
Faster RCNN詳解
↑↑↑↑目錄在這裡↑↑↑↑↑
Faster RCNN github : https://github.com/rbgirshick/py-faster-rcnn
Faster RCNN paper : https://arxiv.org/abs/1506.01497
Bound box regression詳解 : http://download.csdn.net/download/zy1034092330/9940097(來源:
縮排經過RCNN和Fast RCNN的積澱,Ross B. Girshick在2016年提出了新的Faster RCNN,在結構上,Faster RCN已經將特徵抽取(feature extraction),proposal提取,bounding box regression(rect refine),classification都整合在了一個網路中,使得綜合性能有較大提高,在檢測速度方面尤為明顯。
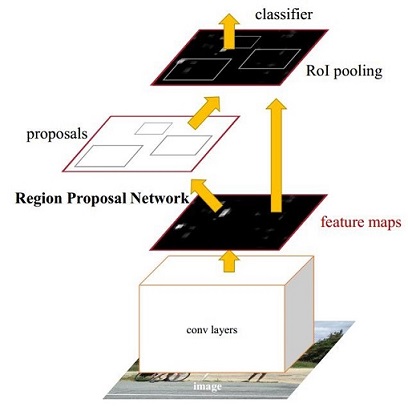
圖1 Faster CNN基本結構(來自原論文)
縮排依作者看來,如圖1,Faster RCNN其實可以分為4個主要內容:
- Conv layers。作為一種CNN網路目標檢測方法,Faster RCNN首先使用一組基礎的conv+relu+pooling層提取image的feature maps。該feature maps被共享用於後續RPN層和全連線層。
- Region Proposal Networks。RPN網路用於生成region proposals。該層通過softmax判斷anchors屬於foreground或者background,再利用bounding box regression修正anchors獲得精確的proposals。
- Roi Pooling。該層收集輸入的feature maps和proposals,綜合這些資訊後提取proposal feature maps,送入後續全連線層判定目標類別。
- Classification。利用proposal feature maps計算proposal的類別,同時再次bounding box regression獲得檢測框最終的精確位置。
所以本文以上述4個內容作為切入點介紹Faster RCNN網路。
縮排圖2展示了python版本中的VGG16模型中的faster_rcnn_test.pt的網路結構,可以清晰的看到該網路對於一副任意大小PxQ的影象,首先縮放至固定大小MxN,然後將MxN影象送入網路;而Conv layers中包含了13個conv層+13個relu層+4個pooling層;RPN網路首先經過3x3卷積,再分別生成foreground anchors與bounding box regression偏移量,然後計算出proposals;而Roi Pooling層則利用proposals從feature maps中提取proposal feature送入後續全連線和softmax網路作classification(即分類proposal到底是什麼object)。
path:${py-faster-rcnn-root}/models/pascal_voc/VGG16/faster_rcnn_alt_opt/faster_rcnn_test.pt
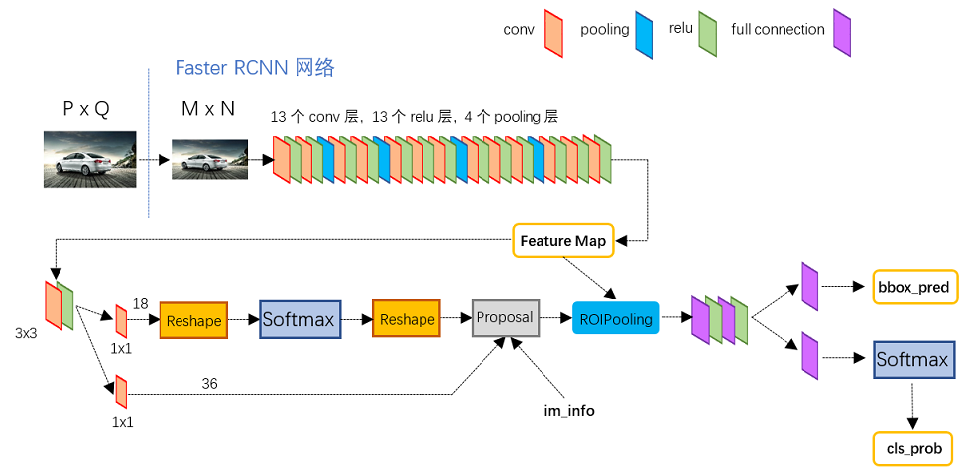
圖2 faster_rcnn_test.pt網路結構
1 Conv layers
縮排Conv layers包含了conv,pooling,relu三種層。以python版本中的VGG16模型中的faster_rcnn_test.pt的網路結構為例,如圖2,Conv layers部分共有13個conv層,13個relu層,4個pooling層。這裡有一個非常容易被忽略但是又無比重要的資訊,在Conv layers中:
- 所有的conv層都是:kernel_size=3,pad=1
- 所有的pooling層都是:kernel_size=2,stride=2
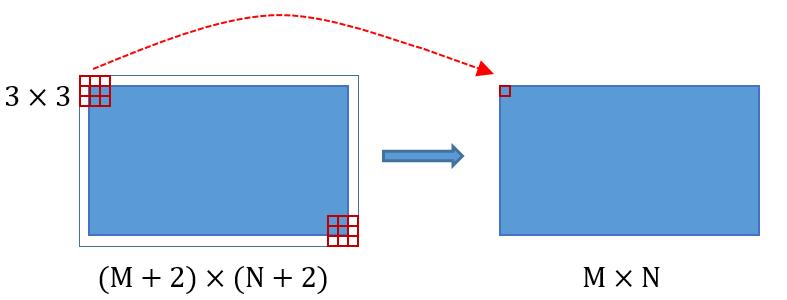
圖3
類似的是,Conv layers中的pooling層kernel_size=2,stride=2。這樣每個經過pooling層的MxN矩陣,都會變為(M/2)*(N/2)大小。綜上所述,在整個Conv layers中,conv和relu層不改變輸入輸出大小,只有pooling層使輸出長寬都變為輸入的1/2。
縮排那麼,一個MxN大小的矩陣經過Conv layers固定變為(M/16)x(N/16)!這樣Conv layers生成的featuure map中都可以和原圖對應起來。
2 Region Proposal Networks(RPN)
縮排經典的檢測方法生成檢測框都非常耗時,如OpenCV adaboost使用滑動視窗+影象金字塔生成檢測框;或如RCNN使用SS(Selective Search)方法生成檢測框。而Faster RCNN則拋棄了傳統的滑動視窗和SS方法,直接使用RPN生成檢測框,這也是Faster RCNN的巨大優勢,能極大提升檢測框的生成速度。
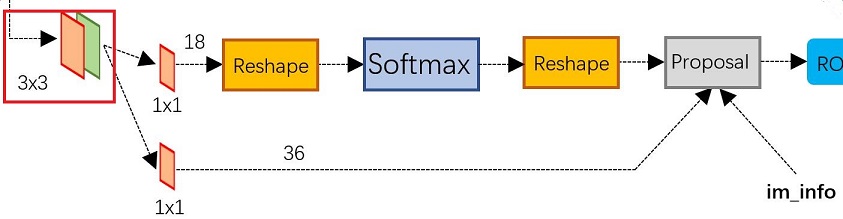
圖4 RPN網路結構
上圖4展示了RPN網路的具體結構。可以看到RPN網路實際分為2條線,上面一條通過softmax分類anchors獲得foreground和background(檢測目標是foreground),下面一條用於計算對於anchors的bounding box regression偏移量,以獲得精確的proposal。而最後的Proposal層則負責綜合foreground anchors和bounding box regression偏移量獲取proposals,同時剔除太小和超出邊界的proposals。其實整個網路到了Proposal Layer這裡,就完成了相當於目標定位的功能。
2.1 多通道影象卷積基礎知識介紹
縮排在介紹RPN前,還要多解釋幾句基礎知識,已經懂的看官老爺跳過就好。- 對於單通道影象+單卷積核做卷積,第一章中的圖3已經展示了;
- 對於多通道影象+多卷積核做卷積,計算方式如下:
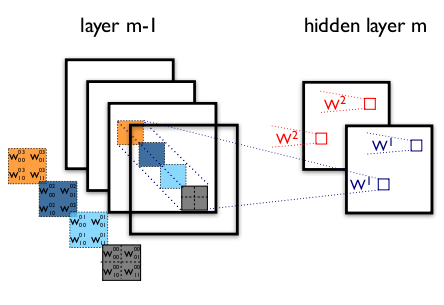
圖5 多通道+多卷積核做卷積示意圖(摘自Theano教程)縮排如圖5,輸入影象layer m-1有4個通道,同時有2個卷積核w1和w2。對於卷積核w1,先在輸入影象4個通道分別作卷積,再將4個通道結果加起來得到w1的卷積輸出;卷積核w2類似。所以對於某個卷積層,無論輸入影象有多少個通道,輸出影象通道數總是等於卷積核數量!縮排對多通道影象做1x1卷積,其實就是將輸入影象於每個通道乘以卷積係數後加在一起,即相當於把原影象中本來各個獨立的通道“聯通”在了一起。
2.2 anchors
縮排提到RPN網路,就不能不說anchors。所謂anchors,實際上就是一組由rpn/generate_anchors.py生成的矩形。直接執行作者demo中的generate_anchors.py可以得到以下輸出:
- [[ -84. -40.99.55.]
- [-176. -88.191.103.]
- [-360. -184.375.199.]
- [ -56. -56.71.71.]
- [-120. -120.135.135.]
- [-248. -248.263.263.]
- [ -36. -80.51.95.]
- [ -80. -168.95.183.]
- [-168. -344.183.359.]]
其中每行的4個值[x1,y1,x2,y2]代表矩形左上和右下角點座標。9個矩形共有3種形狀,長寬比為大約為:width:height = [1:1, 1:2, 2:1]三種,如圖6。實際上通過anchors就引入了檢測中常用到的多尺度方法。
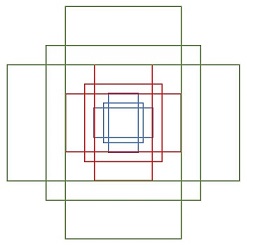
圖6 anchors示意圖
注:關於上面的anchors size,其實是根據檢測影象設定的。在python demo中,會把任意大小的輸入影象reshape成800x600(即圖2中的M=800,N=600)。再回頭來看anchors的大小,anchors中長寬1:2中最大為352x704,長寬2:1中最大736x384,基本是cover了800x600的各個尺度和形狀。
那麼這9個anchors是做什麼的呢?借用Faster RCNN論文中的原圖,如圖7,遍歷Conv layers計算獲得的feature maps,為每一個點都配備這9種anchors作為初始的檢測框。這樣做獲得檢測框很不準確,不用擔心,後面還有2次bounding box regression可以修正檢測框位置。
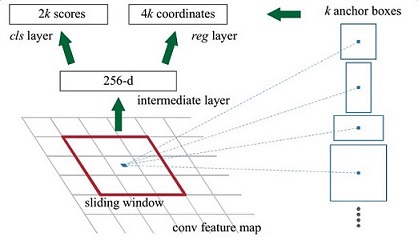
圖7
解釋一下上面這張圖的數字。
- 在原文中使用的是ZF model中,其Conv Layers中最後的conv5層num_output=256,對應生成256張特徵圖,所以相當於feature map每個點都是256-d
- 在conv5之後,做了rpn_conv/3x3卷積且num_output=256,相當於每個點又融合了周圍3x3的空間資訊(猜測這樣做也許更魯棒?反正我沒測試),同時256-d不變(如圖4和圖7中的紅框)
- 假設在conv5 feature map中每個點上有k個anchor(預設k=9),而每個anhcor要分foreground和background,所以每個點由256d feature轉化為cls=2k scores;而每個anchor都有[x, y, w, h]對應4個偏移量,所以reg=4k coordinates
- 補充一點,全部anchors拿去訓練太多了,訓練程式會在合適的anchors中隨機選取128個postive anchors+128個negative anchors進行訓練(什麼是合適的anchors下文5.1有解釋)
注意,在本文講解中使用的VGG conv5 num_output=512,所以是512d,其他類似.....
2.3 softmax判定foreground與background
縮排一副MxN大小的矩陣送入Faster RCNN網路後,到RPN網路變為(M/16)x(N/16),不妨設W=M/16,H=N/16。在進入reshape與softmax之前,先做了1x1卷積,如圖8: 圖8 RPN中判定fg/bg網路結構該1x1卷積的caffe prototxt定義如下:
圖8 RPN中判定fg/bg網路結構該1x1卷積的caffe prototxt定義如下:- layer {
- name: "rpn_cls_score"
- type: "Convolution"
- bottom: "rpn/output"
- top: "rpn_cls_score"
- convolution_param {
- num_output: 18 # 2(bg/fg) * 9(anchors)
- kernel_size: 1 pad: 0 stride: 1
- }
- }
- "Number of labels must match number of predictions; "
- "e.g., if softmax axis == 1 and prediction shape is (N, C, H, W), "
- "label count (number of labels) must be N*H*W, "
- "with integer values in {0, 1, ..., C-1}.";
2.4 bounding box regression原理
縮排介紹bounding box regression數學模型及原理。如圖9所示綠色框為飛機的Ground Truth(GT),紅色為提取的foreground anchors,那麼即便紅色的框被分類器識別為飛機,但是由於紅色的框定位不準,這張圖相當於沒有正確的檢測出飛機。所以我們希望採用一種方法對紅色的框進行微調,使得foreground anchors和GT更加接近。
圖9
縮排對於視窗一般使用四維向量(x, y, w, h)表示,分別表示視窗的中心點座標和寬高。對於圖 10,紅色的框A代表原始的Foreground Anchors,綠色的框G代表目標的GT,我們的目標是尋找一種關係,使得輸入原始的anchor A經過對映得到一個跟真實視窗G更接近的迴歸視窗G',即:給定anchor A=(Ax, Ay, Aw, Ah),GT=[Gx, Gy, Gw, Gh],尋找一種變換F:使得F(Ax, Ay, Aw, Ah)=(G'x, G'y, G'w, G'h),其中(G'x, G'y, G'w, G'h)≈(Gx, Gy, Gw, Gh)。
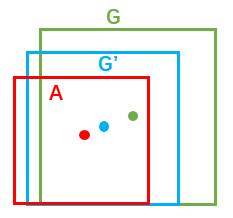
圖10
那麼經過何種變換F才能從圖6中的anchor A變為G'呢? 比較簡單的思路就是:
縮排 1. 先做平移
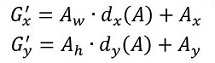
縮排 2. 再做縮放
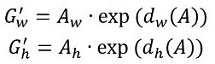
縮排觀察上面4個公式發現,需要學習的是dx(A),dy(A),dw(A),dh(A)這四個變換。當輸入的anchor A與GT相差較小時,可以認為這種變換是一種線性變換, 那麼就可以用線性迴歸來建模對視窗進行微調(注意,只有當anchors A和GT比較接近時,才能使用線性迴歸模型,否則就是複雜的非線性問題了)。對應於Faster RCNN原文,平移量(tx, ty)與尺度因子(tw, th)如下:

縮排接下來的問題就是如何通過線性迴歸獲得dx(A),dy(A),dw(A),dh(A)了。線性迴歸就是給定輸入的特徵向量X, 學習一組引數W, 使得經過線性迴歸後的值跟真實值Y非常接近,即Y=WX。對於該問題,輸入X是一張經過卷積獲得的feature map,定義為Φ;同時還有訓練傳入的GT,即(tx, ty, tw, th)。輸出是dx(A),dy(A),dw(A),dh(A)四個變換。那麼目標函式可以表示為:
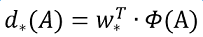
其中Φ(A)是對應anchor的feature map組成的特徵向量,w是需要學習的引數,d(A)是得到的預測值(*表示 x,y,w,h,也就是每一個變換對應一個上述目標函式)。為了讓預測值(tx, ty,tw,th)與真實值差距最小,設計損失函式:
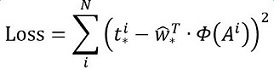
函式優化目標為:
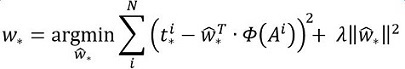
2.5 對proposals進行bounding box regression
縮排在瞭解bounding box regression後,再回頭來看RPN網路第二條線路,如圖11。

圖11 RPN中的bbox reg
先來看一看上圖11中1x1卷積的caffe prototxt定義:
- layer {
- name: "rpn_bbox_pred"
- type: "Convolution"
- bottom: "rpn/output"
- top: "rpn_bbox_pred"
- convolution_param {
- num_output: 36 # 4 * 9(anchors)
- kernel_size: 1 pad: 0 stride: 1
- }
- }
可以看到其num_output=36,即經過該卷積輸出影象為WxHx36,在caffe blob儲存為[1, 36, H, W],這裡相當於feature maps每個點都有9個anchors,每個anchors又都有4個用於迴歸的[dx(A),dy(A),dw(A),dh(A)]變換量。
2.6 Proposal Layer
縮排Proposal Layer負責綜合所有[dx(A),dy(A),dw(A),dh(A)]變換量和foreground anchors,計算出精準的proposal,送入後續RoI Pooling Layer。還是先來看看Proposal Layer的caffe prototxt定義:- layer {
- name: 'proposal'
- type: 'Python'
- bottom: 'rpn_cls_prob_reshape'
- bottom: 'rpn_bbox_pred'
- bottom: 'im_info'
- top: 'rois'
- python_param {
- module: 'rpn.proposal_layer'
- layer: 'ProposalLayer'
- param_str: "'feat_stride': 16"
- }
- }
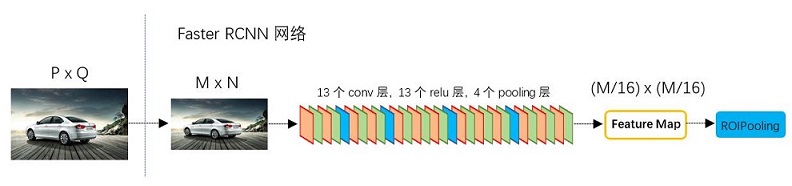 圖12縮排Proposal Layer forward(caffe layer的前傳函式)按照以下順序依次處理:
圖12縮排Proposal Layer forward(caffe layer的前傳函式)按照以下順序依次處理:- 生成anchors,利用[dx(A),dy(A),dw(A),dh(A)]對所有的anchors做bbox regression迴歸(這裡的anchors生成和訓練時完全一致)
- 按照輸入的foreground softmax scores由大到小排序anchors,提取前pre_nms_topN(e.g. 6000)個anchors,即提取修正位置後的foreground anchors。
- 利用im_info將fg anchors從MxN尺度映射回PxQ原圖,判斷fg anchors是否大範圍超過邊界,剔除嚴重超出邊界fg anchors。
- 進行nms(nonmaximum suppression,非極大值抑制)
- 再次按照nms後的foreground softmax scores由大到小排序fg anchors,提取前post_nms_topN(e.g. 300)結果作為proposal輸出。
3 RoI pooling
縮排而RoI Pooling層則負責收集proposal,並計算出proposal feature maps,送入後續網路。從圖3中可以看到Rol pooling層有2個輸入:
- 原始的feature maps
- RPN輸出的proposal boxes(大小各不相同)
3.1 為何需要RoI Pooling
縮排先來看一個問題:對於傳統的CNN(如AlexNet,VGG),當網路訓練好後輸入的影象尺寸必須是固定值,同時網路輸出也是固定大小的vector or matrix。如果輸入影象大小不定,這個問題就變得比較麻煩。有2種解決辦法:
- 從影象中crop一部分傳入網路
- 將影象warp成需要的大小後傳入網路

圖13 crop與warp破壞影象原有結構資訊
兩種辦法的示意圖如圖13,可以看到無論採取那種辦法都不好,要麼crop後破壞了影象的完整結構,要麼warp破壞了影象原始形狀資訊。回憶RPN網路生成的proposals的方法:對foreground anchors進行bound box regression,那麼這樣獲得的proposals也是大小形狀各不相同,即也存在上述問題。所以Faster RCNN中提出了RoI Pooling解決這個問題(需要說明,RoI Pooling確實是從SPP發展而來,但是限於篇幅這裡略去不講,有興趣的讀者可以自行查閱相關論文)。
3.2 RoI Pooling原理
縮排分析之前先來看看RoI Pooling Layer的caffe prototxt的定義:
- layer {
- name: "roi_pool5"
- type: "ROIPooling"
- bottom: "conv5_3"
- bottom: "rois"
- top: "pool5"
- roi_pooling_param {
- pooled_w: 7
- pooled_h: 7
- spatial_scale: 0.0625 # 1/16
- }
- }
其中有新引數pooled_w=pooled_h=7,另外一個引數spatial_scale=1/16應該能夠猜出大概吧。
縮排RoI Pooling layer forward過程:在之前有明確提到:proposal=[x1, y1, x2, y2]是對應MxN尺度的,所以首先使用spatial_scale引數將其映射回(M/16)x(N/16)大小的feature maps尺度(這裡來回多次對映,是有點繞);之後將每個proposal水平和豎直都分為7份,對每一份都進行max pooling處理。這樣處理後,即使大小不同的proposal,輸出結果都是7x7大小,實現了fixed-length output(固定長度輸出)。
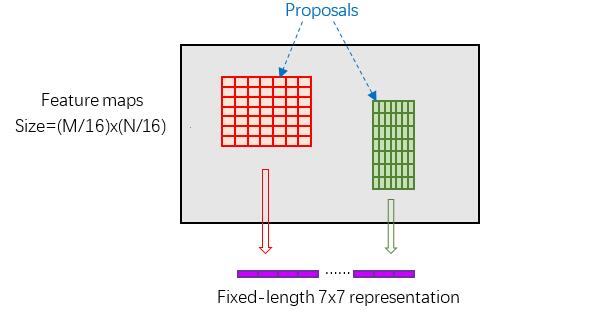
圖14 proposal示意圖
4 Classification
縮排Classification部分利用已經獲得的proposal feature maps,通過full connect層與softmax計算每個proposal具體屬於那個類別(如人,車,電視等),輸出cls_prob概率向量;同時再次利用bounding box regression獲得每個proposal的位置偏移量bbox_pred,用於迴歸更加精確的目標檢測框。Classification部分網路結構如圖15。
圖15 Classification部分網路結構圖
從PoI Pooling獲取到7x7=49大小的proposal feature maps後,送入後續網路,可以看到做了如下2件事:
- 通過全連線和softmax對proposals進行分類,這實際上已經是識別的範疇了
- 再次對proposals進行bounding box regression,獲取更高精度的rect box
圖16 全連線層示意圖
其計算公式如下:
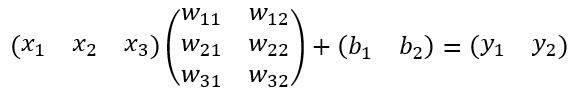
其中W和bias B都是預先訓練好的,即大小是固定的,當然輸入X和輸出Y也就是固定大小。所以,這也就印證了之前Roi Pooling的必要性。到這裡,我想其他內容已經很容易理解,不在贅述了。
5 Faster RCNN訓練
縮排Faster CNN的訓練,是在已經訓練好的model(如VGG_CNN_M_1024,VGG,ZF)的基礎上繼續進行訓練。實際中訓練過程分為6個步驟:- 在已經訓練好的model上,訓練RPN網路,對應stage1_rpn_train.pt
- 利用步驟1中訓練好的RPN網路,收集proposals,對應rpn_test.pt
- 第一次訓練Fast RCNN網路,對應stage1_fast_rcnn_train.pt
- 第二訓練RPN網路,對應stage2_rpn_train.pt
- 再次利用步驟4中訓練好的RPN網路,收集proposals,對應rpn_test.pt
- 第二次訓練Fast RCNN網路,對應stage2_fast_rcnn_train.pt
可以看到訓練過程類似於一種“迭代”的過程,不過只迴圈了2次。至於只迴圈了2次的原因是應為作者提到:"A similar alternating training can be run for more iterations, but we have observed negligible improvements",即迴圈更多次沒有提升了。接下來本章以上述6個步驟講解訓練過程。
5.1 訓練RPN網路
縮排在該步驟中,首先讀取RBG提供的預訓練好的model(本文使用VGG),開始迭代訓練。來看看stage1_rpn_train.pt網路結構,如圖17。
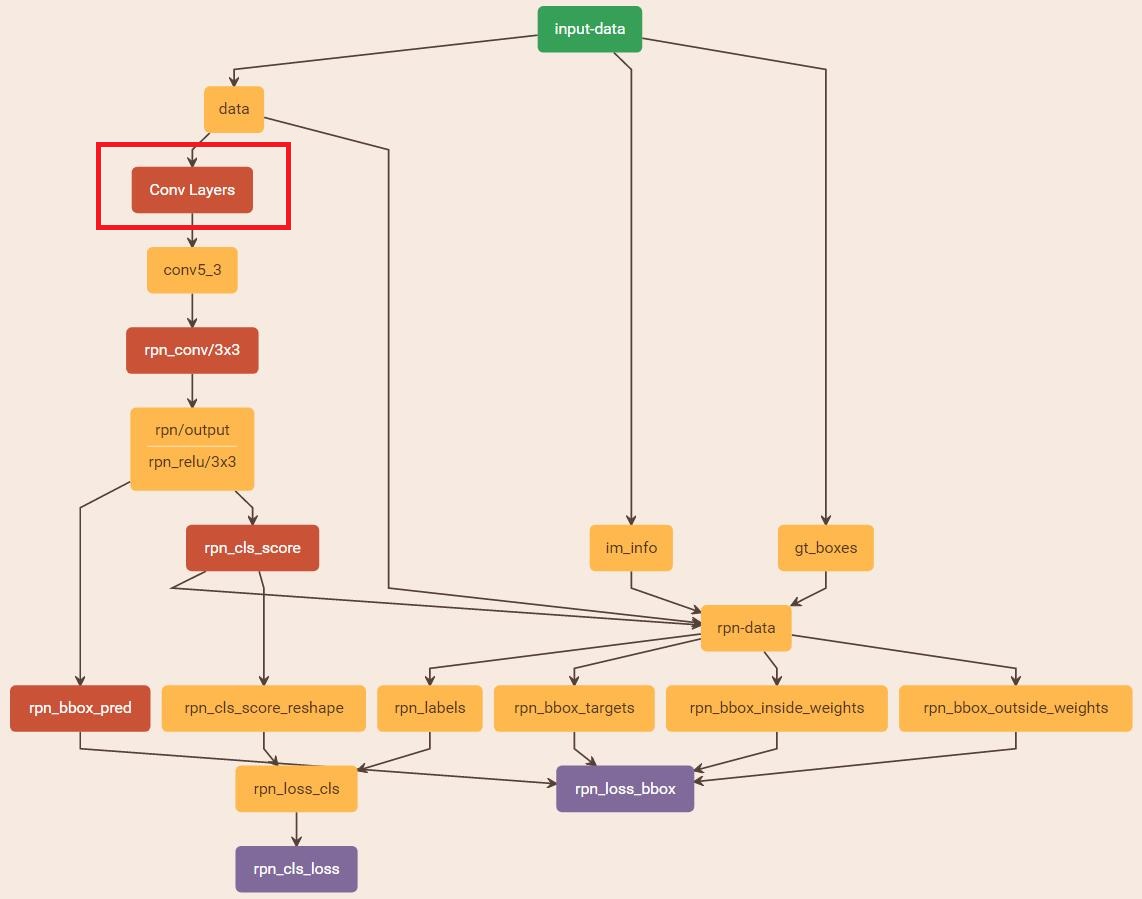
圖17 stage1_rpn_train.pt
(考慮圖片大小,Conv Layers中所有的層都畫在一起了,如紅圈所示,後續圖都如此處理)
與檢測網路類似的是,依然使用Conv Layers提取feature maps。整個網路使用的Loss如下:
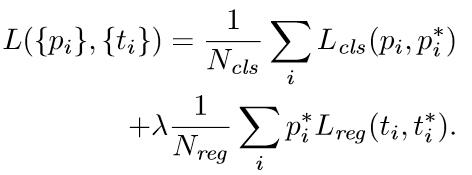
上述公式中,i表示anchors index,pi表示foreground softmax predict概率,pi*代表對應的GT predict概率(即當第i個anchor與GT間IoU>0.7,認為是該anchor是foreground,pi*=1;反之IoU<0.3時,認為是該anchor是background,pi*=0;至於那些0.3<IoU<0.7的anchor則不參與訓練);t代表predict bounding box,t*代表對應foreground anchor對應的GT box。可以看到,整個Loss分為2部分:
- cls loss,即rpn_cls_loss層計算的softmax loss,用於分類anchors為forground與background的網路訓練
- reg loss,即rpn_loss_bbox層計算的soomth L1 loss,用於bounding box regression網路訓練。注意在該loss中乘了pi*,相當於只關心foreground anchors的迴歸(其實在迴歸中也完全沒必要去關心background)。
縮排由於在實際過程中,Ncls和Nreg差距過大,用引數λ平衡二者(如Ncls=256,Nreg=2400時設定λ=10),使總的網路Loss計算過程中能夠均勻考慮2種Loss。這裡比較重要是Lreg使用的soomth L1 loss,計算公式如下:
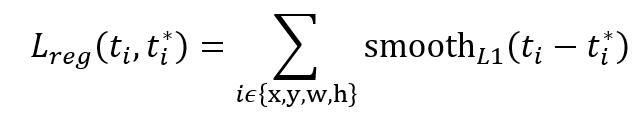

縮排瞭解數學原理後,反過來看圖17:
- 在RPN訓練階段,rpn-data(python AnchorTargetLayer)層會按照和test階段Proposal層完全一樣的方式生成Anchors用於訓練
- 對於rpn_loss_cls,輸入的rpn_cls_scors_reshape和rpn_labels分別對應p與p*,Ncls引數隱含在p與p*的caffe blob的大小中
- 對於rpn_loss_bbox,輸入的rpn_bbox_pred和rpn_bbox_targets分別對應t於t*,rpn_bbox_inside_weigths對應p*,rpn_bbox_outside_weights對應λ,Nreg同樣隱含在caffe blob大小中
這樣,公式與程式碼就完全對應了。特別需要注意的是,在訓練和檢測階段生成和儲存anchors的順序完全一樣,這樣訓練結果才能被用於檢測!
5.2 通過訓練好的RPN網路收集proposals
縮排在該步驟中,利用之前的RPN網路,獲取proposal rois,同時獲取foreground softmax probability,如圖18,然後將獲取的資訊儲存在python pickle檔案中。該網路本質上和檢測中的RPN網路一樣,沒有什麼區別。
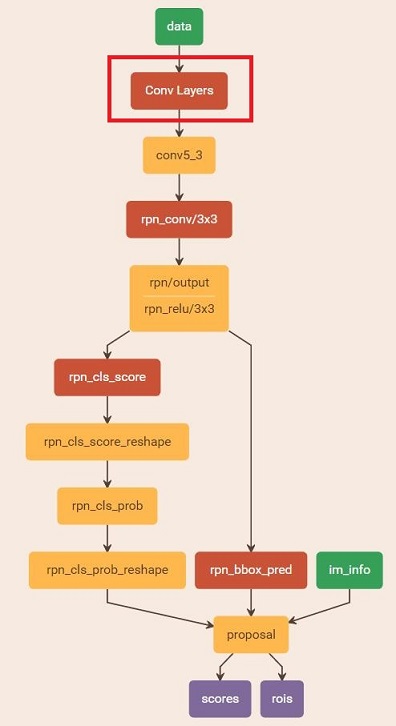 圖18 rpn_test.pt
圖18 rpn_test.pt5.3 訓練Fast RCNN網路
縮排讀取之前儲存的pickle檔案,獲取proposals與foreground probability。從data層輸入網路。然後:
- 將提取的proposals作為rois傳入網路,如圖19藍框
- 將foreground probability作為bbox_inside_weights傳入網路,如圖19綠框
- 通過caffe blob大小對比,計算出bbox_outside_weights(即λ),如圖19綠框
這樣就可以訓練最後的識別softmax與最終的bounding regression了,如圖19。
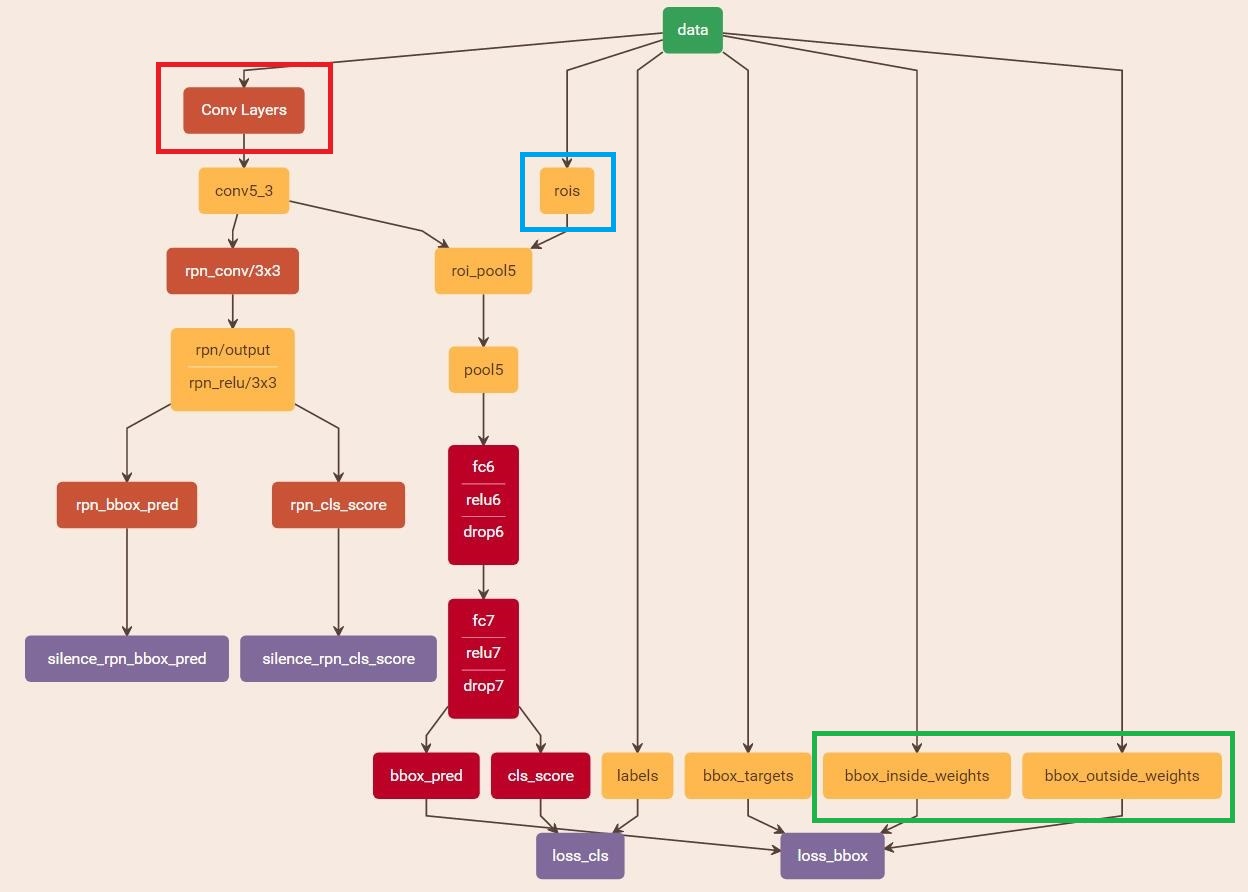
圖19 stage1_fast_rcnn_train.pt
之後的訓練都是大同小異,不再贅述了。
PS:我知道你們想問,畫圖工具:http://ethereon.github.io/netscope/#/editor
--------------------------------------------------------------------------
Faster RCNN的分析就結束了,之後會緩慢更新YOLO,YOLO V2,SSD,Mask RCNN等內容,敬請期待~
相關推薦
王權富貴:Faster-Rcnn詳解
背景 這一切始於 2014 年的一篇論文「Rich feature hierarchies for accurate object detection and semantic segmentation」(R-CNN),其使用了稱為 Selective Search 的演算法用來提取感興趣候選區
Faster-RCNN詳解
論文題目:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 論文連結:論文連結論文程式碼:Matlab版本點選此處,Python版本點選此處作為一個目標檢測領域的bas
Faster RCNN詳解:從region proposal到bounding box迴歸
一基於Region Proposal候選區域的深度學習目標檢測演算法 二R-CNNFast R-CNNFaster R-CNN三者關係 1 R-CNN目標檢測流程介紹 2 Fast R-CNN目標檢測流程介紹
RCNN系列之Faster RCNN詳解
RCNN系列:RCNN,SPPNet,Fast RCNN,Faster RCNN,R-FCN。這一系列是個遞進關係,也是目標檢測使用two-stage方法的一個發展過程。想要更好的理解Faster RCNN和R-FCN,只能把這些演算法都梳理清楚了,才能明白演算法的整個優化
CNN目標檢測(一):Faster RCNN詳解
轉自:http://blog.csdn.net/zy1034092330/article/details/62044941 經過RCNN和Fast RCNN的積澱,Ross B. Girshick在2016年提出了新的Faster RCNN,在結構上,Faster R
Faster RCNN詳解
↑↑↑↑目錄在這裡↑↑↑↑↑Faster RCNN github : https://github.com/rbgirshick/py-faster-rcnnFaster RCNN paper : https://arxiv.org/abs/1506.01497
RCNN系列之Fast RCNN詳解
轉自:https://blog.csdn.net/u010725283/article/details/79017158 RCNN系列:RCNN,SPPNet,Fast RCNN,Faster RCNN,R-FCN。這一系列是個遞進關係,也是目標檢測使用two-stag
【轉】mask-rcnn詳解
《Mask R-CNN》 進行例項分割,就是要在每一個畫素上都表示出來目標所屬的具體類別。 完成類別檢測,影象分割和特徵點定位。 1、解決的問題:在時間上對faster rcnn進行了優化,並且提高準確度,最關鍵的是在畫素級別進行特徵點定位達到了將各個物件的邊緣確定的效果。 上圖是,faster rcn
Faster RCNN原理詳解
圖1 Fa
Faster-RCNN論文詳解
Faster-RCNN 提出了Region Proposal Network(RPN)一個全連線的卷積層可以同時預測目標邊界和目標分數(物體) 把RPN和Fast-RCNN合併為一個網路通過共享他們的卷積特徵——使用帶有"attention"機制的神經網路 聯合網路un
【目標檢測】Faster RCNN演算法詳解
Ren, Shaoqing, et al. “Faster R-CNN: Towards real-time object detection with region proposal networks.” Advances in Neural Information P
faster-rcnn-tf版網路流程詳解
faster-rcnn論文連線:https://arxiv.org/pdf/1506.01497.pdf 程式碼地址:https://github.com/zacks417/faster-rcnn-tf 按照論文思路並參考了其他版本的原始碼,這版程式碼是我加過註釋的tf版本,在我自己的電腦上
faster-RCNN演算法原理詳解
縮排經過RCNN和Fast RCNN的積澱,Ross B. Girshick在2016年提出了新的Faster RCNN,在結構上,Faster RCN已經將特徵抽取(feature extraction),proposal提取,bounding box regr
Faster RCNN程式碼詳解(三):資料處理的整體結構
在上一篇部落格中介紹了Faster RCNN網路結構的構建:Faster RCNN程式碼詳解(二):網路結構構建。網路結構是Faster RCNN演算法中最重要兩部分之一,這篇部落格將介紹非常重要的另一部分:資料處理。 資料處理是通過AnchorLoader類
Faster RCNN程式碼詳解(四):關於anchor的前世今生
在上一篇部落格中介紹了資料處理的整體結構:Faster RCNN程式碼詳解(三):資料處理的整體結構。這一篇部落格介紹資料處理的細節——關於anchor的前世今生,程式碼在指令碼的:~/mx-rcnn/rcnn/io/rpn.py的assign_anchor函式
Ubuntu下跑通py-faster-rcnn、詳解demo運作流程
在不同的伺服器不同的機器上做過很多次實驗,分別遇到各種不一樣的錯誤並且跑通Py-Faster-RCNN,因此,在這裡做一個流程的彙總: 一、下載檔案: 首先,檔案的下載可以有兩種途徑: 該方法的下載之後資料夾:py-faster-rcnn/caffe-fast-rcnn/
【Faster RCNN 】bounding box regression詳解
引言 在人臉檢測演算法如R-CNN、Fast RCNN中都用到了bounding box迴歸,迴歸的目標是使得預測的物體視窗向groundtruth視窗相接近。我一開始沒理解如何能迴歸出一個框來,看完下文就理解了 1. 為什麼要做Bounding-box regres
Faster RCNN 原理詳解
Conv layers。作為一種CNN網路目標檢測方法,Faster RCNN首先使用一組基礎的conv+relu+pooling層提取image的feature maps。該feature maps被共享用於後續RPN層和全連線層。 Region Proposal Networks。RPN網路用於生成re
Faster rcnn(1)--- RPN原理及程式碼詳解
一. 論文 二. RPN提出的目的 用cnn來提取proposal,替代原始的slective search;由於原始的selective search獲得proposal框的過程很費時,使用cnn提取後可以極大提高速度。 如何提高?用CNN直接產生
Faster R-CNN:詳解目標檢測的實現過程
最大的 中心 width 小數據 等等 eat tar 優先 博文 本文詳細解釋了 Faster R-CNN 的網絡架構和工作流,一步步帶領讀者理解目標檢測的工作原理,作者本人也提供了 Luminoth 實現,供大家參考。 Luminoth 實現:h