基於Matconvnet深度學習框架的方言分類(1)
背景
本文是基於Matconvnet深度學習框架對方言音訊檔案進行分類,介紹如下:
預處理資料
聲譜圖
預處理資料都是對音訊檔案進行處理,我們都知道 CNN 主要是針對二維資料做分類等,因此我們第一步需要做的是將一維的音訊訊號,通過呼叫specgram函式將音訊檔案轉換成聲譜圖,我在實驗中的採用過兩種引數,分別如下:
- [b,f,t] = specgram(x,512,fs,512,256);
- [b,f,t] = specgram(x,1024,fs,1024,512);
兩種引數生成的聲譜圖 [頻譜圖]雖然從肉眼的角度可以看出區別,但是從最後的實驗結果上來看,可能對分類的結果影響不大。在下面的實驗中我會以實驗結果作說明。
改變尺寸
上述中提到的聲譜圖只是由 Matlab 自帶函式生成的圖片,生成的聲譜圖片中,存在邊緣空白資訊,為了提高我們最終的實驗結果,我們首先要先將空白邊緣資訊使用 imcrop 函式進行裁剪,然後使用 imresize 函式對裁剪過的圖片進行尺寸的縮放,通常我們需要將圖片縮放成經典網路模型需要的尺寸,如:cifar經典資料集、vggnet、alexnet、imagenet等。本文中,我也是採用如下所述的4種尺寸,分別為:32*32、224*224、227*227、256*256.
實驗準備
下載編譯程式碼
由於我們使用的是可以在 Matlab 上執行的 Matconvnet
執行demo
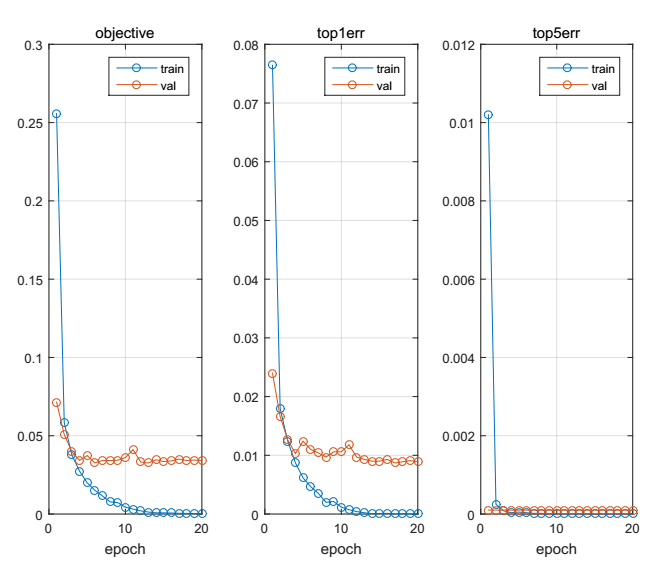
在上述編譯完成之後,為了測試我們是否編譯成功,我們可以執行 examples 資料夾下的 cnn_mnist 程式碼,可以直接執行 cnn_mnist_experiments.m 檔案,程式碼執行的速度很快,即使是在cpu模式下,依然執行的很快,因為這個網路相對簡單一些,資料庫圖片大小為28*28,圖片大小比較小,因此訓練和測試的速度都比較快。在一些新的版本程式碼裡,執行結束之後,可能會報錯,那是在畫圖的時候某一些引數已經不存在了,我們姑且不管這個,在執行結束之後,會生成一個pdf檔案,我們可以開啟著這個pdf檔案觀察實驗結果,在這裡我貼上一個實驗結果的截圖(可能意義不大):