
淺談AP聚類演算法-matlab
AP(Affinity Propagation)演算法,稱為仿射傳播聚類演算法、近鄰傳播聚類演算法、親和傳播聚類演算法,是根據資料點之間的相似度來進行聚類,可以是對稱的,也可以是不對稱的。 該演算法不需要先確定聚類的數目,而是把所有的資料點都看成潛在意義上的聚類中心(exemplar).這有別於K-means等聚類。
1.Clustering by Passing Messages Between Data Points 文章微譯
基於測量相似度的聚類在科學的數學分析和工程系統都是關鍵的一步。一個共同的做法就是用資料去獲得一組中心,這樣資料點和它最近的中心之間的平方差是很小的。當聚類中心從實際資料點中被選出,它們就被稱為“exemplars”。流行的K-centers聚類技術是隨機地選擇一組中心點作為exemplars進行初始化,並且迭代地提取聚類中心來減少平方差總和。簇中心點的初始化對K-centers 聚類演算法是很重要的,所以為了找到一個好的聚類方案常常要返回去重新初始化多次。然而,只有當簇的數量少的時候它的聚類效果才會很好並且很可能一次隨意的初始化就可以得到一個近乎好的聚類方案。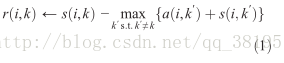 第一次迭代時,因為availabilities是0,r(i,k)被設定成輸入的點i,k之間的相似度作為它的exemplar,減去點i和其他候選聚類中心之間的最大相似度。這個競爭更新是資料驅動的並且不考慮有多少其他的點支援每個候選聚類中心。
第一次迭代時,因為availabilities是0,r(i,k)被設定成輸入的點i,k之間的相似度作為它的exemplar,減去點i和其他候選聚類中心之間的最大相似度。這個競爭更新是資料驅動的並且不考慮有多少其他的點支援每個候選聚類中心。在後面的迭代中,由下面的更新規則規定,當一些點被有效地分配給其他聚類中心,他們的availabilities將會降到零下。這些負的availabilities會減小上面規則中的一些輸入相似度s(i,k′) 的有效值,從競爭中去掉相應的候選聚類中心。由於k=i,responsibilities r(k,k)被設定成k被選作為聚類中心的輸入的preference(s(k,k))減去點i和其他所有候選聚類中心的最大相似度。這個"self-responsibility"基於輸入合適的preference,通過表明k多麼不合適分配給另一個聚類中心,來反映k是一個聚類中心的累積證據。鑑於上面的responsibility的更新讓所有的候選簇中心競爭資料點的控制權,下面的availibility更新從資料點積累關於是否每個候選聚類中心都會是一個好的聚類中心的證據。
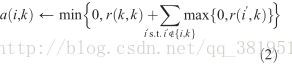
availability a(i,k)被設定成self-responsibility r(k,k)加上從其他點獲得的正responsibilities候選聚類中心k的總和。只有正responsibilities部分是會被新增進來的,因為對於一個好的聚類中心正responsibilities是必要的。不管負的responsibilities多麼不適合的程度。如果self-responsibility r(k,k)是負的(表明點k目前更適合作為另一個簇中心點的歸屬點比作為一個簇中心點)。如果一些其他點支援點k作為它們的簇中心,k作為一個簇中心點的availibility能夠增加。
為了限制得到的正responsibilities的強烈影響,這個總和是被限定的,它不能大於0.”self-availability”a(k,k)的更新是不一樣的:
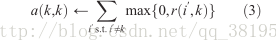
基於正responsibilities從其他點傳遞給候選聚類中心,這個資訊反映了點k是一個聚類中心的積累證據。
以上更新規律要求是最簡單的,本地計算機很容易實現,並且訊息只需要在已知的相似度的點之間交換。在AP演算法實現的過程中任何點的availabilities和responsibilities都與定義聚類中心相關聯。對於點i,a(i,k)+r(i,k)取最大值時的k值,如果k=i時,確定點i作為一個聚類中心,否則確定資料點k是點id聚類中心。超過一個固定的迭代次數或訊息的變化小於一個閾值或本地決定對一些迭代數量保持不變時,訊息的傳遞過程將會被終止。當更新訊息時,它們被阻尼去避免出現在某些情況下的資料振盪是重要的。每個訊息被設定為先前迭代裡它的值的l倍加上它規定的更新值的(1- l)倍,且阻尼係數l的值在0和1之間。在我們所有的實驗裡,我們用一個預設的阻尼係數l=0.5,並且每個AP迭代都由更新所有被給了availabilities的responsibilities,更新所有被給了responsibilities的availabilities以及結合availibilities和responsibilities去監視聚類中心的決定和當這些決定不再改變時終止演算法。
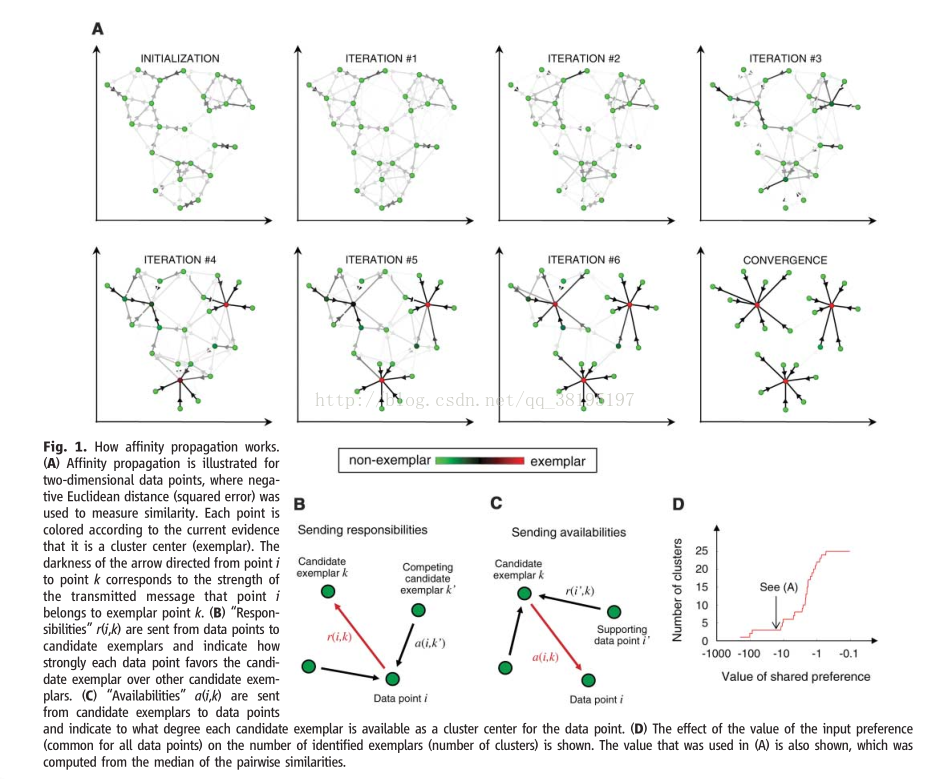
Figure1A展示了AP應用於25個兩維資料點的運動過程,用負平方差作為相似度。AP的一個優點是聚類中心的數量不用預先指定。反而,合適的聚類中心的數量從資訊傳遞方法中產生並且取決於聚類中心引數(preference)。這能夠自動化模型選擇是基於前面的對每個點如何作為聚類中心才合適的描述。Figure1D展示了輸入的共同的preference的值對產生簇的數目的影響。這個關係幾乎和通過精確地最小化平方差去發現的關係是一樣的。
2.以下以最簡單的六個點進行聚類為例,分析AP演算法實現的基本步驟和核心思想:
clear all;close all;clc; %清除所有變數,關閉所有視窗, 清除命令視窗的內容
x=[1,0; %定義一個矩陣
1,1;
0,1;
4,1;
4,0;
5,1];
N=size(x,1); %N為矩陣的列數,即聚類資料點的個數
M=N*N-N; %N個點間有M條來回連線,考慮到從i到k和從k到i的距離可能是不一樣的
s=zeros(M,3); %定義一個M行3列的零矩陣,用於存放根據資料點計算出的相似度
j=1; %通過for迴圈給s賦值,第一列表示起點i,第二列為終點k,第三列為i到k的負歐式距離作為相似度。
for i=1:N
for k=[1:i-1,i+1:N]
s(j,1)=i;s(j,2)=k;
s(j,3)=-sum((x(i,:)-x(k,:)).^2);
j=j+1;
end;
end;
p=median(s(:,3)); %p為矩陣s第三列的中間值,即所有相似度值的中位數,用中位數作為preference,將獲得數量合適的簇的個數
tmp=max(max(s(:,1)),max(s(:,2))); %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
S=-Inf*ones(N,N); %-Inf負無窮大,定義S為N*N的相似度矩陣,初始化每個值為負無窮大
for j=1:size(s,1) %用for迴圈將s轉換為S,S(i,j)表示點i到點j的相似度值
S(s(j,1),s(j,2))=s(j,3);end;
nonoise=1; %此處僅選擇分析無噪情況(即S(i,j)=S(j,i)),所以略去下面幾行程式碼
%if ~nonoise %此處幾行註釋掉的程式碼是 在details,sparse等情況下時為了避免使用了無噪資料而使用的,用來給資料新增noise
%rns=randn('state');
%randn('state',0);
%S=S+(eps*S+realmin*100).*rand(N,N);
%randn('state',rns);
%end;
%Place preferences on the diagonal of S
if length(p)==1 %設定preference
for i=1:N
S(i,i)=p;
end;
else
for i=1:N
S(i,i)=p(i);
end;
end;
% Allocate space for messages ,etc
dS=diag(S); %%%%%%%%%%%%%%%%列向量,存放S中對角線元素資訊
A=zeros(N,N);
R=zeros(N,N);
%Execute parallel affinity propagation updates
convits=50;maxits=500; %設定迭代最大次數為500次,迭代不變次數為50
e=zeros(N,convits);dn=0;i=0; %e迴圈地記錄50次迭代資訊,dn=1作為一個迴圈結束訊號,i用來記錄迴圈次數
while ~dn
i=i+1;
%Compute responsibilities
Rold=R; %用Rold記下更新前的R
AS=A+S %A(i,j)+S(i,j)
[Y,I]=max(AS,[],2) %獲得AS中每行的最大值存放到列向量Y中,每個最大值在AS中的列數存放到列向量I中
for k=1:N
AS(k,I(k))=-realmax; %將AS中每行的最大值置為負的最大浮點數,以便於下面尋找每行的第二大值
end;
[Y2,I2]=max(AS,[],2); %存放原AS中每行的第二大值的資訊
R=S-repmat(Y,[1,N]); %更新R,R(i,k)=S(i,k)-max{A(i,k')+S(i,k')} k'~=k 即計算出各點作為i點的簇中心的適合程度
for k=1:N %eg:第一行中AS(1,2)最大,AS(1,3)第二大,
R(k,I(k))=S(k,I(k))-Y2(k); %so R(1,1)=S(1,1)-AS(1,2); R(1,2)=S(1,2)-AS(1,3); R(1,3)=S(1,3)-AS(1,2).............
end; %這樣更新R後,R的值便表示k多麼適合作為i 的簇中心,若k是最適合i的點,則R(i,k)的值為正
lam=0.5;
R=(1-lam)*R+lam*Rold; %設定阻尼係數,防止某些情況下出現的資料振盪
%Compute availabilities
Aold=A;
Rp=max(R,0) %除R(k,k)外,將R中的負數變為0,忽略不適和的點的不適合程度資訊
for k=1:N
Rp(k,k)=R(k,k);
end;
A=repmat(sum(Rp,1),[N,1])-Rp %更新A(i,k),先將每列大於零的都加起來,因為i~=k,所以要減去多加的Rp(i,k) 
dA=diag(A);
A=min(A,0); %除A(k,k)以外,其他的大於0的A值都置為0
for k=1:N
A(k,k)=dA(k);
end;
A=(1-lam)*A+lam*Aold; %設定阻尼係數,防止某些情況下出現的資料振盪
%Check for convergence
E=((diag(A)+diag(R))>0);
e(:,mod(i-1,convits)+1)=E; %將迴圈計算結果列向量E放入矩陣e中,注意是迴圈存放結果,即第一次迴圈得出的E放到N*50的e矩陣的第一列,第51次的結果又放到第一列
K=sum(E); %每次只保留連續的convits條迴圈結果,以便後面判斷是否連續迭代50次中心簇結果都不變。%%%%%%%%%%%%%%%%
if i>=convits || i>=maxits %判斷迴圈是否終止
se=sum(e,2); %se為列向量,E的convits次迭代結果和
unconverged=(sum((se==convits)+(se==0))~=N);%所有的點要麼迭代50次都滿足A+R>0,要麼一直都小於零,不可以作為簇中心
if (~unconverged&&(K>0))||(i==maxits) %迭代50次不變,且有簇中心產生或超過最大迴圈次數時迴圈終止。
dn=1;
end;
end;
end;
I=find(diag(A+R)>0); %經過上面的迴圈,便確定好了哪些點可以作為簇中心點,用find函式找出那些簇1中心點,這個簡單demo中I=[2,4],
K=length(I); % Identify exemplars %即第二個點和第四個點為這六個點的簇中心
if K>0 %如果簇中心的個數大於0
[~,c]=max(S(:,I),[],2); %取出S中的第二,四列;求出2,4列的每行的最大值,如果第一行第二列的值大於第一行第四列的值,則說明第一個點是第二個點是歸屬點
c(I)=1:K; % Identify clusters %c(2)=1,c(4)=2(第2個點為第一個簇中心,第4個點為第2個簇中心)
% Refine the final set of exemplars and clusters and return results
for k=1:K
ii=find(c==k); %k=1時,發現第1,2,3個點為都屬於第一個簇
[y,j]=max(sum(S(ii,ii),1)); %k=1時 提取出S中1,2,3行和1,2,3列組成的3*3的矩陣,分別算出3列之和取最大值,y記錄最大值,j記錄最大值所在的列
I(k)=ii(j(1)); %I=[2;4]
end;
[tmp,c]=max(S(:,I),[],2); %tmp為2,4列中每行最大陣列成的列向量,c為每個最大數在S(:,I)中的位置,即表示各點到那個簇中心最近
c(I)=1:K; %c(2)=1;c(4)=2;
tmpidx=I(c) %I=[2;4],c中的1用2替換,2用4替換
%(tmpidx-1)*N+(1:N)' %一個列向量分別表示S(1,2),S(2,2),S(3,2),S(4,4),S(5,4),S(6,4)是S矩陣的第幾個元素
%sum(S((tmpidx-1)*N+(1:N)')) %求S中S(1,2)+S(2,2)+S(3,2)+S(4,4)+S(5,4)+S(6,4)的和
tmpnetsim=sum(S((tmpidx-1)*N+(1:N)')); %將各點到簇中心的一個表示距離的負值的和來衡量這次聚類的適合度
tmpexpref=sum(dS(I)); %dS=diag(S); %表示所有被選為簇中心的點的適合度之和
else
tmpidx=nan*ones(N,1); %nan Not A Number 代表不是一個數據。資料處理時,在實際工程中經常資料的缺失或者不完整,此時我們可以將那些缺失設定為nan
tmpnetsim=nan;
tmpexpref=nan;
end;
netsim=tmpnetsim; %反應這次聚類的適合度
dpsim=tmpnetsim-tmpexpref; %
expref=tmpexpref; %
idx=tmpidx; %記錄了每個點所屬那個簇中心的列向量
unique(idx);
fprintf('Number of clusters: %d\n',length(unique(idx)));
fprintf('Fitness (net similarity): %g\n',netsim);
figure; %繪製結果
for i=unique(idx)'
ii=find(idx==i);
h=plot(x(ii,1),x(ii,2),'o');
hold on;
col=rand(1,3);
set(h,'Color',col,'MarkerFaceColor',col);
xi1=x(i,1)*ones(size(ii));
xi2=x(i,2)*ones(size(ii));
line([x(ii,1),xi1]',[x(ii,2),xi2]','Color',col);
end;
axis equal ;
執行影象結果:
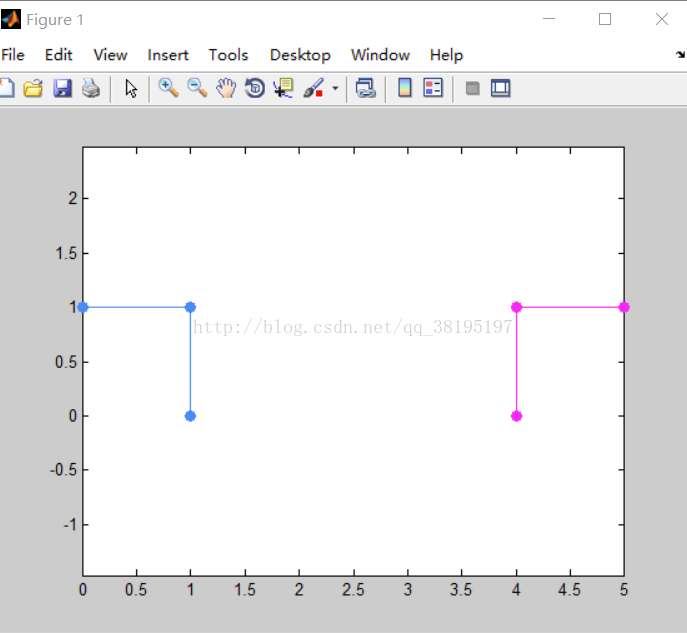
3.個人的理解(僅供參考)
①輸入一組相似度,一般取相似度的中位數作為preference引數
②計算R和A。計算R時,R值確定k適合作為i的聚類中心的程度。R--先從i到k找出最適合作為i的聚類中心的點。(第一次迴圈時,到點i距離最近的點最適合作為i的聚類中心) A--計算其他點對R中找出的那些相對適合的點被選作聚類中心的支援程度的總和。受支援的R值置為零。最後用R(i,i)+A(i,i)>0來衡量點i是否可以作為聚類中心,若超過規定的迭代次數點i依舊是可以的或迴圈次數超過規定的最大迴圈次數,便可以跳出迴圈。
③由R+S>0來找出聚類中心點,再在S中尋找這些聚類中心的歸屬點。
④畫出影象