
ML Day1資料預處理
阿新 • • 發佈:2019-01-11
機器學習100天,每天進步一點點。跟著GitHub開始學習!
英文專案地址https://github.com/Avik-Jain/100-Days-Of-ML-Code
中文專案地址https://github.com/MLEveryday/100-Days-Of-ML-Code
1 匯入相應的庫
import numpy as np #包含數學計算函式
import pandas as pd #用於匯入和管理資料集
2 匯入資料集
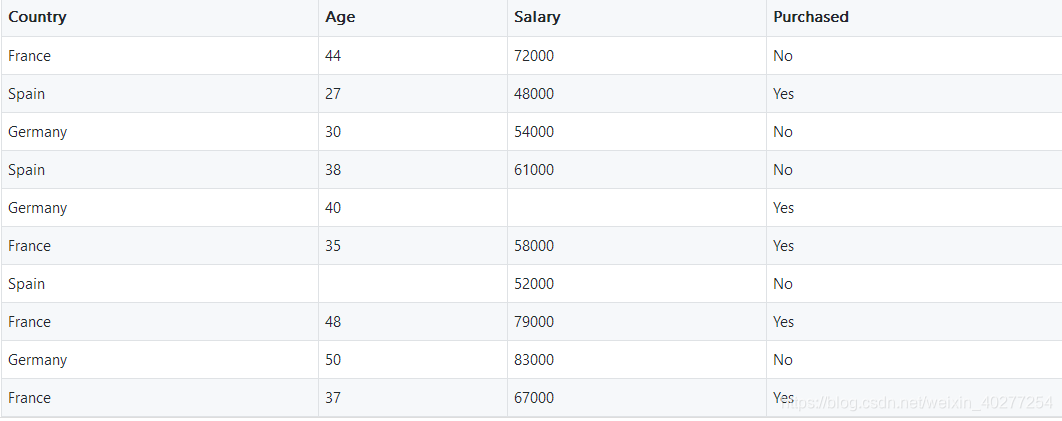
dataset = pd.read_csv('../datasets/Data.csv') X = dataset.iloc[ : , :-1].values #iloc是取矩陣的某行某列,第一個冒號是所有行,第二個是除了最後一列的所有列 Y = dataset.iloc[ : , 3].values #取所有行,最後一列為依賴變數
3 處理丟失資料
對缺失值進行處理的一般思路是使用這一列資料的“平均數”,“中位數”或“眾數”來填充。
missing_values:遺失部分的資料用NaN的方式填補;
strategy:可選擇mean,median,most_frequent,分別代表平均數 中間值 最常出現的數值;
axis:傳0或者1,0代表處理列 ,1代表處理行。
from sklearn.preprocessing import Imputer #Imputer類對缺失資料進行處理 imputer = Imputer(missing_values = "NaN", strategy = "mean", axis = 0) #用特徵列的均值替換缺失值 imputer = imputer.fit(X[ : , 1:3]) #用資料擬合X的前兩列 X[ : , 1:3] = imputer.transform(X[ : , 1:3])
4 解析分類資料
像Country和Purchased這兩列資料,其實質是分類,而不是數值大小,使用虛擬編碼對其進行處理。
from sklearn.preprocessing import LabelEncoder, OneHotEncoder labelencoder_X = LabelEncoder() #LabelEncoder可將標籤分配一個0——n_class-1之間的編碼 X[ : , 0] = labelencoder_X.fit_transform(X[ : , 0]) #擬合與轉化所有行第0列 #Creating a dummy variable onehotencoder = OneHotEncoder(categorical_features = [0]) #第0列進行獨熱編碼 X = onehotencoder.fit_transform(X).toarray() #不加toarray()的話,輸出稀疏的儲存格式 labelencoder_Y = LabelEncoder() Y = labelencoder_Y.fit_transform(Y)
5 拆分資料集為訓練集和測試集
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X , Y , test_size = 0.2, random_state = 0) #訓練集與測試集的比例一般為4:16 特徵縮放
為了防止數值較大的自變數對數值較小的自變數的影響,或是為了在演算法中使得收斂速度更快進行特徵縮放。特徵縮放有兩種方法(標準化和正常化):

from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler() #針對某一特徵維度進行標準化,經處理後的資料符合標準正態分佈,均值為0,標準差為1
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)