
幾種輕量級網路理解——Squeezenet、Mobilenet、Shufflenet、IGCV、Densenet
1、SqueezeNet:AlexNet-level accuracy with 50x fewer parameters and <0.5MB
發表於ICLR-2016,作者分別來自Berkeley和Stanford
結論:它在ImageNet上實現了和AlexNet相同的正確率,但是隻使用了1/50的引數。更進一步,使用模型壓縮技術,可以將SqueezeNet壓縮到0.5MB,這是AlexNet的1/510。
創新點:fire module(類似於inception思想)。fire module包含兩部分:squeeze層+expand層。squeeze層通過1*1的卷積核減少輸入通道的數量;expand層中,把1*1 和3*3 得到的feature map進行concat,以得到不同尺寸的卷積特徵,如下圖1、2所示。圖2中,必須保證S1<e1+e3。
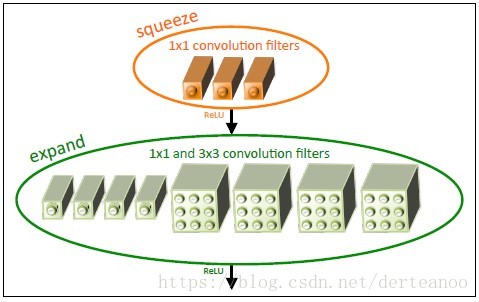
圖1

圖2
2、(1)mobilenet-v1:MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Applications
來自CVPR2017,由Google團隊提出
論文連結:https://arxiv.org/pdf/1704.04861.pdf
程式碼連結:https://github.com/Zehaos/MobileNet
創新點:假設輸入為Df*Df*M,卷積核為Dk*Dk*N,傳統卷積計算量為Df*Df*M*Dk*Dk*N。mobilenet採用深度可分離卷積(depthwise separable concolution),將其分為深度卷積和1*1的卷積,深度卷積的卷積核個數與輸入的通道數相同,1*1卷積核用來改變輸出通道數,計算量分別為Dk*Dk*M*DF*DF和M*N*DF*DF,實現了spatial與channels間的解耦,減少了計算量。

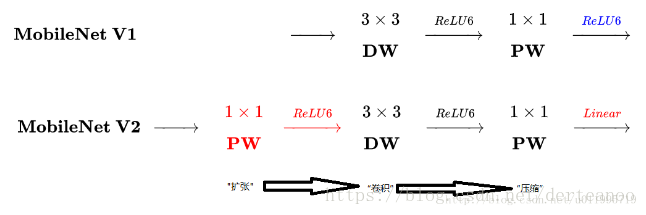
(2)mobilenet-v2:Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation
論文連結:https://arxiv.org/abs/1801.04381
創新點:(1)相比v1卷積層提取的特徵受限於通道數,先用1*1的卷積核擴張通道數,先擴張後壓縮。(2)最後1*1卷積後不再用ReLU,避免ReLU對特徵的破壞。
3、shufflenet:An Extremely Efficient Convolutional Neural Network for Mobile Devices
論文連結:https://arxiv.org/pdf/1707.01083.pdf
https://github.com/farmingyard/ShuffleNet
CVPR 2017, Face ++ 團隊
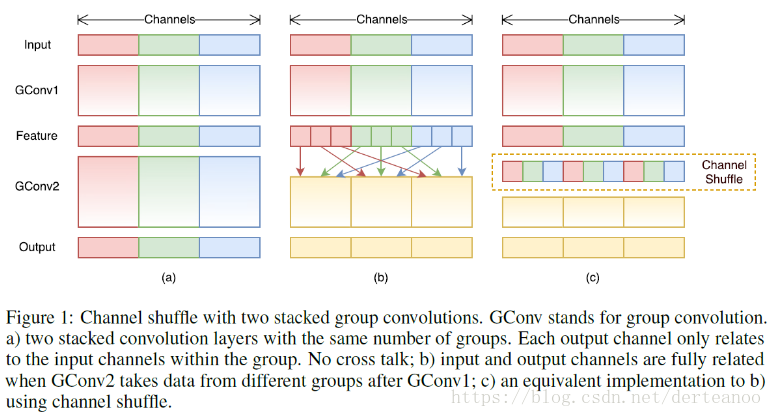
創新點:(1)pointwise group convolutions(逐點組卷積),作者認為1*1卷積的計算量不可忽略,所以用1*1的group convolutions代替原先1*1的convolutions。假設feature map數為N,Filter數為M,分成g個group,則每組N/g個feature map與M/g個Filter做卷積。(2) channel shuffle(通道混洗),每個輸出channel都來自輸入channel的一小部分,特徵會很侷限,因此採用混洗策略。
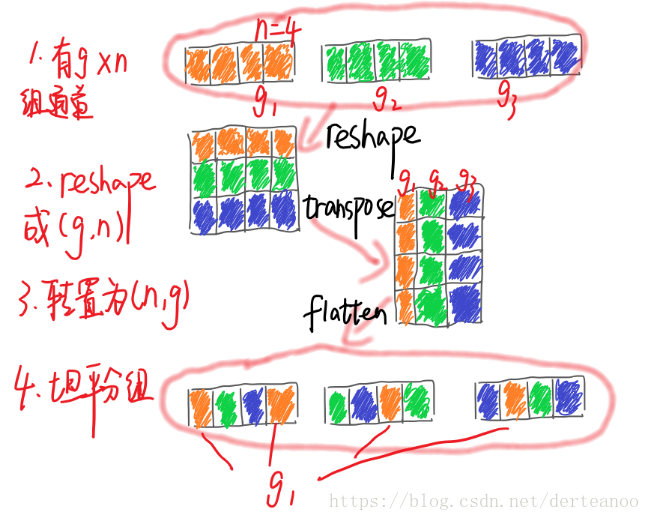
混洗的具體實現:(1)分成g個group,輸出為g*n;(2)reshape成(g,n);(3)轉置成(n,g);(4)flatten,分回g個group作為下一層輸入。如圖所示:
如下圖,採用channel shuffle、pointwise group convolutions和depthwise separable convolution來修改原來的ResNet單元(在輔分支加入步長為2的3*3平均池化;原本做元素相加的操作轉為了通道級聯,這擴大了通道維度,增加的計算成本卻很少)。
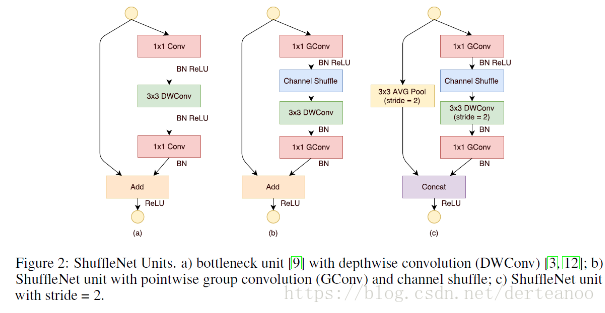
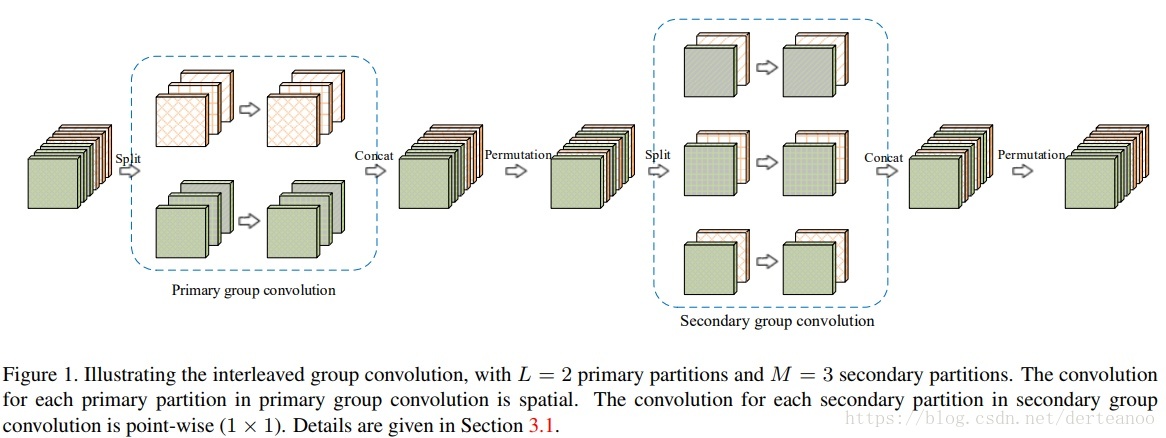
4、(1)IGCV1:Interleaved Group Convolutions For Deep Neural Networks
由微軟亞洲研究院張婷提出,ICCV 2017
論文連結:https://arxiv.org/pdf/1707.02725v2.pdf
結論:(1)組卷積間不存在互動,因此採用兩次組卷積,每組的輸入通道來自第一次組卷積過程中的不同組。結果在準確率、複雜度上均有提升。(2)經過實驗發現,組卷積中每組分配兩個通道的情況會得到最佳的精度。
(2) IGCV2:Interleaved Structured Sparse Convolutional Neural Networks
CVPR2018
論文連結:https://arxiv.org/pdf/1804.06202.pdf
創新點:在IGCV1的模型中第一次組卷積是隻是將所有通道均分成兩組,而每一組仍然是一個非常dense、非常耗時的操作。於是他們用交錯組卷積的方式將這部分也進行替換,得到了IGCV 2,即每層都用交錯組卷積。
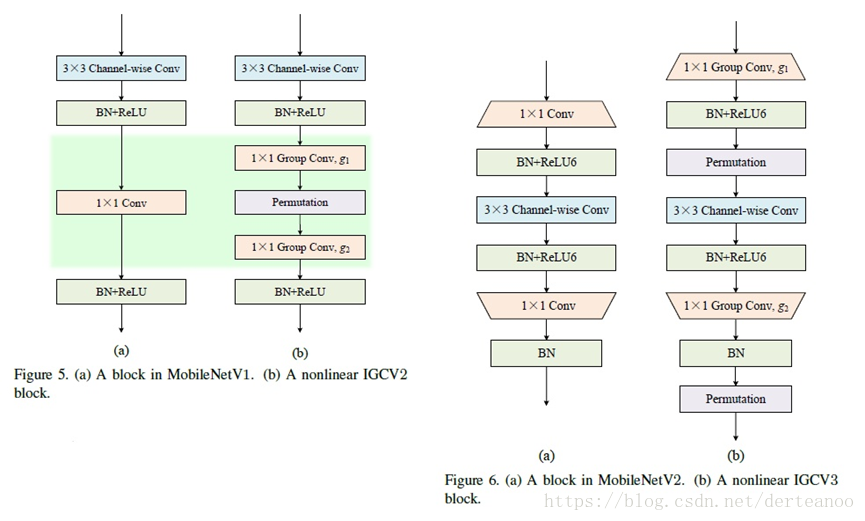
(3)IGCV3:Interleaved Low-Rank Group Convolutions for Efficient Deep Neural Networks
ICCV3 2018
原文連結:https://arxiv.org/abs/1806.00178
程式碼連結(部分,還未釋出):https://github.com/homles11/IGCV3
創新點:(1) 採用低精確度的核,該方法將卷積核內的權重值由浮點型資料,轉變為採用更少bit位表示的資料型別,如採用二進位制表示權重,使得權重值僅為-1或+1,這樣在網路計算時,就減少了儲存空間的使用。

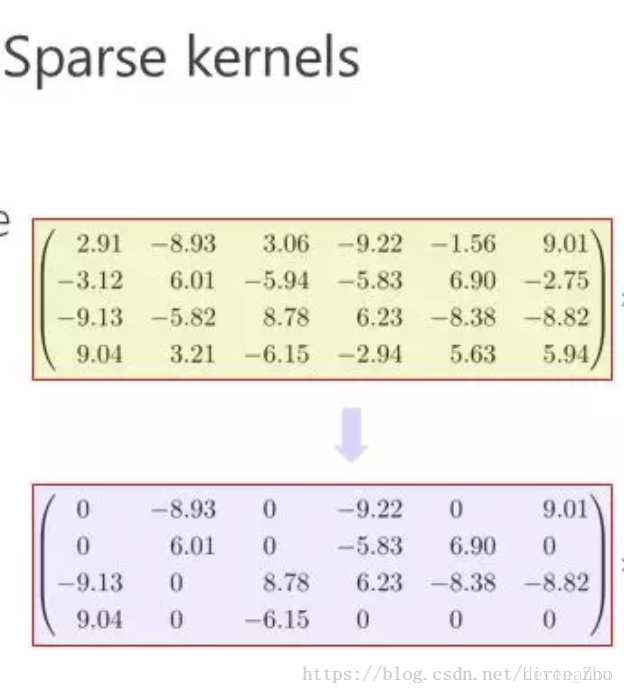
(2)採用稀疏或低秩核。稀疏核主要是通過採用L1或L2正則化來增加核的稀疏性,稀疏核中只有通過將部分權重值設為0,從而減少計算量。

5、Densenet:Densely Connected Convolutional Networks
CVPR 2017最佳論文,作者是康奈爾大學博士後黃高博士、清華大學本科生劉壯、Facebook 人工智慧研究院研究科學家 Laurens van der Maaten 及康奈爾大學計算機系教授 Kilian Q. Weinberger
創新點:(1)採用DenseBlock的結構。如圖,將網路中所有層都連起來,每一層的輸入來自前面所有層的輸出,保證網路中資訊的最大傳遞,和RNN的感覺類似。這樣,一減輕了vanishing-gradient(梯度消失)(梯度消失的原因是由於梯度資訊在很多層之間傳遞所以丟失),二加強了feature的傳遞 ,三更有效地利用了feature ,四每一層的通道數更窄(小於100),一定程度上較少了引數數量,因此過擬合現象也會減輕。
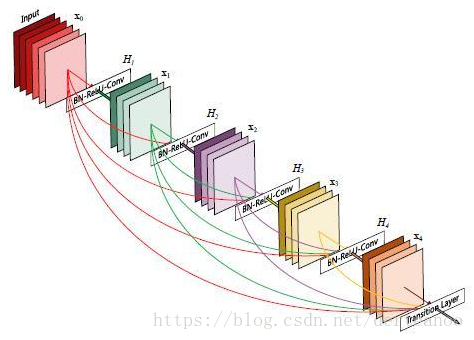
每個Densenet由多個dense block組成,每個dense block的feature map的size一樣,便於concat。

(2)DenseBlock的輸入開始,頻繁使用Bottleneck Layer先進行降維,以減少feature map的層數。在兩個Dense Block中間,使用transition layer,通過設定引數reduction(範圍是0到1),用1*1的卷積核以一定比例進行降維。
(3)Densenet在concat過程會重新開闢記憶體,因此很佔視訊記憶體,可以通過共享記憶體的方式去優化部署。