
極大似然估計的一些學習整理
尊重原創,尊重每個人的成果,所以把參考的博文放在首位:
極大似然估計法:
思想:利用已知的樣本結果,反推最有可能(最大概率)導致這樣結果的引數值!
例子:
設有一批產品,甲認為次品率為0.1,乙認為次品率為0.3,現從產品中隨機抽取15件,發現有5件詞頻,問甲乙誰的估計更準一些?
解:記詞頻數為X,則X~B(n,p)
若次品率 p = 0.1,則15件中有5件次品的概率為:
若次品率p = 0.3,則15件中有5件次品的概率為:
則,後一概率明顯大於前一概率,因此用次品率為0.3的估計值更可靠一些。
前提:訓練樣本的分佈能代表樣本的真實分佈。每個樣本集中的樣本都是所謂獨立同分布的隨機變數 (iid條件),且有充分的訓練樣本。
推導:
由於樣本集中的樣本都是獨立同分布,可以只考慮一類樣本集D,來估計引數向量θ。記已知的樣本集為:
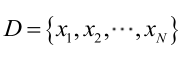
似然函式(linkehood function):聯合概率密度函式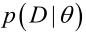
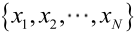
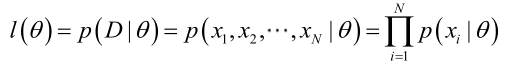
如果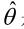
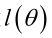

求解極大似然函式
ML估計:求使得出現該組樣本的概率最大的θ值。
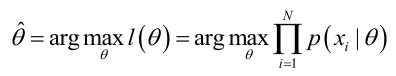
實際中為了便於分析,定義了對數似然函式:
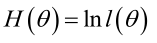
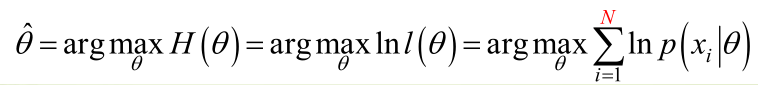
1. 未知引數只有一個(θ為標量)
在似然函式滿足連續、可微的正則條件下,極大似然估計量是下面微分方程的解:
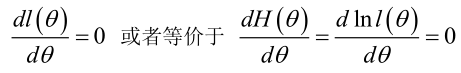
2.未知引數有多個(θ為向量)
則θ可表示為具有S個分量的未知向量:
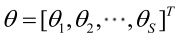
記梯度運算元:
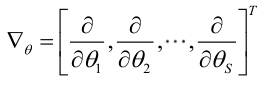
若似然函式滿足連續可導的條件,則最大似然估計量就是如下方程的解。
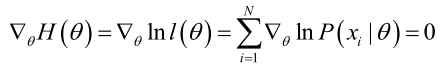
方程的解只是一個估計值,只有在樣本數趨於無限多的時候,它才會接近於真實值。
極大似然估計的例子
例1:設樣本服從正態分佈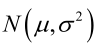
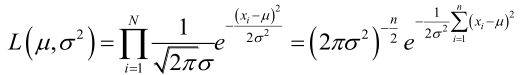
它的對數:
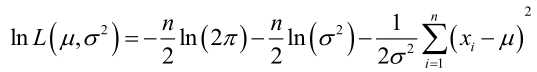
求導,得方程組:
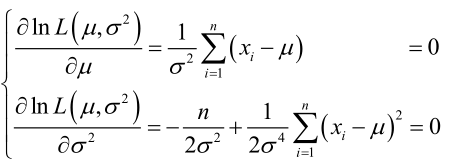
聯合解得:
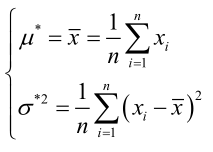
似然方程有唯一解
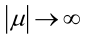 或
或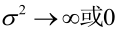 時,非負函式
時,非負函式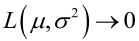 。於是U和
。於是U和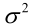 的極大似然估計為
的極大似然估計為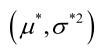 。
。
例2:設樣本服從均勻分佈[a, b]。則X的概率密度函式:
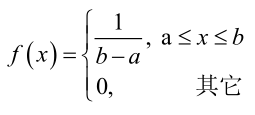
對樣本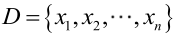
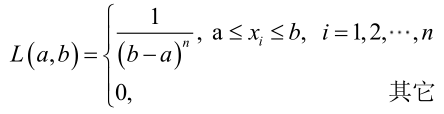
很顯然,L(a,b)作為a和b的二元函式是不連續的,這時不能用導數來求解。而必須從極大似然估計的定義出發,求L(a,b)的最大值,為使L(a,b)達到最大,b-a應該儘可能地小,但b又不能小於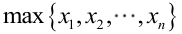
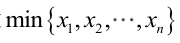
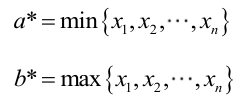
求最大似然估計量
(1)寫出似然函式;
(2)對似然函式取對數;
(3)求導數(偏導);
(4)解似然方程。
最大似然估計的特點:
1.比其他估計方法更加簡單;
2.收斂性:無偏或者漸近無偏,當樣本數目增加時,收斂性質會更好;
3.如果假設的類條件概率模型正確,則通常能獲得較好的結果。但如果假設模型出現偏差,將導致非常差的估計結果。
經典演算法模型例子:
邏輯迴歸原理及公式推導
1.線性迴歸的主要思想是通過歷史資料擬合出一條直線,來進行預測
2.邏輯迴歸是基於線性迴歸,將線性迴歸的值對映到(0,1)上
其中,為sigmoid函式
當 ,x屬於A類
當 ,x屬於B類
概率函式為:
因為樣本資料獨立,所以它們的聯合分佈可以表示為各邊際分佈的乘積,取似然函式為:
取對數似然函式:
最大似然估計就是要求的值最大時的
,這裡可以使用梯度上升法。
因乘了一個負的係數,所以可以用梯度下降求解!