
NLP --- 文字分類(基於LDA的隱語意分析訓練演算法詳解)
上一節詳細介紹了什麼是LDA,詳細講解了他的原理,大家應該好好理解,如果不理解,這一節就別看了,你是看不懂的,這裡我在簡單的敘述LDA的演算法思想:
首先我們只擁有很多篇文字和一個詞典,那麼我們就可以在此基礎上建立基於基於文字和詞向量聯合概率(也可以理解為基於文字和詞向量的矩陣,大家暫且這樣理解),我們只知道這麼多了,雖然知道了聯合概率密度了,但是還是無法計算,因為我們的隱分類或者主題不知道啊,在LSA中使用SVD進行尋找隱分類的,在PLSA中使用概率進行找隱分類的,而在LDA中是如何做的呢?他是這樣做的,首先我為每個文字賦值一個服從Dirichlet分佈的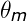
確定了這個這篇文章的某一個位置的詞了即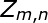 ,那麼我通過詞典,在通過
,那麼我通過詞典,在通過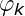 去尋找這個詞對應的隱分類(主題),這樣我就確定了這篇文章的隱分類,同時都可以計算了所有的相關概率,後面就可以通過隱分類和相關概率進行判斷文字的相似性等等就和前面幾節一樣了,這就是LDA的深層工作原理,我們一起看看下圖,在分析一下,看看是不是這樣的:
去尋找這個詞對應的隱分類(主題),這樣我就確定了這篇文章的隱分類,同時都可以計算了所有的相關概率,後面就可以通過隱分類和相關概率進行判斷文字的相似性等等就和前面幾節一樣了,這就是LDA的深層工作原理,我們一起看看下圖,在分析一下,看看是不是這樣的:
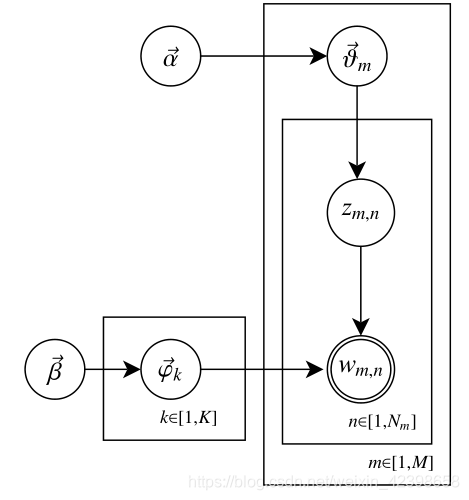
首先我通過文字和詞向量建立聯合概率密度,但是這個聯合概率密度需要知道隱分類,要不然後面無法進一步計算,首先我們現在需要確定這個文字有多少個隱分類(隱分類和詞的多少有關),而隱分類的和詞相關,上圖的
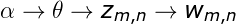
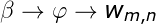 的意思了,這裡大家應該可以理解了,當然這需要大家知道前面的知識如LSA、PLSA,不懂的請自行查閱我的前兩篇文章,下面開始今天的內容即LDA是如何訓練的:
的意思了,這裡大家應該可以理解了,當然這需要大家知道前面的知識如LSA、PLSA,不懂的請自行查閱我的前兩篇文章,下面開始今天的內容即LDA是如何訓練的:
LDA訓練演算法
通過上一篇的文章我們知道了什麼是LDA模型,那麼這個模型有兩個目標,如下:
- 估計模型的引數
和
;
- 對於新來的一篇文件
,我們能夠計算這篇文件的主題(隱分類、topic)分佈

根據前面的演算法即LSA,PLSA我們知道只要知道隱分類(主題、topic)那麼文字其他計算就簡單了,因此這裡我們第二個目標就不詳細的講解,本節詳細介紹LDA的訓練演算法,當然,我只是把訓練演算法的思路講一下,具體細節大家看原始論文吧,這一節我想想就頭大的,我盡力寫,你們也盡力看,等這一節過了,後面的就很簡單了。下面開始:
總體思路:
首先給出聯合分佈公式(但由於topic是隱變數,所以實際上並能進行計算)
- 從聯合分佈推匯出條件概率公式(用於Gibbs抽樣)
- 通過Gibbs抽樣過程推算出每個詞所屬topic
- Topic算出來後,分佈中已經沒有隱變數,通過推導公式倒推出分佈引數
這裡我們參考的論文是《Parameter estimation for text analysis》,大家可以找一下這篇文章參考看一下:
![]()
這裡先從這個概率說起,為什麼是這個形式呢?這裡大家先搞明白上面的符號代表的什麼意思,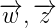
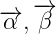
這就是根據條件概率來回變換而已: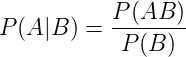
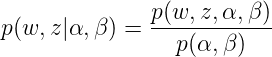
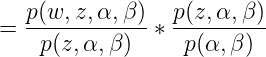
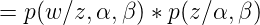
這裡需要理由概率圖模型,不懂的看這篇文章,因為w是是直接受到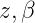
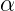
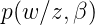
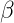
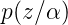
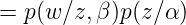
就是原始的定義了,大家明白了吧,繼續往下:
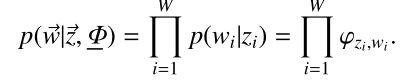
上式的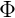
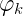
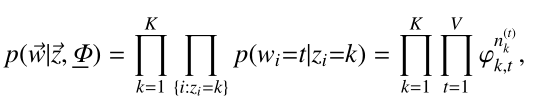
上式是根據Dirichlet分佈展開的,繼續往下
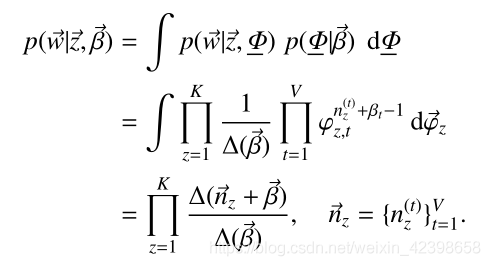
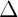
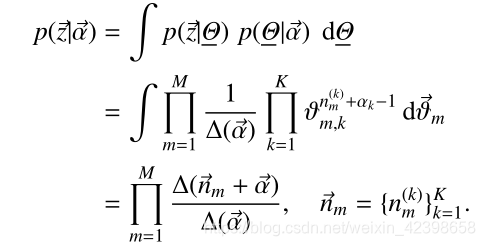
由此我們剛開始的聯合概率密度可以寫為如下:
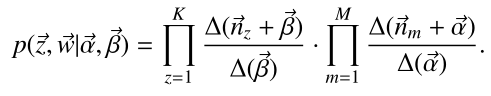
由此我們繼續引出條件概率:
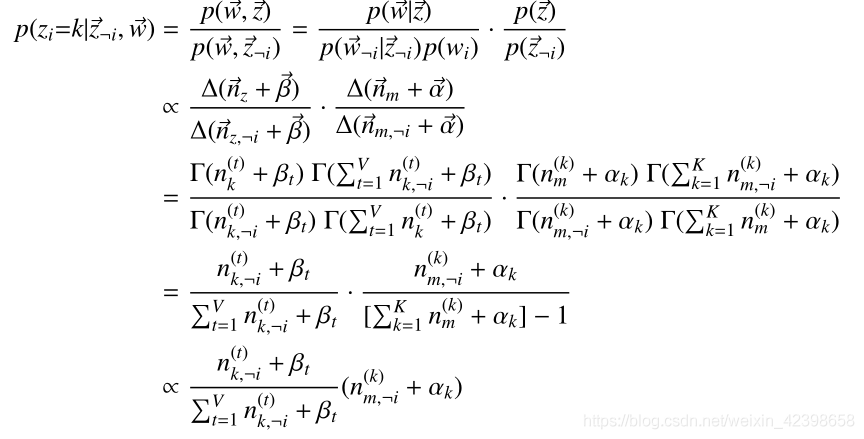
上式大概是什麼意思呢?就是說,這裡其實就是我們上一篇提到的Gibbs取樣形式了,這裡我們令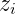
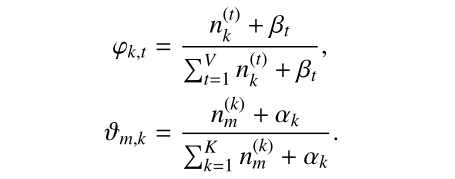
大家參考原始論文和下面的部落格會有更大的收穫的,尤其虛擬碼:

大家參考這篇文章吧,我目前理解也不算很深,以後實戰也許會理解的更深,到時候再補一下,抱歉大家,本人能力就這些,只能從大體上理解他是如何工作和訓練的,請多包涵。