100天專案 Day1 資料預處理
阿新 • • 發佈:2019-01-01
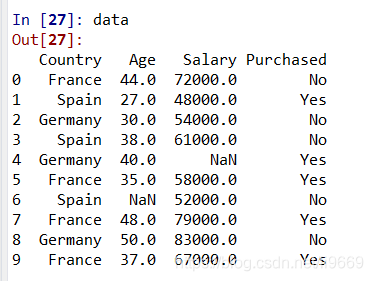
拿到資料後,正常遇到的問題可能有以下:
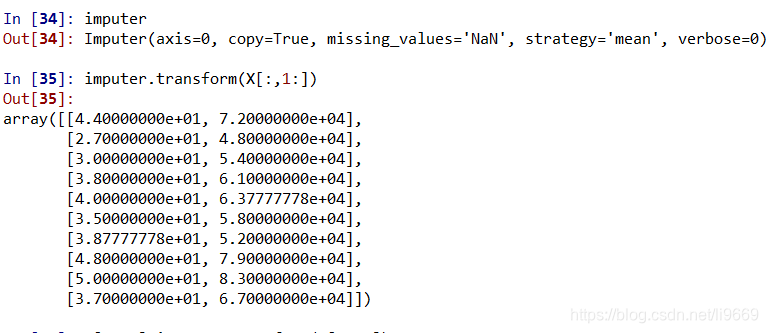
- 資料中含有空值:需要對空值做處理
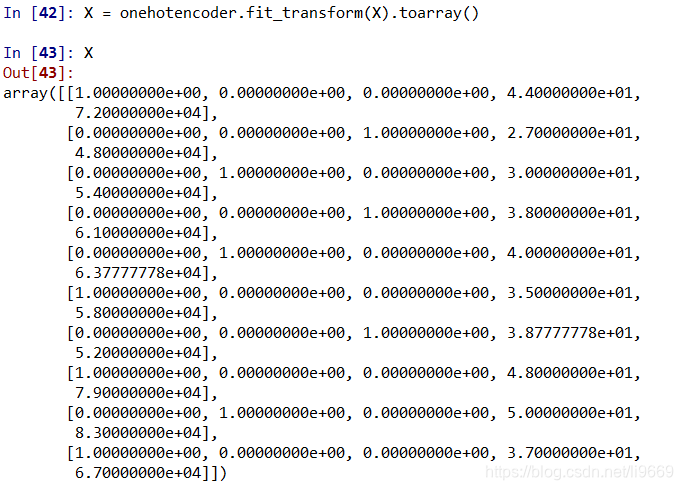
- 資料有非數值型維度,需要轉換為資料維度,且分成多個虛擬欄位
- 資料值範圍太大,可以對數轉化等標準化處理
主要程式碼註釋和資料如下:
遇到的問題主要是import sklearn.model_selection 報錯,安裝了最新版的anaconda後就ok了
import numpy as np import pandas as pd data = pd.read_csv(r'd:\Users\lulib\Desktop\data.txt',sep='\t') X = data.iloc[:,:-1].values ## X的值為資料來源 Y = data.iloc[:,-1].values ## Y 的值為最終的資料標籤 ## na資料用均值填充 from sklearn.preprocessing import Imputer imputer = Imputer(missing_values="NaN",strategy="mean",axis=0) ## 資料範圍轉化一致 對數處理 e 為底 imputer = imputer.fit(X[:,1:]) X[:,1:] = imputer.transform(X[:,1:]) ## 分類包 from sklearn.preprocessing import LabelEncoder, OneHotEncoder ## 文字描述性欄位轉換為數值 labelencoder_X = LabelEncoder() X[ : , 0] = labelencoder_X.fit_transform(X[ : , 0]) ## 將X的文字性描述欄位轉換為多個虛擬欄位,標誌為0 1 onehotencoder = OneHotEncoder(categorical_features = [0]) X = onehotencoder.fit_transform(X).toarray() labelencoder_Y = LabelEncoder() Y = labelencoder_Y.fit_transform(Y) ## 資料來源分為測試資料和訓練資料 from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split( X , Y , test_size = 0.2, random_state = 0) ##特徵標準化 from sklearn.preprocessing import StandardScaler sc_X = StandardScaler() X_train = sc_X.fit_transform(X_train) X_test = sc_X.transform(X_test)