
27種神經網路模型的簡介

【1】Perceptron§ 感知機
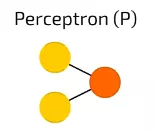
感知機是我們知道的最簡單和最古老的神經元模型,它接收一些輸入,然後把它們加總,通過啟用函式並傳遞到輸出層。
【2】Feed Forward(FF)前饋神經網路
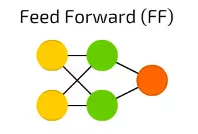
前饋神經網路(FF),這也是一個很古老的方法——這種方法起源於50年代。它的工作原理通常遵循以下規則:
1.所有節點都完全連線
2.啟用從輸入層流向輸出,無迴環
3.輸入和輸出之間有一層(隱含層)
在大多數情況下,這種型別的網路使用反向傳播方法進行訓練。
【3】Radial Basis Network(RBF) RBF神經網路
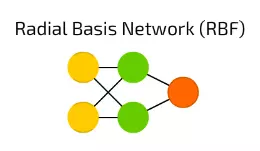
RBF 神經網路實際上是啟用函式是徑向基函式而非邏輯函式的FF前饋神經網路(FF)。兩者之間有什麼區別呢?
邏輯函式—將某個任意值對映到[0 ,… 1]範圍內來,回答“是或否”問題。適用於分類決策系統,但不適用於連續變數。
相反,徑向基函式—能顯示“我們距離目標有多遠”。 這完美適用於函式逼近和機器控制(例如作為PID控制器的替代)。
簡而言之,RBF神經網路其實就是,具有不同啟用函式和應用方向的前饋網路。
【4】Deep Feed Forword(DFF)深度前饋神經網路
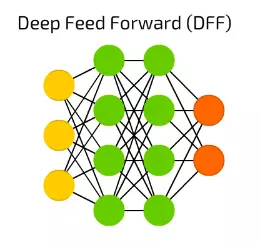
DFF深度前饋神經網路在90年代初期開啟了深度學習的潘多拉盒子。這些依然是前饋神經網路,但有不止一個隱含層。那麼,它到底有什麼特殊性?
在訓練傳統的前饋神經網路時,我們只向上一層傳遞了少量的誤差資訊。由於堆疊更多的層次導致訓練時間的指數增長,使得深度前饋神經網路非常不實用。直到00年代初,我們開發了一系列有效的訓練深度前饋神經網路的方法; 現在它們構成了現代機器學習系統的核心,能實現前饋神經網路的功能,但效果遠高於此。
【5】Recurrent Neural Network(RNN) 遞迴神經網路
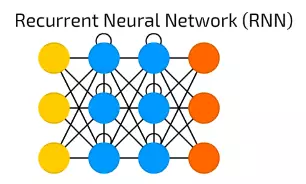
RNN遞迴神經網路引入不同型別的神經元——遞迴神經元。這種型別的第一個網路被稱為約旦網路(Jordan Network),在網路中每個隱含神經元會收到它自己的在固定延遲(一次或多次迭代)後的輸出。除此之外,它與普通的模糊神經網路非常相似。
當然,它有許多變化 — 如傳遞狀態到輸入節點,可變延遲等,但主要思想保持不變。這種型別的神經網路主要被使用在上下文很重要的時候——即過去的迭代結果和樣本產生的決策會對當前產生影響。最常見的上下文的例子是文字——一個單詞只能在前面的單詞或句子的上下文中進行分析。
【6】Long/Short Term Memory (LSTM) 長短時記憶網路
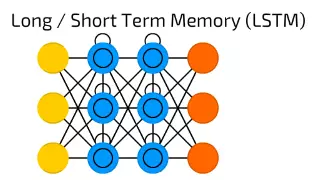
LSTM長短時記憶網路引入了一個儲存單元,一個特殊的單元,當資料有時間間隔(或滯後)時可以處理資料。遞迴神經網路可以通過“記住”前十個詞來處理文字,LSTM長短時記憶網路可以通過“記住”許多幀之前發生的事情處理視訊幀。 LSTM網路也廣泛用於寫作和語音識別。
儲存單元實際上由一些元素組成,稱為門,它們是遞迴性的,並控制資訊如何被記住和遺忘。
【7】Gated Recurrent Unit (GRU)
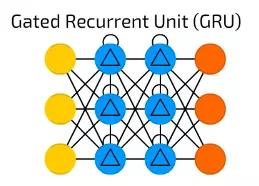
GRU是具有不同門的LSTM。
聽起來很簡單,但缺少輸出門可以更容易基於具體輸入重複多次相同的輸出,目前此模型在聲音(音樂)和語音合成中使用得最多。
實際上的組合雖然有點不同:但是所有的LSTM門都被組合成所謂的更新門(Update Gate),並且復位門(Reset Gate)與輸入密切相關。
它們比LSTM消耗資源少,但幾乎有相同的效果。
【8】Auto Encoder (AE) 自動編碼器
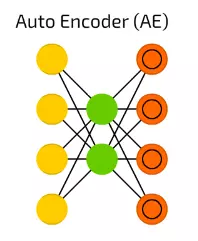
Autoencoders自動編碼器用於分類,聚類和特徵壓縮。
當您訓練前饋(FF)神經網路進行分類時,您主要必須在Y類別中提供X個示例,並且期望Y個輸出單元格中的一個被啟用。 這被稱為“監督學習”。
另一方面,自動編碼器可以在沒有監督的情況下進行訓練。它們的結構 - 當隱藏單元數量小於輸入單元數量(並且輸出單元數量等於輸入單元數)時,並且當自動編碼器被訓練時輸出儘可能接近輸入的方式,強制自動編碼器泛化資料並搜尋常見模式。
【9】Variational AE (VAE) 變分自編碼器

變分自編碼器,與一般自編碼器相比,它壓縮的是概率,而不是特徵。
儘管如此簡單的改變,但是一般自編碼器只能回答當“我們如何歸納資料?”的問題時,變分自編碼器回答了“兩件事情之間的聯絡有多強大?我們應該在兩件事情之間分配誤差還是它們完全獨立的?”的問題。
【10】Denoising AE (DAE) 降噪自動編碼器
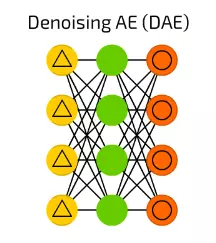
雖然自動編碼器很酷,但它們有時找不到最魯棒的特徵,而只是適應輸入資料(實際上是過擬合的一個例子)。
降噪自動編碼器(DAE)在輸入單元上增加了一些噪聲 - 通過隨機位來改變資料,隨機切換輸入中的位,等等。通過這樣做,一個強制降噪自動編碼器從一個有點嘈雜的輸入重構輸出,使其更加通用,強制選擇更常見的特徵。
【11】Sparse AE (SAE) 稀疏自編碼器
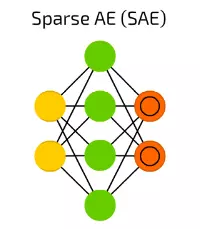
稀疏自編碼器(SAE)是另外一個有時候可以抽離出資料中一些隱藏分組樣試的自動編碼的形式。結構和AE是一樣的,但隱藏單元的數量大於輸入或輸出單元的數量。
【12】Markov Chain (MC) 馬爾科夫鏈
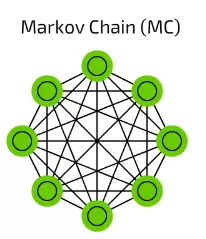
馬爾可夫鏈(Markov Chain, MC)是一個比較老的圖表概念了,它的每一個端點都存在一種可能性。過去,我們用它來搭建像“在單詞hello之後有0.0053%的概率會出現dear,有0.03551%的概率出現you”這樣的文字結構。
這些馬爾科夫鏈並不是典型的神經網路,它可以被用作基於概率的分類(像貝葉斯過濾),用於聚類(對某些類別而言),也被用作有限狀態機。
【13】Hopfield Network (HN) 霍普菲爾網路
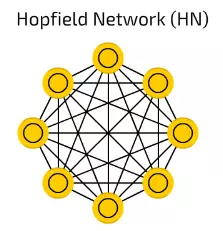
霍普菲爾網路(HN)對一套有限的樣本進行訓練,所以它們用相同的樣本對已知樣本作出反應。
在訓練前,每一個樣本都作為輸入樣本,在訓練之中作為隱藏樣本,使用過之後被用作輸出樣本。
在HN試著重構受訓樣本的時候,他們可以用於給輸入值降噪和修復輸入。如果給出一半圖片或數列用來學習,它們可以反饋全部樣本。
【14】Boltzmann Machine (BM) 波爾滋曼機
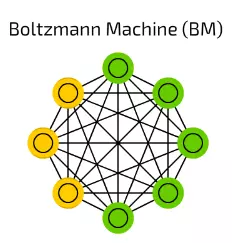
波爾滋曼機(BM)和HN非常相像,有些單元被標記為輸入同時也是隱藏單元。在隱藏單元更新其狀態時,輸入單元就變成了輸出單元。(在訓練時,BM和HN一個一個的更新單元,而非並行)。
這是第一個成功保留模擬退火方法的網路拓撲。
多層疊的波爾滋曼機可以用於所謂的深度信念網路,深度信念網路可以用作特徵檢測和抽取。
【15】Restricted BM (RBM) 限制型波爾滋曼機
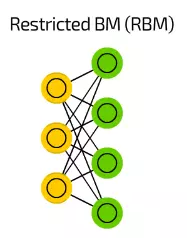
在結構上,限制型波爾滋曼機(RBM)和BM很相似,但由於受限RBM被允許像FF一樣用反向傳播來訓練(唯一的不同的是在反向傳播經過資料之前RBM會經過一次輸入層)。
【16】Deep Belief Network (DBN) 深度信念網路

像之前提到的那樣,深度信念網路(DBN)實際上是許多波爾滋曼機(被VAE包圍)。他們能被連在一起(在一個神經網路訓練另一個的時候),並且可以用已經學習過的樣式來生成資料。
【17】Deep Convolutional Network (DCN) 深度卷積網路
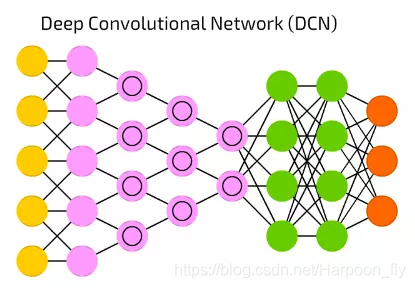
當今,深度卷積網路(DCN)是人工神經網路之星。它具有卷積單元(或者池化層)和核心,每一種都用以不同目的。
卷積核事實上用來處理輸入的資料,池化層是用來簡化它們(大多數情況是用非線性方程,比如max),來減少不必要的特徵。
他們通常被用來做影象識別,它們在圖片的一小部分上執行(大約20x20畫素)。輸入視窗一個畫素一個畫素的沿著影象滑動。然後資料流向卷積層,卷積層形成一個漏斗(壓縮被識別的特徵)。從影象識別來講,第一層識別梯度,第二層識別線,第三層識別形狀,以此類推,直到特定的物體那一級。DFF通常被接在卷積層的末端方便未來的資料處理。
【18】Deconvolutional Network (DN) 去卷積網路
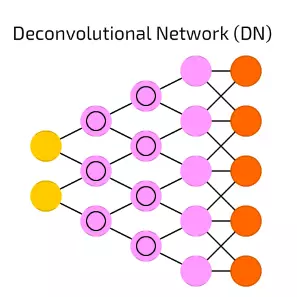
去卷積網路(DN)是將DCN顛倒過來。DN能在獲取貓的圖片之後生成像(狗:0,蜥蜴:0,馬:0,貓:1)一樣的向量。DNC能在得到這個向量之後,能畫出一隻貓。
【19】Deep Convolutional Inverse Graphics Network (DCIGN) 深度卷積反轉影象網路

深度卷積反轉影象網路(DCIGN),長得像DCN和DN粘在一起,但也不完全是這樣。
事實上,它是一個自動編碼器,DCN和DN並不是作為兩個分開的網路,而是承載網路輸入和輸出的間隔區。大多數這種神經網路可以被用作影象處理,並且可以處理他們以前沒有被訓練過的影象。由於其抽象化的水平很高,這些網路可以用於將某個事物從一張圖片中移除,重畫,或者像大名鼎鼎的CycleGAN一樣將一匹馬換成一個斑馬。
【20】Generative Adversarial Network (GAN) 生成對抗網路
生成對抗網路(GAN)代表了有生成器和分辨器組成的雙網路大家族。它們一直在相互傷害——生成器試著生成一些資料,而分辨器接收樣本資料後試著分辨出哪些是樣本,哪些是生成的。只要你能夠保持兩種神經網路訓練之間的平衡,在不斷的進化中,這種神經網路可以生成實際影象。
【21】Liquid State Machine (LSM) 液體狀態機
液體狀態機(LSM)是一種稀疏的,啟用函式被閾值代替了的(並不是全部相連的)神經網路。只有達到閾值的時候,單元格從連續的樣本和釋放出來的輸出中積累價值資訊,並再次將內部的副本設為零。
這種想法來自於人腦,這些神經網路被廣泛的應用於計算機視覺,語音識別系統,但目前還沒有重大突破。
【22】Extreme Learning Machine (ELM) 極端學習機
極端學習機(ELM)是通過產生稀疏的隨機連線的隱藏層來減少FF網路背後的複雜性。它們需要用到更少計算機的能量,實際的效率很大程度上取決於任務和資料。
【23】Echo State Network (ESN) 回聲狀態網路
回聲狀態網路(ESN)是重複網路的細分種類。資料會經過輸入端,如果被監測到進行了多次迭代(請允許重複網路的特徵亂入一下),只有在隱藏層之間的權重會在此之後更新。
據我所知,除了多個理論基準之外,我不知道這種型別的有什麼實際應用。。。。。。。
【24】Deep Residual Network (DRN) 深度殘差網路
深度殘差網路(DRN)是有些輸入值的部分會傳遞到下一層。這一特點可以讓它可以做到很深的層級(達到300層),但事實上它們是一種沒有明確延時的RNN。
【25】Kohonen Network (KN) Kohonen神經網路
Kohonen神經網路(KN)引入了“單元格距離”的特徵。大多數情況下用於分類,這種網路試著調整它們的單元格使其對某種特定的輸入作出最可能的反應。當一些單元格更新了, 離他們最近的單元格也會更新。
像SVM一樣,這些網路總被認為不是“真正”的神經網路。
【26】Support Vector Machine (SVM)
支援向量機(SVM)用於二元分類工作,無論這個網路處理多少維度或輸入,結果都會是“是”或“否”。
SVM不是所有情況下都被叫做神經網路。
【27】Neural Turing Machine (NTM) 神經圖靈機
神經網路像是黑箱——我們可以訓練它們,得到結果,增強它們,但實際的決定路徑大多數我們都是不可見的。
神經圖靈機(NTM)就是在嘗試解決這個問題——它是一個提取出記憶單元之後的FF。一些作者也說它是一個抽象版的LSTM。
記憶是被內容編址的,這個網路可以基於現狀讀取記憶,編寫記憶,也代表了圖靈完備神經網路。