
機器學習入門框架scikit-learn
有過程式設計經驗的朋友都知道,想要學習一門技術最簡單、最有效、最快速的方法就是programming。在機器學習領域,家喻戶曉的,從零開始的學習框架可能非scikit-learn莫屬了,本部落格將通過一些列的文章來記錄我學習實踐scikit-learn的整個過程。ps:由於個人工作暫時並不涉及機器學習,而我本人也是剛剛開始不久,因此進度不會太快,有興趣的同學可以一起學習實踐,也歡迎大家交流。
scikit-learn同其他許多開源軟體一樣,由開源社群成員自由維護,由於維護成本限制,相比其他機器學習框架,scikit-learn的策略相對比較保守。一是Scikit-learn從來不做除機器學習領域之外的其他擴充套件,二是Scikit-learn從來不採用未經廣泛驗證的演算法。
Scikit-learn六大功能:
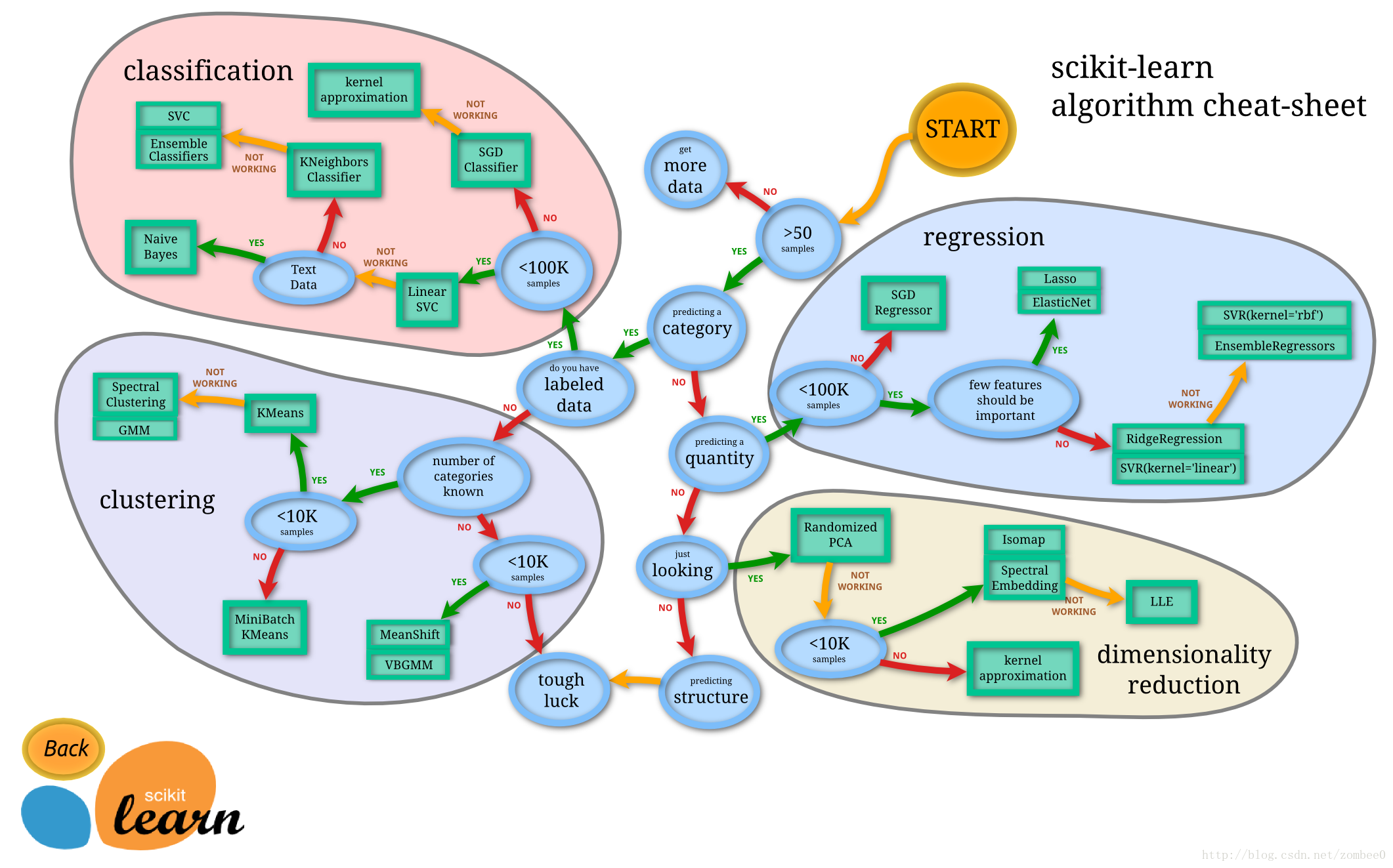
分類,迴歸,聚類,資料降維,模型選擇和資料預處理
分類:
scikit-learn分類演算法主要包括:支援向量機(SVM),最近鄰,邏輯迴歸,隨機森林,決策樹以及多層感知器(MLP)神經網路等等。
迴歸:
scikit-learn迴歸演算法主要包括:支援向量迴歸(SVR),脊迴歸,Lasso迴歸,彈性網路(Elastic Net),最小角迴歸(LARS ),貝葉斯迴歸。
聚類:
scikit-learn聚類演算法主要包括:K-均值聚類,譜聚類,均值偏移,分層聚類,DBSCAN聚類等。
資料降維:
scikit-learn資料降維主要是通過主成分分析(PCA)、非負矩陣分解(NMF)或特徵選擇等降維技術來減少要考慮的隨機變數的個數。
模型選擇:
模型選擇是指對於給定引數和模型的比較、驗證和選擇,其主要目的是通過引數調整來提升精度。目前Scikit-learn實現的模組包括:格點搜尋,交叉驗證和各種針對預測誤差評估的度量函式。
資料預處理:
資料預處理是指資料的特徵提取和歸一化,是機器學習過程中的第一個也是最重要的一個環節。
scikit-learn是入門利器,同時也是真正的利器,廣泛應用於資料探勘等領域,關於其功能的選擇和使用,scikit-learn官方提供瞭如下參考:
歡迎大家關注微信公眾號“翰墨知道”獲取最新更新。
