
常用資料結構 List set map

下面是我自己畫的,關係畫得沒上面好,但我自己看著清楚些
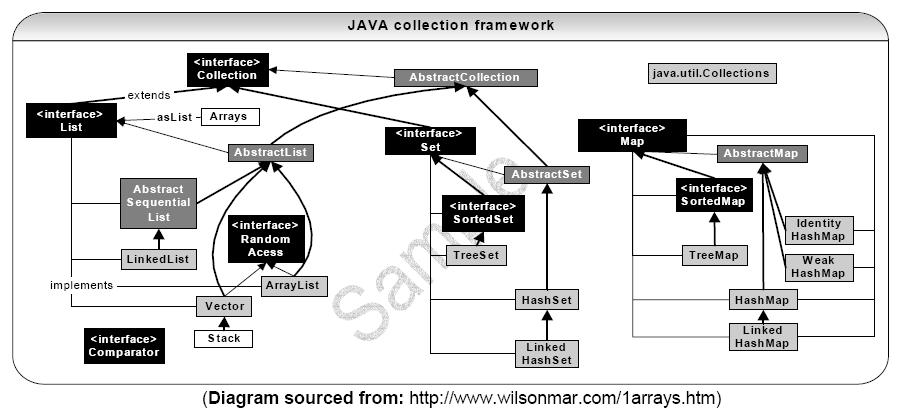
 還有一張下載來的:
還有一張下載來的:
有序否 | 允許元素重複否 | ||
Collection | 否 | 是 | |
List | 是 | 是 | |
Set | AbstractSet | 否 | 否 |
HashSet | |||
TreeSet | 是(用二叉樹排序) | ||
Map | AbstractMap | 否 | 使用key-value來對映和儲存資料,Key必須惟一,value可以重複 |
HashMap | |||
TreeMap | 是(用二叉樹排序) | ||
幾個面試常見問題: 1.Q:ArrayList和Vector有什麼區別?HashMap和HashTable有什麼區別? A:Vector和HashTable是執行緒同步的(synchronized)。效能上,ArrayList和HashMap分別比Vector和Hashtable要好。 2.Q:大致講解java集合的體系結構 A:List、Set、Map是這個集合體系中最主要的三個介面。 其中List和Set繼承自Collection介面。 Set不允許元素重複。HashSet和TreeSet是兩個主要的實現類。 List有序且允許元素重複。ArrayList、LinkedList和Vector是三個主要的實現類。 Map也屬於集合系統,但和Collection介面不同。Map是key對value的對映集合,其中key列就是一個集合。key不能重複,但是value可以重複。HashMap、TreeMap和Hashtable是三個主要的實現類。 SortedSet和SortedMap介面對元素按指定規則排序,SortedMap是對key列進行排序。 3.Q:Comparable和Comparator區別 A:呼叫java.util.Collections.sort(List list)方法來進行排序的時候,List內的Object都必須實現了Comparable介面。 java.util.Collections.sort(List list,Comparator c),可以臨時宣告一個Comparator 來實現排序。 Collections.sort(imageList, new Comparator() { public int compare(Object a, Object b) { int orderA = Integer.parseInt( ( (Image) a).getSequence()); int orderB = Integer.parseInt( ( (Image) b).getSequence()); return orderA - orderB; } }); 如果需要改變排列順序 改成return orderb - orderA 即可。 4.Q:簡述equals()和hashCode() A:...不知道。下回分解 public interface Collection
看到百度知道里面有個回覆比較的好,先複製過來:地址為http://zhidao.baidu.com/question/16113509.html
提問是:
List介面對Collection進行了簡單的擴充,它的具體實現類常用的有ArrayList和LinkedList。你可以將任何東西放到一個List容器中,並在需要時從中取出。ArrayList從其命名中可以看出它是一種類似陣列的形式進行儲存,因此它的隨機訪問速度極快,而LinkedList的內部實現是連結串列,它適合於在連結串列中間需要頻繁進行插入和刪除操作。在具體應用時可以根據需要自由選擇。前面說的Iterator只能對容器進行向前遍歷,而ListIterator則繼承了Iterator的思想,並提供了對List進行雙向遍歷的方法。 Set介面也是Collection的一種擴充套件,而與List不同的時,在Set中的物件元素不能重複,也就是說你不能把同樣的東西兩次放入同一個Set容器中。它的常用具體實現有HashSet和TreeSet類。HashSet能快速定位一個元素,但是你放到HashSet中的物件需要實現hashCode()方法,它使用了前面說過的雜湊碼的演算法。而TreeSet則將放入其中的元素按序存放,這就要求你放入其中的物件是可排序的,這就用到了集合框架提供的另外兩個實用類Comparable和Comparator。一個類是可排序的,它就應該實現Comparable介面。有時多個類具有相同的排序演算法,那就不需要在每分別重複定義相同的排序演算法,只要實現Comparator介面即可。集合框架中還有兩個很實用的公用類:Collections和Arrays。Collections提供了對一個Collection容器進行諸如排序、複製、查詢和填充等一些非常有用的方法,Arrays則是對一個數組進行類似的操作。 Map是一種把鍵物件和值物件進行關聯的容器,而一個值物件又可以是一個Map,依次類推,這樣就可形成一個多級對映。對於鍵物件來說,像Set一樣,一個Map容器中的鍵物件不允許重複,這是為了保持查詢結果的一致性;如果有兩個鍵物件一樣,那你想得到那個鍵物件所對應的值物件時就有問題了,可能你得到的並不是你想的那個值物件,結果會造成混亂,所以鍵的唯一性很重要,也是符合集合的性質的。當然在使用過程中,某個鍵所對應的值物件可能會發生變化,這時會按照最後一次修改的值物件與鍵對應。對於值物件則沒有唯一性的要求。你可以將任意多個鍵都對映到一個值物件上,這不會發生任何問題(不過對你的使用卻可能會造成不便,你不知道你得到的到底是那一個鍵所對應的值物件)。Map有兩種比較常用的實現:HashMap和TreeMap。HashMap也用到了雜湊碼的演算法,以便快速查詢一個鍵,TreeMap則是對鍵按序存放,因此它便有一些擴充套件的方法,比如firstKey(),lastKey()等,你還可以從TreeMap中指定一個範圍以取得其子Map。鍵和值的關聯很簡單,用pub(Object key,Object value)方法即可將一個鍵與一個值物件相關聯。用get(Object key)可得到與此key物件所對應的值物件。