
機器學習:線性迴歸與Python程式碼實現
前言:本篇博文主要介紹線性迴歸模型(linear regression),首先介紹相關的基礎概念和原理,然後通過Python程式碼實現線性迴歸模型。特別強調,其中大多理論知識來源於《統計學習方法_李航》和斯坦福課程翻譯筆記以及Coursera機器學習課程。
1.線性迴歸
迴歸模型(regression model)也叫做擬合模型,通俗點解釋,就是假設我們有很多資料,包含房子的面積X和對應的房價y,那麼我們希望得到房價y關於面積X的關係(h(X) = y),那麼現在你知道一個房屋的面積Xi,基本就可以根據這個關係預測(推導)出房價yi了。
之所以叫做“線性迴歸”,因為我們假設y與X具有的是一種線性關係,稱為假設函式:
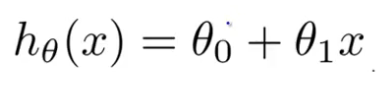
其中引數w0稱為“偏置”,w1稱為“權重”,x表示輸入變數X的一個“特徵變數”,這裡先假設只有一個特徵變數。
Note:我這裡用w代表theta,他的實際含義都是“weight”,建議相關的知識細節,到這裡學習!!!
2.成本函式(cost function)
我們要知道,擬合的函式h(x)有一定的誤差,我們用成本函式J來表示“預測輸出”h(x)與實際輸出y之間的誤差。這裡使用最簡單的“最小均方”(Least mean square)來描述:
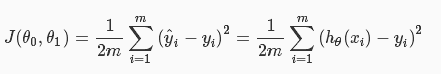
其中,m表示樣本的數量,i表示第i個樣本,其中的1/2,是為了求導方便而新增的專業習慣。
3.引數學習(梯度下降)
所以我們現在的目標是,找出怎麼樣的引數,使得假設函式預測得到的誤差最小,也就是最小化成本函式J。

關於成本函式J的影象大致像一個“碗”(上),我們來看看J關於一個引數w1(其實應該是theta,代表權重引數)的影象(下):
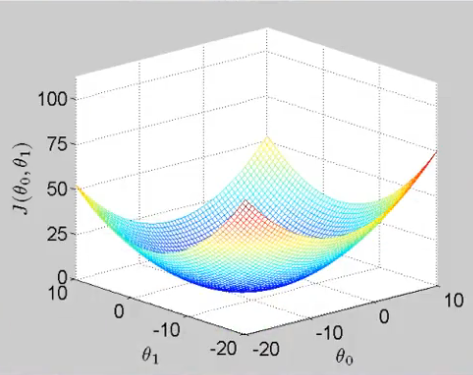
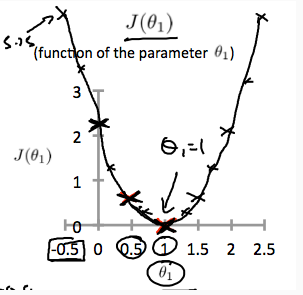
所以按照一般的思路,就是對權重引數求導,使得倒數為0的引數的值,就是成本函式J取得最小值的地方。但是大多時候,求得的偏導的數學表示式很複雜,所以我們採用一種叫做“梯度下降(gradient descent)”的方法
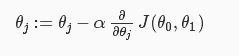
也就是如下:
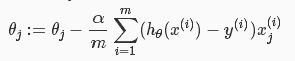
通俗一點講,就是希望權重引數“沿著J減小的方向(梯度減小的方向),一步一步(也就是學習率alpha)的走到那個最低點”。細節不解釋了,還是老地方講的深入淺出。
4.線性迴歸模型Python程式碼實現
先看看資料集
輸入:from sklearn.datasets import load_diabetes diabetes = load_diabetes() print diabetes.keys() data = diabetes.data #real -0.2<x<0.2 target = diabetes.target #integer 25<y<346 print data.shape print target.shape print data[:5] print target[:5]
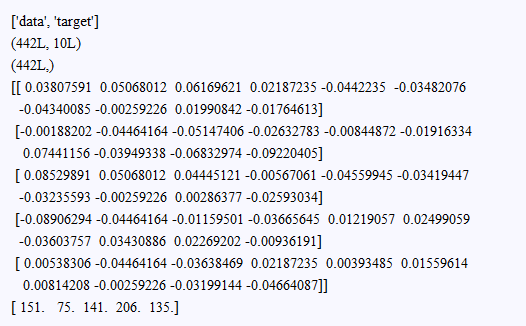
劃分一下資料集,這裡就不劃分驗證集了:
import numpy as np
#use only one feature
X = data[:,:1]
y = target
#X_train = np.array([[0], [1], [2]])
#X_test = np.array([[3], [4], [6]])
#y_train = np.array([0,1,2]).reshape(-1,1)
#y_test = np.array([3,4,5]).reshape(-1,1)
X_train = X[:-20]
X_test = X[-20:]
y_train = y[:-20].reshape((-1,1))
y_test = y[-20:].reshape((-1,1))
print 'X_train=',X_train.shape
print 'X_test=',X_test.shape
print 'y_train=',y_train.shape
print 'y_test=',y_test.shapeclass linear(object):
def __init__(self):
self.W = None
self.b = None
def loss(self,X,y):
num_feature = X.shape[1]
num_train = X.shape[0]
h = X.dot(self.W) + self.b
loss = 0.5 *np.sum(np.square(h - y)) / num_train
dW = X.T.dot((h-y)) / num_train
db = np.sum((h-y)) / num_train
return loss,dW,db
def train(self,X,y,learn_rate = 0.001,iters = 10000):
num_feature = X.shape[1]
self.W = np.zeros((num_feature,1))
self.b = 0
loss_list = []
for i in xrange(iters):
loss,dW,db = self.loss(X,y)
loss_list.append(loss)
self.W += -learn_rate*dW
self.b += -learn_rate*db
if i%500 == 0:
print 'iters = %d,loss = %f' % (i,loss)
return loss_list
def predict(self,X_test):
y_pred = X.dot(self.W) + self.b
return y_pred
pass測試訓練一下:
classify = linear()
print 'start'
loss_list = classify.train(X_train,y_train)
print 'end'
print classify.W,classify.bimport matplotlib.pyplot as plt
f = X_train.dot(classify.W) + classify.b
fig = plt.figure()
plt.subplot(211)
plt.scatter(X_train,y_train,color = 'black')
plt.scatter(X_test,y_test,color = 'blue')
plt.plot(X_train,f,color = 'red')
plt.xlabel('X')
plt.ylabel('y')
plt.subplot(212)
plt.plot(loss_list,color = 'blue')
plt.xlabel('epochs')
plt.ylabel('errors')
plt.show()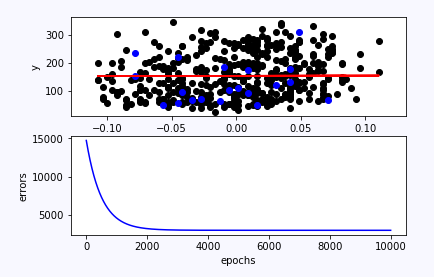
可以看到,線性迴歸學習得到的直線使得樣本資料均勻分佈在兩邊,由於樣本的複雜性,加上這裡模型只選擇一個特徵,太簡單(其實屬於欠擬合,高偏差),所以擬合的不好,誤差較大,但是基本的原理基本就是這樣了。
ps:至於其他的一些細節:正則化、特徵歸一化、多項式特徵等問題,等有空再上程式碼,畢竟一下子也說不清。