
TLD目標跟蹤原理解析
轉自http://blog.csdn.net/app_12062011/article/details/52277159
TLD(Tracking-Learning-Detection)是英國薩里大學的一個捷克籍博士生在其攻讀博士學位期間提出的一種新的單目標長時間(long term tracking)跟蹤演算法。該演算法與傳統跟蹤演算法的顯著區別在於將傳統的跟蹤演算法和傳統的檢測演算法相結合來解決被跟蹤目標在被跟蹤過程中發生的形變、部分遮擋等問題。同時,通過一種改進的線上學習機制不斷更新跟蹤模組的“顯著特徵點”和檢測模組的目標模型及相關引數,從而使得跟蹤效果更加穩定、魯棒、可靠。
對於長時間跟蹤而言,一個關鍵的問題是:當目標重新出現在相機視野中時,系統應該能重新檢測到它,並開始重新跟蹤。但是,長時間跟蹤過程中,被跟蹤目標將不可避免的發生形狀變化、光照條件變化、尺度變化、遮擋等情況。傳統的跟蹤演算法,前端需要跟檢測模組相互配合,當檢測到被跟蹤目標之後,就開始進入跟蹤模組,而此後,檢測模組就不會介入到跟蹤過程中。但這種方法有一個致命的缺陷:即,當被跟蹤目標存在形狀變化或遮擋時,跟蹤就很容易失敗;因此,對於長時間跟蹤,或者被跟蹤目標存在形狀變化情況下的跟蹤,很多人採用檢測的方法來代替跟蹤。該方法雖然在某些情況下可以改進跟蹤效果,但它需要一個離線的學習過程。即:在檢測之前,需要挑選大量的被跟蹤目標的樣本來進行學習和訓練。這也就意味著,訓練樣本要涵蓋被跟蹤目標可能發生的各種形變和各種尺度、姿態變化和光照變化的情況。換言之,利用檢測的方法來達到長時間跟蹤的目的,對於訓練樣本的選擇至關重要,否則,跟蹤的魯棒性就難以保證。
考慮到單純的跟蹤或者單純的檢測演算法都無法在長時間跟蹤過程中達到理想的效果,所以,TLD方法就考慮將兩者予以結合,並加入一種改進的線上學習機制,從而使得整體的目標跟蹤更加穩定、有效。
簡單來說,TLD演算法由三部分組成:跟蹤模組、檢測模組、學習模組;如下圖所示
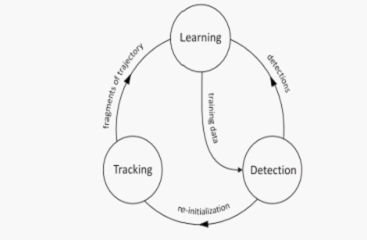
其執行機制為:檢測模組和跟蹤模組互不干涉的並行進行處理。首先,跟蹤模組假設相鄰視訊幀之間物體的運動是有限的,且被跟蹤目標是可見的,以此來估計目標的運動。如果目標在相機視野中消失,將造成跟蹤失敗。檢測模組假設每一個視幀都是彼此獨立的,並且根據以往檢測和學習到的目標模型,對每一幀圖片進行全圖搜尋以定位目標可能出現的區域。同其它目標檢測方法一樣,
在詳細介紹TLD的流程之前,有一些基本知識和基本概念需要予以澄清:
基本知識:
檢測特徵:
檢測部分用到了一種作者稱為Fern的結構,它是在Random Forests的基礎上改進得到的,不妨稱之為Random Fern。
2bitBP(2bit Binary Pattern)
這種特徵是一種類似於harr-like的特徵,這種特徵包括了特徵型別以及相應的特徵取值。
假定現在我們要判斷一個Patch塊是不是我們要檢測的目標。所謂特徵型別,就是指在這個Patch在(x,y)座標,取的一個長width,高height的框子,這個組合(x, y, width, height)就是相應的特徵型別。
下面解釋什麼是特徵的取值。在已經選定了特徵型別的情況下,如果我們把框子左右分成相等的兩部分,分別計算左右兩部分的灰度和,那麼就有兩種情況:(1)左邊灰度大,(2)右邊灰度大,直觀的看,就是左右兩邊哪邊顏色更深。同樣的,把框子分成上下相等的兩部分,也會有兩種情況,直觀地看,就是上下兩邊哪邊顏色更深。於是在分了上下左右後,總共會有4種情況,可以用2bit來描述這4種情況,即可得到相應的特徵取值。這個過程可以參見圖1。
實際上每種型別的特徵都從某個角度來看待我們要跟蹤的物件。比如圖1中的紅框,這個框子中,車燈的地方灰度應該要深一些,那麼紅框這個型別的特徵,實際上就意味著,它認為,如果該Patch是一個車子,在相應的地方,相應的長和高,這個地方顏色也應該深一些。
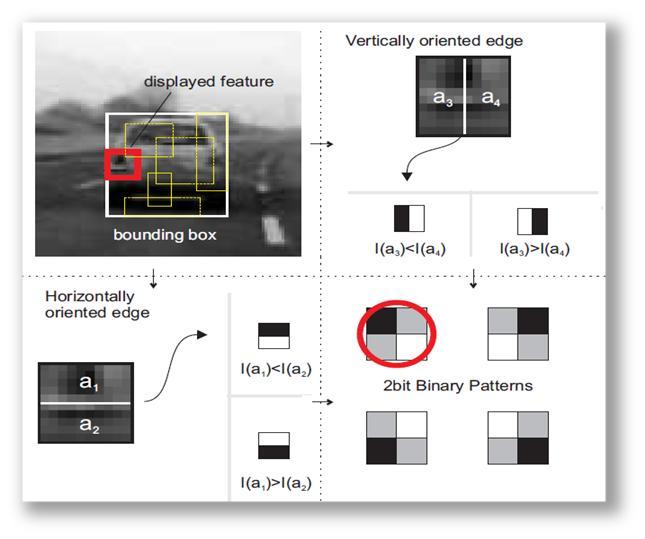
圖1. 2bitBP特徵說明
其實,這跟FAST特徵的本質是一樣的。只是FAST取的是點附近圓範圍內的。這裡只取相鄰一次。
Random Fern
前面已經提及,每種型別的特徵都代表了一種看待跟蹤物件的觀點,那麼是否可以用若干種類型的特徵來進行一個組合,使之更好地描述跟蹤的物件呢?答案是肯定的,還是舉圖1的例子,左邊有一個車燈,右邊也有一個車燈,如果我們把這兩個框子都取到了,可以預見檢測的效果會比只有一個框子來得好。Random Fern的思想就是用多個特徵組合來表達物件。
下面,我們先講一個Fern是怎麼生成和決策的,再講多個Fern的情況下,如何進行統一決策。
不妨假設我們選定了nFeat種類型的特徵來表達物件。每個棵Fern實際上是一棵4叉樹,如圖2所示,選了多少種類型的特徵,這棵4叉樹就有多少層。對於一個Patch,每一層就用相應的型別的特徵去判斷,計算出相應型別特徵的特徵取值,由於採用的是2bitBP特徵,會有4種可能取值,在下一層又進行相同的操作,這樣每個Patch最終會走到最末層的一個葉子節點上。
對於訓練過程,要記錄落到每個葉子結點上的正樣本個數(用nP記),同時也要記錄落到每個葉子結點上的負樣本的個數(用nN記)。則可算出正樣本落到每個葉子結點上的後驗概率nP/(nP+nN)。
對於檢測過程,要檢測的Patch最終會落到某個葉子結點上,由於訓練過程已經記錄了正樣本落到每個葉子結點上的後驗概率,最終可輸出該Patch為正樣本的概率。
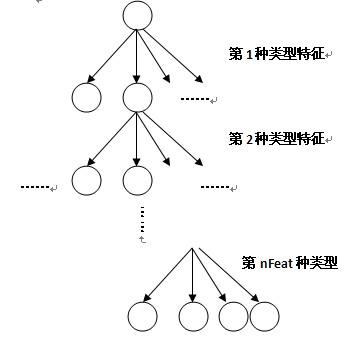
圖2. Fern的結構
這裡Fern二值表示,更像是ORB特徵的簡化版。
前面介紹了一個Fern的生成,以及用Fern檢測一個Patch,並給出它為正樣本的概率。這樣多個Fern進行判斷時,就會給出多個後驗概率。這就好比我們讓多個人來決策,看這個東西是不是正樣本,每個人對應於一個Fern。最終我們計算這一系列的Fern輸出的後驗的均值,看是否大於閾值,從而最終確定它是否是正樣本。
作者巧妙地將隨機森林的思想,與ORB思想,結合起來,形成自己的分類器 。
PN學習
參考:http://blog.csdn.net/carson2005/article/details/7483027
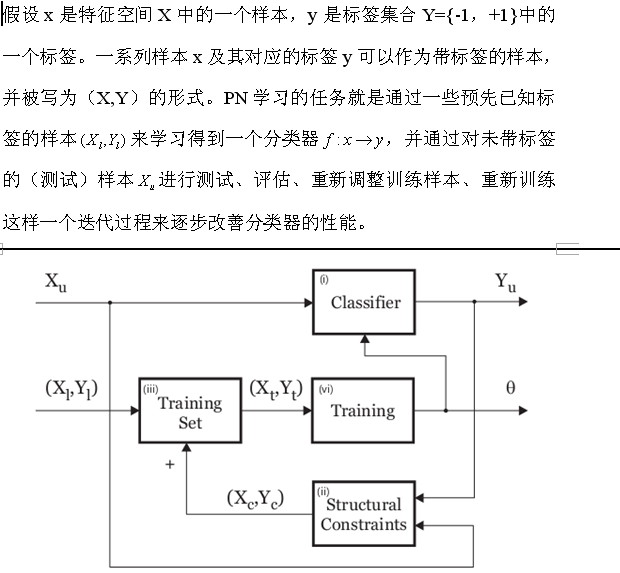
PN學習(PN learning)是一種利用帶標籤的樣本(一般用於分類器訓練,以下均稱之為測試樣本)和不帶標籤的樣本(一般用於分類器測試,以下均稱之為測試樣本)之間存在的結構性特徵(見下面的解釋)來逐步(學習)訓練兩類分類器並改善分類器分類效能的方法。
正約束(Positive constraint)和負約束(negative constraint)用來限制測試樣本的標籤賦值過程,而PN學習正是受正負約束所操控的。PN學習對分類器在測試樣本上的分類結果進行評估,找到那些分類結果與約束條件相矛盾的樣本,重新調整訓練集,並進行重複迭代訓練,直到某個條件滿足,才停止分類器訓練過程。在目標跟蹤過程中,由於被跟蹤目標的形狀、姿態等容易發生變化,造成目標跟丟的情況時有發生,所以,在這種情況下,對被跟蹤目標的線上學習和檢測是個很好的策略。而PN學習正好可以在此處大顯身手。
很多學習演算法都假設測試樣本是彼此獨立的,然而,在計算機視覺的應用中,有些測試樣本的標籤卻存在彼此依賴的關係。標籤之間存在的這種依賴關係,我們稱之為結構性的。例如,在目標檢測過程中,我們的任務是對圖片中目標可能存在的所有區域賦予標籤,即:該區域屬於前景或者背景,而這裡的標籤僅能是前景或背景兩者之一。再比如,在利用視訊序列進行目標跟蹤過程中,緊鄰被跟蹤目標運動軌跡線的區域,可以認為是前景標籤,而遠離軌跡線的區域,可以認為是背景標籤。而前面提到的正約束則表示所有可能的標籤為正的模式,例如,此處的緊鄰軌跡線的區域;負約束表示所有可能的標籤為負的模式。
通過以上的分析,不難發現,PN學習可以定義為一下的過程:
(1)準備一個數量較少的訓練樣本集合和一個數量很大的測試樣本集合。
(2)利用訓練樣本訓練一個初始分類器。同時,利用訓練樣本對(先驗)約束條件進行相應的調整。
(3)利用分類器對測試樣本賦予標籤,並找出分類器賦予的標籤同約束條件相矛盾的那些樣本;
(4)將上述相矛盾的樣本重新賦予標籤,將其加入訓練樣本,重新訓練分類器;
反覆迭代上述過程,直到滿足某個約束條件。


在任意時刻,被跟蹤目標都可以用其狀態屬性來表示。該狀態屬性可以是一個表示目標所在位置、尺度大小的跟蹤框,也可以是一個標識被跟蹤目標是否可見的標記。兩個跟蹤框的空間域相似度是用重疊度(overlap)來度量,其計算方法是兩個跟蹤框的交集與兩者並集的商。目標的形狀採用影象片(image patch,個人認為,可以理解為滑動視窗)p來表示,每一個影象片都是從跟蹤框內部取樣得到的,並被歸一化到15*15的大小。兩個圖相片




以下是原始碼分析:
原文:
http://blog.csdn.net/zouxy09/article/details/7893026
從main()函式切入,分析整個TLD執行過程如下:
(這裡只是分析工作過程,全部註釋的程式碼見部落格的更新)
1、分析程式執行的命令列引數;
./run_tld -p ../parameters.yml -s ../datasets/06_car/car.mpg -b ../datasets/06_car/init.txt –r
2、讀入初始化引數(程式中變數)的檔案parameters.yml;
3、通過檔案或者使用者滑鼠框選的方式指定要跟蹤的目標的Bounding Box;
4、用上面得到的包含要跟蹤目標的Bounding Box和第一幀影象去初始化TLD系統,
tld.init(last_gray, box, bb_file); 初始化包含的工作如下:
4.1、buildGrid(frame1, box);
檢測器採用掃描視窗的策略:掃描視窗步長為寬高的 10%,尺度縮放係數為1.2;此函式構建全部的掃描視窗grid,並計算每一個掃描視窗與輸入的目標box的重疊度;重疊度定義為兩個box的交集與它們的並集的比;
4.2、為各種變數或者容器分配記憶體空間;
4.3、getOverlappingBoxes(box, num_closest_init);
此函式根據傳入的box(目標邊界框),在整幀影象中的全部掃描視窗中(由上面4.1得到)尋找與該box距離最小(即最相似,重疊度最大)的num_closest_init(10)個視窗,然後把這些視窗歸入good_boxes容器。同時,把重疊度小於0.2的,歸入bad_boxes容器;相當於對全部的掃描視窗進行篩選。並通過BBhull函式得到這些掃描視窗的最大邊界。
4.5、classifier.prepare(scales);
準備分類器,scales容器裡是所有掃描視窗的尺度,由上面的buildGrid()函式初始化;
TLD的分類器有三部分:方差分類器模組、集合分類器模組和最近鄰分類器模組;這三個分類器是級聯的,每一個掃描視窗依次全部通過上面三個分類器,才被認為含有前景目標。這裡prepare這個函式主要是初始化集合分類器模組;
集合分類器(隨機森林)基於n個基本分類器(共10棵樹),每個分類器(樹)都是基於一個pixel comparisons(共13個畫素比較集)的,也就是說每棵樹有13個判斷節點(組成一個pixel comparisons),輸入的影象片與每一個判斷節點(相應畫素點)進行比較,產生0或者1,然後將這13個0或者1連成一個13位的二進位制碼x(有2^13種可能),每一個x對應一個後驗概率P(y|x)= #p/(#p+#n) (也有2^13種可能),#p和#n分別是正和負影象片的數目。那麼整一個集合分類器(共10個基本分類器)就有10個後驗概率了,將10個後驗概率進行平均,如果大於閾值(一開始設經驗值0.65,後面再訓練優化)的話,就認為該影象片含有前景目標;
後驗概率P(y|x)= #p/(#p+#n)的產生方法:初始化時,每個後驗概率都得初始化為0;執行時候以下面方式更新:將已知類別標籤的樣本(訓練樣本)通過n個分類器進行分類,如果分類結果錯誤,那麼相應的#p和#n就會更新,這樣P(y|x)也相應更新了。
pixel comparisons的產生方法:先用一個歸一化的patch去離散化畫素空間,產生所有可能的垂直和水平的pixel comparisons,然後我們把這些pixel comparisons隨機分配給n個分類器,每個分類器得到完全不同的pixel comparisons(特徵集合),這樣,所有分類器的特徵組統一起來就可以覆蓋整個patch了。
特徵是相對於一種尺度的矩形框而言的,TLD中第s種尺度的第i個特徵features[s][i] = Feature(x1, y1, x2, y2);是兩個隨機分配的畫素點座標(就是由這兩個畫素點比較得到0或者1的)。每一種尺度的掃描視窗都含有totalFeatures = nstructs * structSize個特徵;nstructs為樹木(由一個特徵組構建,每組特徵代表影象塊的不同視圖表示)的個數;structSize為每棵樹的特徵個數,也即每棵樹的判斷節點個數;樹上每一個特徵都作為一個決策節點;
prepare函式的工作就是先給每一個掃描視窗初始化了對應的pixel comparisons(兩個隨機分配的畫素點座標);然後初始化後驗概率為0;
4.6、generatePositiveData(frame1, num_warps_init);
此函式通過對第一幀影象的目標框box(使用者指定的要跟蹤的目標)進行仿射變換來合成訓練初始分類器的正樣本集。具體方法如下:先在距離初始的目標框最近的掃描視窗內選擇10個bounding box(已經由上面的getOverlappingBoxes函式得到,存於good_boxes裡面了,還記得不?),然後在每個bounding box的內部,進行±1%範圍的偏移,±1%範圍的尺度變化,±10%範圍的平面內旋轉,並且在每個畫素上增加方差為5的高斯噪聲(確切的大小是在指定的範圍內隨機選擇的),那麼每個box都進行20次這種幾何變換,那麼10個box將產生200個仿射變換的bounding box,作為正樣本。具體實現如下:
getPattern(frame(best_box), pEx, mean, stdev);此函式將frame影象best_box區域的影象片歸一化為均值為0的15*15大小的patch,存於pEx(用於最近鄰分類器的正樣本)正樣本中(最近鄰的box的Pattern),該正樣本只有一個。
generator(frame, pt, warped, bbhull.size(), rng);此函式屬於PatchGenerator類的建構函式,用來對影象區域進行仿射變換,先RNG一個隨機因子,再呼叫()運算子產生一個變換後的正樣本。
classifier.getFeatures(patch, grid[idx].sidx, fern);函式得到輸入的patch的特徵fern(13位的二進位制程式碼);
pX.push_back(make_pair(fern, 1)); //positive ferns <features, labels=1>然後標記為正樣本,存入pX(用於集合分類器的正樣本)正樣本庫;
以上的操作會迴圈 num_warps * good_boxes.size()即20 * 10 次,這樣,pEx就有了一個正樣本,而pX有了200個正樣本了;
4.7、meanStdDev(frame1(best_box), mean, stdev);
統計best_box的均值和標準差,var = pow(stdev.val[0],2) * 0.5;作為方差分類器的閾值。
4.8、generateNegativeData(frame1);
由於TLD僅跟蹤一個目標,所以我們確定了目標框了,故除目標框外的其他影象都是負樣本,無需仿射變換;具體實現如下:
由於之前重疊度小於0.2的,都歸入 bad_boxes了,所以數量挺多,把方差大於var*0.5f的bad_boxes都加入負樣本,同上面一樣,需要classifier.getFeatures(patch, grid[idx].sidx, fern);和nX.push_back(make_pair(fern, 0));得到對應的fern特徵和標籤的nX負樣本(用於集合分類器的負樣本);
然後隨機在上面的bad_boxes中取bad_patches(100個)個box,然後用 getPattern函式將frame影象bad_box區域的影象片歸一化到15*15大小的patch,存在nEx(用於最近鄰分類器的負樣本)負樣本中。
這樣nEx和nX都有負樣本了;(box的方差通過積分影象計算)
4.9、然後將nEx的一半作為訓練集nEx,另一半作為測試集nExT;同樣,nX也拆分為訓練集nX和測試集nXT;
4.10、將負樣本nX和正樣本pX合併到ferns_data[]中,用於集合分類器的訓練;
4.11、將上面得到的一個正樣本pEx和nEx合併到nn_data[]中,用於最近鄰分類器的訓練;
4.12、用上面的樣本訓練集訓練 集合分類器(森林) 和 最近鄰分類器:
classifier.trainF(ferns_data, 2); //bootstrap = 2
對每一個樣本ferns_data[i] ,如果樣本是正樣本標籤,先用measure_forest函式返回該樣本所有樹的所有特徵值對應的後驗概率累加值,該累加值如果小於正樣本閾值(0.6* nstructs,這就表示平均值需要大於0.6(0.6* nstructs / nstructs),0.6是程式初始化時定的集合分類器的閾值,為經驗值,後面會用測試集來評估修改,找到最優),也就是輸入的是正樣本,卻被分類成負樣本了,出現了分類錯誤,所以就把該樣本新增到正樣本庫,同時用update函式更新後驗概率。對於負樣本,同樣,如果出現負樣本分類錯誤,就新增到負樣本庫。
classifier.trainNN(nn_data);
對每一個樣本nn_data,如果標籤是正樣本,通過NNConf(nn_examples[i], isin, conf, dummy);計算輸入影象片與線上模型之間的相關相似度conf,如果相關相似度小於0.65 ,則認為其不含有前景目標,也就是分類錯誤了;這時候就把它加到正樣本庫。然後就通過pEx.push_back(nn_examples[i]);將該樣本新增到pEx正樣本庫中;同樣,如果出現負樣本分類錯誤,就新增到負樣本庫。
4.13、用測試集在上面得到的 集合分類器(森林) 和 最近鄰分類器中分類,評價並修改得到最好的分類器閾值。
classifier.evaluateTh(nXT, nExT);
對集合分類器,對每一個測試集nXT,所有基本分類器的後驗概率的平均值如果大於thr_fern(0.6),則認為含有前景目標,然後取最大的平均值(大於thr_fern)作為該集合分類器的新的閾值。
對最近鄰分類器,對每一個測試集nExT,最大相關相似度如果大於nn_fern(0.65),則認為含有前景目標,然後取最大的最大相關相似度(大於nn_fern)作為該最近鄰分類器的新的閾值。
5、進入一個迴圈:讀入新的一幀,然後轉換為灰度影象,然後再處理每一幀processFrame;
6、processFrame(last_gray, current_gray, pts1, pts2, pbox, status, tl, bb_file);逐幀讀入圖片序列,進行演算法處理。processFrame共包含四個模組(依次處理):跟蹤模組、檢測模組、綜合模組和學習模組;
6.1、跟蹤模組:track(img1, img2, points1,points2);
track函式完成前一幀img1的特徵點points1到當前幀img2的特徵點points2的跟蹤預測;
6.1.1、具體實現過程如下:
(1)先在lastbox中均勻取樣10*10=100個特徵點(網格均勻撒點),存於points1:
bbPoints(points1, lastbox);
tracker.trackf2f(img1, img2, points, points2);
(3)利用剩下的這不到一半的跟蹤點輸入來預測bounding box在當前幀的位置和大小 tbb:
bbPredict(points, points2, lastbox, tbb);
(4)跟蹤失敗檢測:如果FB error的中值大於10個畫素(經驗值),或者預測到的當前box的位置移出影象,則認為跟蹤錯誤,此時不返回bounding box:
if (tracker.getFB()>10 || tbb.x>img2.cols || tbb.y>img2.rows || tbb.br().x < 1 || tbb.br().y <1)
(5)歸一化img2(bb)對應的patch的size(放縮至patch_size = 15*15),存入pattern:
getPattern(img2(bb),pattern,mean,stdev);
(6)計算影象片pattern到線上模型M的保守相似度:
classifier.NNConf(pattern,isin,dummy,tconf);
(7)如果保守相似度大於閾值,則評估本次跟蹤有效,否則跟蹤無效:
if (tconf>classifier.thr_nn_valid) tvalid =true;
6.1.2、TLD跟蹤模組的實現原理和trackf2f函式的實現:
TLD跟蹤模組的實現是利用了Media Flow 中值光流跟蹤和跟蹤錯誤檢測演算法的結合。中值流跟蹤方法是基於Forward-Backward Error和NNC的。原理很簡單:從t時刻的影象的A點,跟蹤到t+1時刻的影象B點;然後倒回來,從t+1時刻的影象的B點往回跟蹤,假如跟蹤到t時刻的影象的C點,這樣就產生了前向和後向兩個軌跡,比較t時刻中 A點和C點的距離,如果距離小於一個閾值,那麼就認為前向跟蹤是正確的;這個距離就是FB_error;
bool LKTracker::trackf2f(const Mat& img1, const Mat& img2, vector<Point2f> &points1, vector<cv::Point2f> &points2)
函式實現過程如下:
(1)先利用金字塔LK光流法跟蹤預測前向軌跡:
calcOpticalFlowPyrLK( img1,img2, points1, points2, status, similarity, window_size, level, term_criteria, lambda, 0);
(2)再往回跟蹤,產生後向軌跡:
calcOpticalFlowPyrLK( img2,img1, points2, pointsFB, FB_status,FB_error, window_size, level, term_criteria, lambda, 0);
(3)然後計算 FB-error:前向與 後向 軌跡的誤差:
for( int i= 0; i<points1.size(); ++i )
FB_error[i] = norm(pointsFB[i]-points1[i]);
(4)再從前一幀和當前幀影象中(以每個特徵點為中心)使用亞象素精度提取10x10象素矩形(使用函式getRectSubPix得到),匹配前一幀和當前幀中提取的10x10象素矩形,得到匹配後的對映影象(呼叫matchTemplate),得到每一個點的NCC相關係數(也就是相似度大小)。
normCrossCorrelation(img1, img2, points1, points2);
(5)然後篩選出 FB_error[i] <= median(FB_error) 和 sim_error[i] > median(sim_error) 的特徵點(捨棄跟蹤結果不好的特徵點),剩下的是不到50%的特徵點;
filterPts(points1, points2);
6.2、檢測模組:detect(img2);
TLD的檢測分類器有三部分:方差分類器模組、集合分類器模組和最近鄰分類器模組;這三個分類器是級聯的。當前幀img2的每一個掃描視窗依次通過上面三個分類器,全部通過才被認為含有前景目標。具體實現過程如下:
先計算img2的積分圖,為了更快的計算方差:
integral(frame,iisum,iisqsum);
然後用高斯模糊,去噪:
GaussianBlur(frame,img,Size(9,9),1.5);
下一步就進入了方差檢測模組:
6.2.1、方差分類器模組:getVar(grid[i],iisum,iisqsum) >= var
利用積分圖計算每個待檢測視窗的方差,方差大於var閾值(目標patch方差的50%)的,則認為其含有前景目標,通過該模組的進入集合分類器模組:
6.2.2、集合分類器模組:
集合分類器(隨機森林)共有10顆樹(基本分類器),每棵樹13個判斷節點,每個判斷節點經比較得