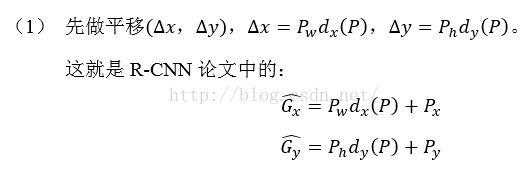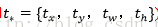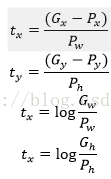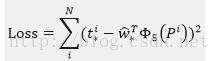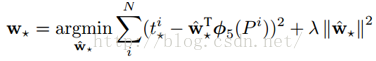Faster RCNN詳解:從region proposal到bounding box迴歸
一基於Region Proposal候選區域的深度學習目標檢測演算法 二R-CNNFast R-CNNFaster R-CNN三者關係 1 R-CNN目標檢測流程介紹 2 Fast R-CNN目標檢測流程介紹 三Faster R-CNN目標檢測 1 Faster R-CNN的思想 2 Faster R-CNN框架介紹 3 RPN介紹 31背景 32RPN核心思想 4 RPN的平移不變性 5 視窗分類和位置精修 6 學習區域建議損失函式 61 標籤分類規定 62 多工損失來自Fast R-CNN 63 Faster R-CNN損失函式 64 R-CNN中的boundingbox迴歸 65 Faster R-CNN中的bounding box迴歸 7 訓練RPNs 取樣 初始化 引數化設定使用caffe實現 9 RPN與Fast R-CNN特徵共享
網上很多關於Faster RCNN的介紹,不過這一片算是比較全的了,不僅包括整體流程、思想的介紹,也包括各個實現較為深入的介紹。大概內容記錄如下(僅記錄目前我感興趣的部分):
1 各種CNN模型以及資料庫
自從接觸基於深度學習的目標檢測這一領域以來,經常遇到各種CNN模型,比如ZF模型、VGG模型等等。同時也接觸到各種資料集如PASCAL VOC、MNIST、ImageNet等等,博文深度學習常用的Data Set資料集和CNN Model總結 進行了總結。
2 RCNN系列方法的介紹
RCNN演算法分為4個步驟
- 一張影象生成1K~2K個候選區域(採用SS方法)
- 對每個候選區域,使用深度網路提取特徵
- 特徵送入每一類的SVM 分類器,判別是否屬於該類
- 使用迴歸器精細修正候選框位置
位置精修
目標檢測問題的衡量標準是重疊面積:許多看似準確的檢測結果,往往因為候選框不夠準確,重疊面積很小。故需要一個位置精修步驟。
迴歸器
對每一類目標,使用一個線性脊迴歸器進行精修。正則項λ=10000。 輸入為深度網路pool5層的4096維特徵,輸出為xy方向的縮放和平移。
訓練樣本
判定為本類的候選框中,和真值重疊面積大於0.6的候選框。 可以看出該網路重複計算量很大,2K個候選框單獨用CNN提取特徵,再分類!
Fast RCNN方法解決了RCNN方法三個問題:
問題一:測試時速度慢
RCNN一張影象內候選框之間大量重疊,提取特徵操作冗餘。
本文將整張影象歸一化後直接送入深度網路。在鄰接時,才加入候選框資訊,在末尾的少數幾層處理每個候選框。
問題二:訓練時速度慢
原因同上。
在訓練時,本文先將一張影象送入網路,緊接著送入從這幅影象上提取出的候選區域。這些候選區域的前幾層特徵不需要再重複計算。
問題三:訓練所需空間大
RCNN中獨立的分類器和迴歸器需要大量特徵作為訓練樣本。
本文把類別判斷和位置精調統一用深度網路實現,不再需要額外儲存。
從RCNN到fast RCNN,再到本文的faster RCNN,目標檢測的四個基本步驟(候選區域生成,特徵提取,分類,位置精修)終於被統一到一個深度網路框架之內。所有計算沒有重複,完全在GPU中完成,大大提高了執行速度。
faster RCNN可以簡單地看做“區域生成網路+fast RCNN“的系統,用區域生成網路代替fast RCNN中的Selective Search方法。本篇論文著重解決了這個系統中的三個問題:
1. 如何設計區域生成網路
2. 如何訓練區域生成網路
3. 如何讓區域生成網路和fast RCNN網路共享特徵提取網路
R-CNN中的boundingbox迴歸
下面先介紹R-CNN和Fast R-CNN中所用到的邊框迴歸方法。
- 什麼是IOU
為什麼要做Bounding-box regression?
如上圖所示,綠色的框為飛機的Ground Truth,紅色的框是提取的Region Proposal。那麼即便紅色的框被分類器識別為飛機,但是由於紅色的框定位不準(IoU<0.5),那麼這張圖相當於沒有正確的檢測出飛機。如果我們能對紅色的框進行微調,使得經過微調後的視窗跟Ground Truth更接近,這樣豈不是定位會更準確。確實,Bounding-box regression 就是用來微調這個視窗的。迴歸/微調的物件是什麼?
- Bounding-box regression(邊框迴歸)
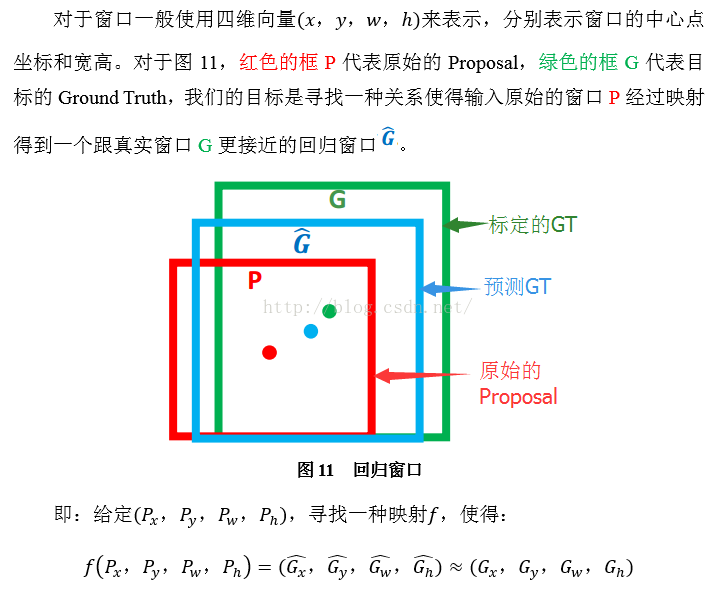
那麼經過何種變換才能從圖11中的視窗P變為視窗呢?比較簡單的思路就是:
注意:只有當Proposal和Ground Truth比較接近時(線性問題),我們才能將其作為訓練樣本訓練我們的線性迴歸模型,否則會導致訓練的迴歸模型不work(當Proposal跟GT離得較遠,就是複雜的非線性問題了,此時用線性迴歸建模顯然不合理)。這個也是G-CNN: an Iterative Grid Based Object Detector多次迭代實現目標準確定位的關鍵。
線性迴歸就是給定輸入的特徵向量X,學習一組引數W,使得經過線性迴歸後的值跟真實值Y(Ground Truth)非常接近。即。那麼Bounding-box中我們的輸入以及輸出分別是什麼呢?
輸入:這個是什麼?輸入就是這四個數值嗎?其實真正的輸入是這個視窗對應的CNN特徵,也就是R-CNN中的Pool5feature(特徵向量)。(注:訓練階段輸入還包括 Ground Truth,也就是下邊提到的)
輸出:需要進行的平移變換和尺度縮放,或者說是
。我們的最終輸出不應該是Ground Truth嗎?是的,但是有了這四個變換我們就可以直接得到Ground Truth,這裡還有個問題,根據上面4個公式我們可以知道,P經過
。
的確,這四個值應該是經過 Ground Truth 和Proposal計算得到的真正需要的平移量和尺度縮放。
這也就是R-CNN中的:
那麼目標函式可以表示為是輸入Proposal的特徵向量,
是要學習的引數(*表示
,也就是每一個變換對應一個目標函式),是得到的預測值。我們要讓預測值跟真實值差距最小,得到損失函式為:
函式優化目標為:
利用梯度下降法或者最小二乘法就可以得到。