些網路會設定神經元的值為所需要的模式,然後計算全職,通過這種方法來訓練模型。在這之後權重不會再改變。一旦訓練成一種或多種模式,網路會一直收斂到一種學習好的模式,因為網路只有在這些狀態下才是穩定的。注意到它不會一直符合所要的狀態。它能夠部分穩定是因為全域性的“能量”或“溫度”在訓練中是逐步減少的。
Convolutional neural networks (CNN or DCNN)
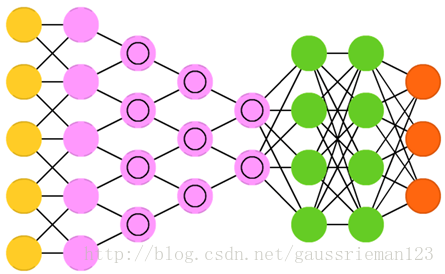
卷積神經網路和大多數其他型別的網路都很不相同。他們最初用來做影象處理,後來也用在其他型別的輸入資料比如音訊。一個典型的CNN應用是,當你給網路輸入影象,網路會對資料進行分類,例如如果你輸入的是貓的照片,它會給出標籤“貓”。CNN通常以一個輸入“掃描器”開始,而它並不會在理科解析所有的訓練資料。舉例來說,輸入一個200*200畫素的影象,你肯定不想要有40000節點的一層。相反,你建立一個掃描輸入層比如20*20,把大影象左上角的20*20畫素進行掃描。一旦前20*20經過處理,逐畫素向右移動這個掃描器來掃描所有的剩餘影象。注意到,我們並沒有把處理過的20*20畫素挪開,也沒有把影象分成20*20的小塊,而是使用這個20*20的掃描器對所有畫素進行掃描。輸入資料然後進行卷積層而不是普通曾,意味著不是所有的節點都和其他節點相連線。每個節點都只和她最近的節點相連(遠近取決於具體的實現,但通常不會很多)。這些卷積層也傾向於變小當它們越老越深的時候,通常是輸入大小最容易整除的因子(如20可能變成10,然後5)。2的冪在這裡會經常被使用,因為它們能夠很完全的分離:32,16,8,4,2,1。除了這些卷積層,通常還有特徵池化層。池化是一種濾出細節部分的方法:最常用的池化技術是極大值池化,比如我們對2*2的畫素,返回其R值最大的畫素。對音訊使用CNN,我們只需要輸入音訊波,然後一點一點增加長度。實際中對CNN的使用通常在末端增加一個FFNN用來深入處理資料,通常要能處理高度非線性抽象分類問題。CNN+FFNN這種網路通常稱為DCNN,但是DCNN和CNN的名稱和縮寫通常可以互相代替。
Deconvolutional networks (DN)
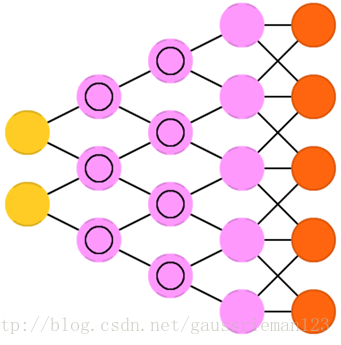
去卷積神經網路,也稱作逆圖形網路,是卷積神經網路的逆過程。對該網路輸入單詞“貓”,網路通過比較它生成的圖片和真是貓圖片,輸出它認為滿足輸入條件貓的圖片。DNN可以和FFNN結合一起使用。
Generative adversarialnetworks (GAN)
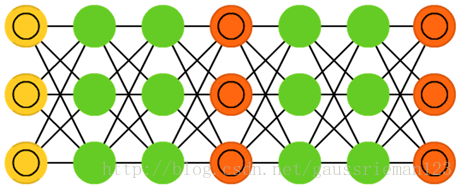
生成對抗網路是一種不同的網路,他們是雙胞胎:兩個網路一起工作。對抗生成網路有任何兩個網路組成(通常是FF和CNN的組合),其中一個負責生成內容另一個要判斷內容。判別網路要麼接受訓練資料,要麼接受生成網路生成的資料作為輸入。判別網路的預測精度被當做生成網路的誤差的一部分。這樣產生一組對抗,當判別網路能越來越精細的判別生成資料和真實資料,生成網路也會生成越來越難以預測的資料。這種方式在某種程度上能很好的執行時因為再複雜的帶噪聲的模式最終都是可預測的,但是和輸入資料有相似特徵的生成資料卻很難學習判別。對抗生成網路非常難訓練,因為我們不僅僅是訓練兩個網路(每一個都有他們各自的問題),而且要處理他們之間的動態平衡關係。如果預測或生成網路比另一個網路好,那麼對抗生成網路將不會收斂,因為本質上這兩個網路就存在著分歧。
Recurrent neural networks(RNN)
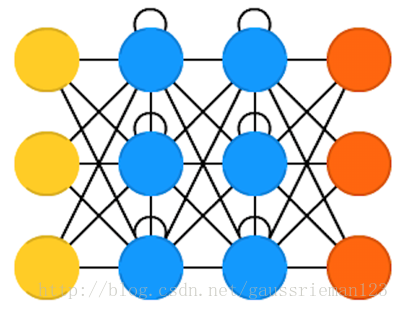
週期神經網路是帶時間週期的FFNN:他們不是無狀態的;他們在時間上有相關性。神經元不僅從輸入接收資訊,而且還要接收他們自身前一個週期點的資訊。這意味著,我們輸入和訓練網路的過程是很重要的:先輸入“牛奶”後“餅乾”與先“餅乾”後“牛奶”,可能會產生不同的結果。RNN一個重要的問題是退化(或爆炸式)梯度問題,依賴於啟用函式的使用,資訊隨著時間快速損失,就像非常深的FFNN隨著深度的增加損失資訊一樣。直觀上這不會帶來很大問題因為他們僅僅是權重而不是神經元狀態,但是帶時間的權重實際上就是儲存資訊的地方;如果權重取值為0或者1 000 000,之前的狀態就沒多大用處了。RNN原則上訥訥夠在很多領域使用,儘管大多數資料形式實際上都沒有時間線(比如 不想聲音和視訊),但是它們都可以被表示成序列。一副圖片或一串文字可以看做在每個時間點上一個畫素或者一個字元,所以依賴時間的權重是在序列中某個之前出現的值上使用,而不是實際上多少秒之前發生的。通常,週期性網路對於演進或補全資訊非常有效,比如自動補全。