
Faster-RCNN詳解
論文題目:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
論文連結:論文連結
論文程式碼:Matlab版本點選此處,Python版本點選此處
作為一個目標檢測領域的baseline演算法,Faster-rcnn值得你去仔細理解裡面的細節,如果你能深入的瞭解這些,我相信你會受益匪淺。
那麼,我們還是按照總分總的順序給大家剖析它吧。(看圖吧)
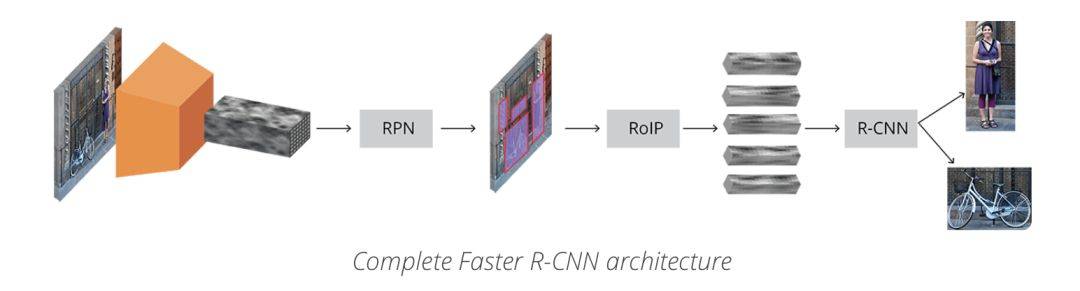
圖1 Faster-rcnn架構圖(理解版)
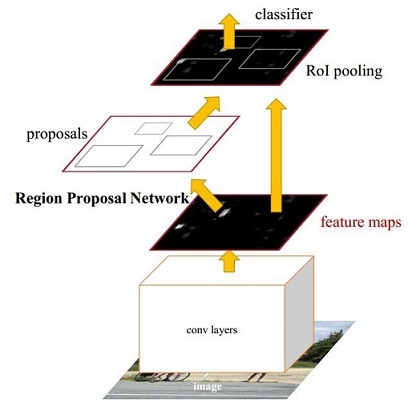
圖2 Faster-rcnn架構圖(精簡版)
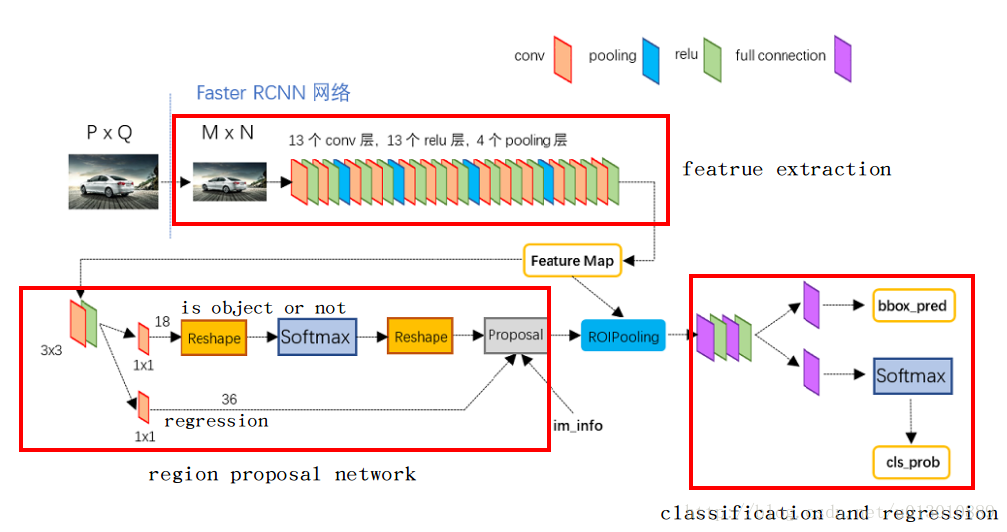
圖3 Faster-rcnn架構圖(細節版)
一、目標檢測的總體框架
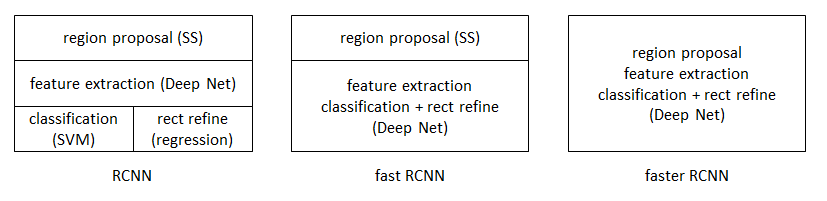
圖4 目標檢測框架圖
觀察圖4,你可以發現目標檢測的框架中包含4個關鍵模組,包括region proposal(生成ROI)、feature extraction(特徵提取網路)、classification(ROI分類)、regression(ROI迴歸)。而faster-rcnn利用一個神經網路將這4個模組結合起來,訓練了一個端到端的網路。通過觀察圖1、圖2、圖3,我們可以得到如下的結論:Faster-rcnn主要包括4個關鍵模組,特徵提取網路、生成ROI、ROI分類、ROI迴歸。
1. 特徵提取網路
2. 生成ROI:在獲得的特徵圖的每一個點上做多個候選ROI(這裡是9),然後利用分類器將這些ROI區分為背景和前景,同時利用迴歸器對這些ROI的位置進行初步的調整;
3. ROI分類:在RPN階段,用來區分前景(於真實目標重疊並且其重疊區域大於0.5)和背景(不與任何目標重疊或者其重疊區域小於0.1);在Fast-rcnn階段,用於區分不同種類的目標(貓、狗、人等);
4. ROI迴歸:在RPN階段,進行初步調整;在Fast-rcnn階段進行精確調整;
總之,其整體流程如下所示:
- 首先對輸入的圖片進行裁剪操作,並將裁剪後的圖片送入預訓練好的分類網路中獲取該影象對應的特徵圖;
- 然後在特徵圖上的每一個錨點上取9個候選的ROI(3個不同尺度,3個不同長寬比),並根據相應的比例將其對映到原始影象中(因為特徵提取網路一般有conv和pool組成,但是隻有pool會改變特徵圖的大小,因此最終的特徵圖大小和pool的個數相關);
- 接著將這些候選的ROI輸入到RPN網路中,RPN網路對這些ROI進行分類(即確定這些ROI是前景還是背景)同時對其進行初步迴歸(即計算這些前景ROI與真實目標之間的BB的偏差值,包括Δx、Δy、Δw、Δh),然後做NMS(非極大值抑制,即根據分類的得分對這些ROI進行排序,然後選擇其中的前N個ROI);
- 接著對這些不同大小的ROI進行ROI Pooling操作(即將其對映為特定大小的feature_map,文中是7x7),輸出固定大小的feature_map;
- 最後將其輸入簡單的檢測網路中,然後利用1x1的卷積進行分類(區分不同的類別,N+1類,多餘的一類是背景,用於刪除不準確的ROI),同時進行BB迴歸(精確的調整預測的ROI和GT的ROI之間的偏差值),從而輸出一個BB集合。
二、Faster-rcnn中的核心問題
1. 提出了“RPN”網路,在提高精度的同時提高了速度;
2. RPN網路和Fast-rcnn網路的特徵共享與訓練;
3. 使用了ROI Pooling技術 ;
4. 使用了NMS技術;
三、細節詳解
1. 錨點
即特徵圖上的最小單位點,比如原始影象的大小是256x256,特徵提取網路中含有4個pool層,然後最終獲得的特徵圖的大小為 256/16 x 256/16,即獲得一個16x16的特徵圖,該圖中的最小單位即是錨點,由於特徵圖和原始影象之間存在比例關係,在特徵圖上面密集的點對應到原始影象上面是有16個畫素的間隔,如下圖所示:
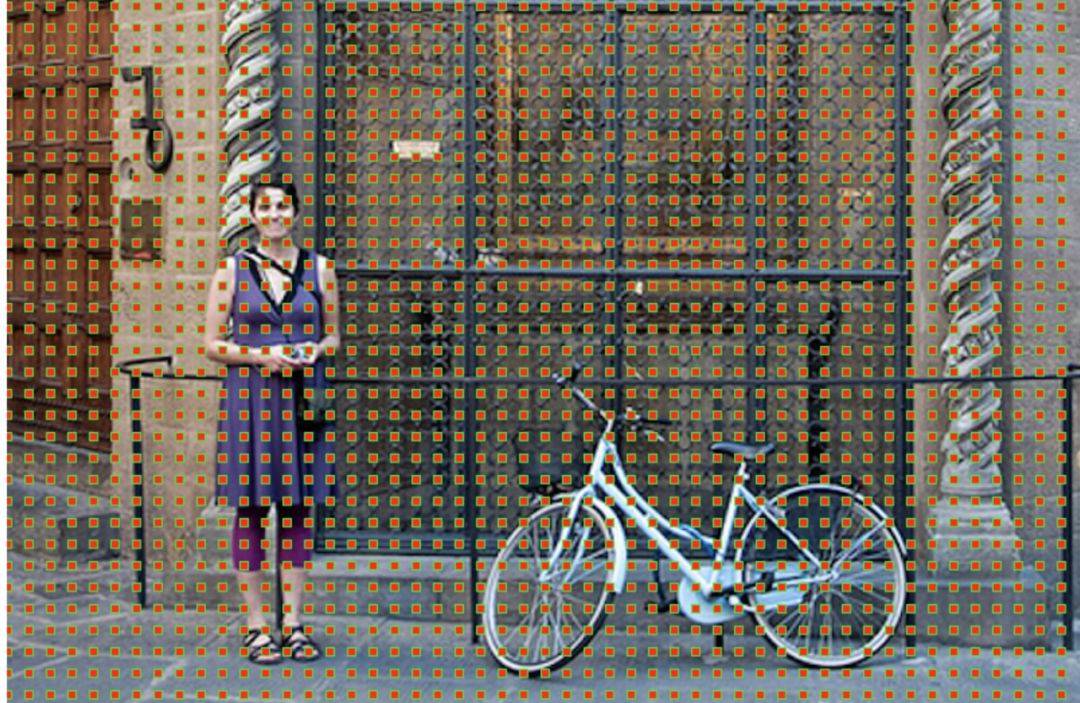
圖5 原始影象中對應的錨點
2. 候選的ROI
針對每一個錨點,然後根據不同的尺度(128、256、512pixel)和不同的長寬比(1:1、0.5:1、1:0.5)產生9個BB,如下圖所示,對於16x16的特徵圖,最終產生16x16x9個候選的ROI。

圖6 左側:錨點、中心:特徵圖空間單一錨點在原圖中的表達,右側:所有錨點在原圖中的表達
3. RPN網路 – 用來對特徵圖上面產生的多個ROI進行區分和初步定位
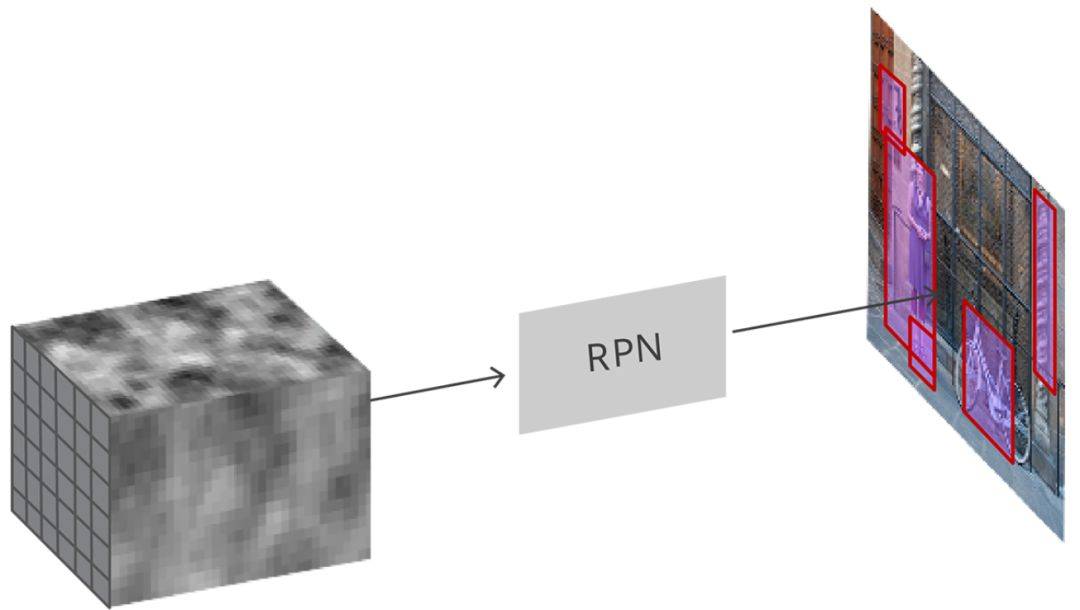
圖7 RPN對映過程
RPN(如圖3所示) 是用完全卷積的方式高效實現的,用基礎網路返回的卷積特徵圖作為輸入。首先,我們使用一個有 512個通道和 3x3 卷積核大小的卷積層,然後我們有兩個使用 1x1 卷積核的並行卷積層,其通道數量取決於每個點的錨點數量。
對於分類層,我們對每個錨點輸出兩個預測值:它是背景(不是目標)的分數,和它是前景(實際的目標)的分數。
對於迴歸或邊框調整層,我們輸出四個預測值:Δx、Δy、Δw、Δh我們將會把這些值用到錨點中來得到最終的建議。
4. ROI Pooling
ROI Pooling的作用是通過最大池化操作將特徵圖上面的ROI固定為特定大小的特徵圖(7x7),以便進行後續的分類和包圍框迴歸操作。
存在的問題
由於預選ROI的位置通常是有模型迴歸得到的,一般來說是浮點數,而赤化後的特徵圖要求尺度固定,因此ROI Pooling這個操作存在兩次資料量化的過程。1)將候選框邊界量化為整數點座標值;2)將量化後的邊界區域平均分割成kxk個單元,對每個單元的邊界進行量化。事實上,經過上面的兩次量化操作,此時的ROI已經和最開始的ROI之間存在一定的偏差,這個偏差會影響檢測的精確度。
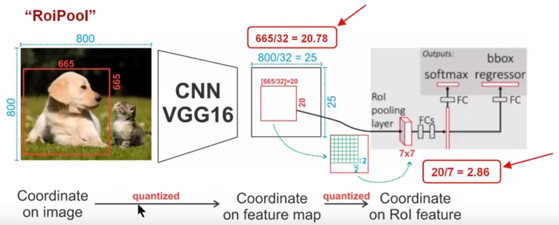
圖8 ROI Pooling解釋
下面我們用直觀的例子具體分析一下區域不匹配問題,如圖所示,這是一個Faster-rcnn檢測框架。輸入一張800x800的圖片,圖片中有一個665x665的BB中框這一隻狗。圖片經過特徵提取網路之後,整個圖片的特徵圖變為800/32 * 800/32,即25x25,但是665/32=20.87,帶有小數,ROI Pooling直接將它量化為20。在這裡引入了一次偏差。由於最終的特徵對映的大小為7x7,即需要將20x20的區域對映成7x7,矩形區域的邊長為2.86,又一次將其量化為2。這裡再次引入了一次量化誤差。經過這兩次的量化,候選ROI已經出現了嚴重的偏差(如圖中綠色部分所示)。更重要的是,在特徵圖上差0.1個畫素,對應到原圖上就是3.2個畫素。
5. ROI Pooling後的檢測網路
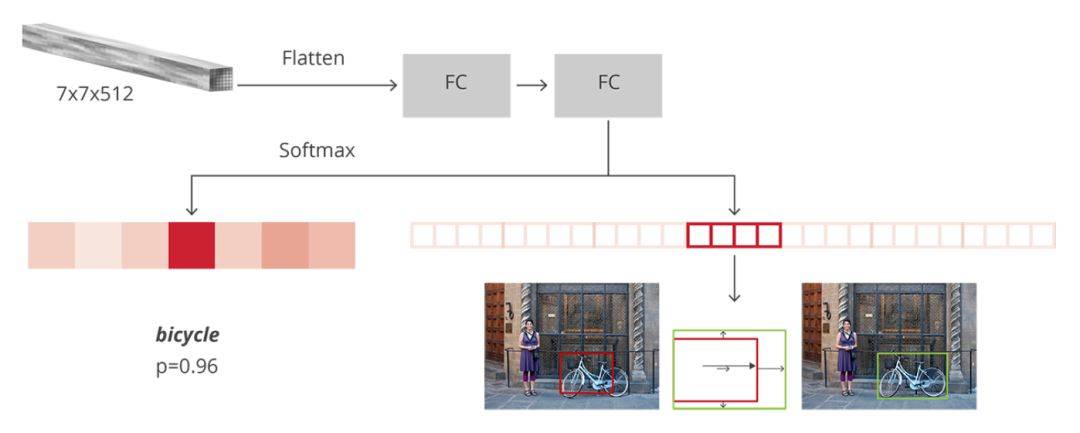
圖9 檢測網路
如上圖所示,在獲得7x7x512的特徵對映之後,通過Flatten操作將其展開為一維向量,然後經過兩個全連線層對其進行分類和迴歸。一個有 N+1 個單元的全連線層,其中 N 是類的總數,另外一個是背景類。一個有 4N 個單元的全連線層。我們希望有一個迴歸預測,因此對 N 個類別中的每一個可能的類別,我們都需要 Δx、Δy、Δw、Δh。
6. NMS(非極大值抑制)
由於錨點經常重疊,因此建議最終也會在同一個目標上重疊。為了解決重複建議的問題,我們使用一個簡單的演算法,稱為非極大抑制(NMS)。NMS 獲取按照分數排序的建議列表並對已排序的列表進行迭代,丟棄那些 IoU 值大於某個預定義閾值的建議,並提出一個具有更高分數的建議。總之,抑制的過程是一個迭代-遍歷-消除的過程。如下圖所示:
- 將所有候選框的得分進行排序,選中最高分及其所對應的BB;
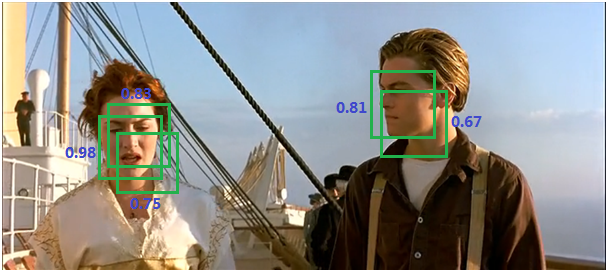
圖10
- 遍歷其餘的框,如果它和當前最高得分框的重疊面積大於一定的閾值,我們將其刪除。
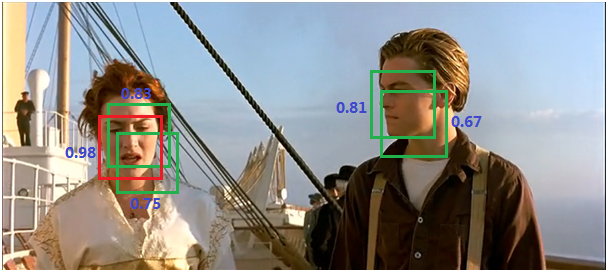
圖11
- 從沒有處理的框中繼續選擇一個得分最高的,重複上述過程。
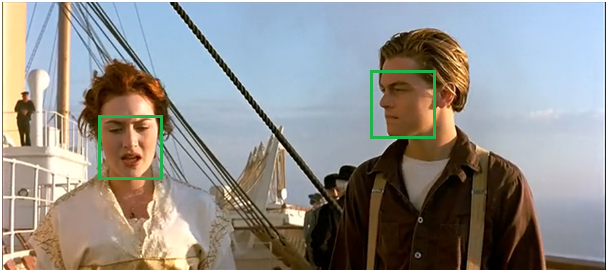
圖12
6. 損失函式計算
對於每個錨點,首先在後面接上一個二分類softmax,有2個score 輸出用來表示這是一個前景還是一個背景的概率 (),然後再接上一個bounding box的regressor 輸出代表這個錨點的4個座標位置(
),因此RPN的總體Loss函式可以定義為 :
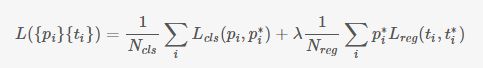
其中Lcls表示分類loss,這裡使用兩類別(前景還是背景)的log loss;Lreg表示迴歸loss,這裡使用的是Smooth-L1;
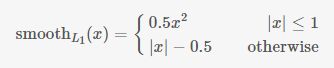
i表示第i個錨點,當錨點是正beiji樣本時 =1 ,是負樣本則為0 。
表示 一個與正樣本錨點相關的ground true box座標 (每個正樣本錨點 只可能對應一個ground true box: 一個正樣本錨點 與某個grand true BB對應,那麼該錨點與ground true box 的IOU要麼是所有anchor中最大,要麼大於0.7) 。
x,y,w,h分別表示box的中心座標、寬和高; 分別表示 predicted box, anchor box, and ground truth box ,如下圖所示;
表示predict box相對於anchor box的偏移量;
表示ground true box相對於anchor box的偏移量,學習的目標就是讓前者接近後者的值。
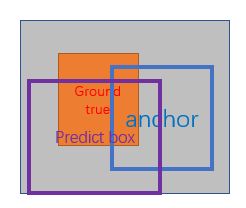
圖13 predicted box, anchor box, and ground truth box
7. 正負樣本的劃分
- 對每個標定的ground true box區域,與其重疊比例最大的anchor記為 正樣本 (保證每個ground true 至少對應一個正樣本anchor);
- 對1)剩餘的anchor,如果其與某個標定區域重疊比例大於0.7,記為正樣本(每個ground true box可能會對應多個正樣本anchor。但每個正樣本anchor 只可能對應一個grand true box);如果其與任意一個標定的重疊比例都小於0.3,記為負樣本。
- 對上面兩步剩餘的anchor,棄去不用;
- 跨越影象邊界的anchor棄去不用。
8. Faster-rcnn訓練策略
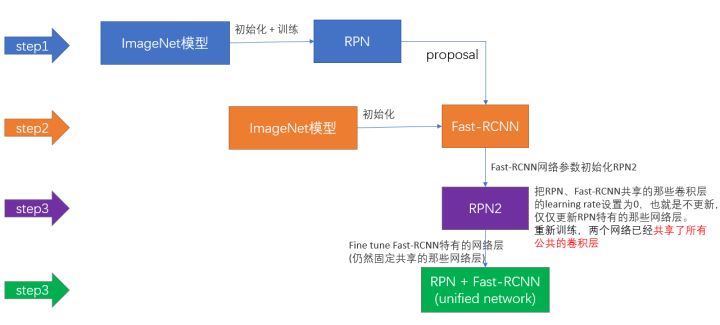
圖14 Faster-rcnn訓練策略
- 用ImageNet模型初始化,獨立訓練一個RPN網路;
- 仍然用ImageNet模型初始化,但是使用上一步RPN網路產生的proposal作為輸入,訓練一個Fast-RCNN網路,至此,兩個網路每一層的引數完全不共享;
- 使用第二步的Fast-RCNN網路引數初始化一個新的RPN網路,但是把RPN、Fast-RCNN共享的那些卷積層的learning rate設定為0,也就是不更新,僅僅更新RPN特有的那些網路層,重新訓練,此時,兩個網路已經共享了所有公共的卷積層;
- 仍然固定共享的那些網路層,把Fast-RCNN特有的網路層也加入進來,形成一個unified network,繼續訓練,fine tune Fast-RCNN特有的網路層,此時,該網路已經實現我們設想的目標,即網路內部預測proposal並實現檢測的功能。
即進行交替訓練,迭代2次的原因是作者發現多次的迭代並沒有顯著的改善效能。
四、總結
Faster-rcnn是一個目標檢測的baseline方法,值得你去仔細的研究,很建議你去實踐一下,這樣你可以更加清楚的瞭解到它的細節資訊。
最後,給大家介紹一個很好用的網路視覺化工具,專門用來視覺化.prototxt檔案,你可以將.prototxt檔案中的內容複製到該連結點選開啟連結,然後按下Shift+Enter,就可以看到漂亮的網路結構啦。如下所示:
圖14 caffe視覺化工具
參考文獻:
[1] Faster R-CNN: Down the rabbit hole of modern object detection,連結地址
[2] CNN目標檢測(一):Faster RCNN詳解,連結地址
[3] Faster R-CNN,連結地址
[4] 詳解 ROI Align 的基本原理和實現細節,連結地址
[5] NMS——非極大值抑制,連結地址
注意事項:
[1] 該部落格是本人原創部落格,如果您對該部落格感興趣,想要轉載該部落格,請與我聯絡(qq郵箱:[email protected]),我會在第一時間回覆大家,謝謝大家。
[2] 由於個人能力有限,該部落格可能存在很多的問題,希望大家能夠提出改進意見。
[3] 如果您在閱讀本部落格時遇到不理解的地方,希望可以聯絡我,我會及時的回覆您,和您交流想法和意見,謝謝。