
針對HBase的Java GC調優
文章是由Intel的Java效能架構師(Java performance architect)Eric Kaczmared發表,用於探索如何對HBase進行Java GC調優,全文的測試基於YCSB 100% Read進行測試。
Apache HBase是一個有Apache基金會開源,提供Nosql 資料儲存的專案。通常和HDFS一起使用,HBase已被全世界廣泛引用。比如眾所周知的Facebook,Twitter,Yahoo等等。從開發者的角度看,HBase是一個在Google Bigtable之後的分散式,版本控制,非關係資料庫模型,對結構化資料進行分散式儲存的系統。HBase可以輕鬆的通過縱向(使用更好的伺服器)和橫向(使用更多的機器)擴充套件處理非常高的吞吐。
從使用者角度看,查詢的延遲非常重要。我們通過和使用者的合作,測試,除錯,優化HBase的工作負載,我們遇到很多關注第99個百分位操作延遲的使用者。這意味著從客戶端請求到結果範圍到客戶端的一次往返,要在100ms內結束。
延遲受幾個變數的影響。一個最具毀滅性和不可預測性的造成延遲的因素是JVM在GC時進行的停機“Stop the world(後面都用STW簡寫)”
為了復現,我們嘗試用Oracle jdk7u21 and jdk7u60 G1 收集器。伺服器的使用了Intel Xeon Ivy-bridge EP processors with Hyper-threading (40 logical processors). 256GB DDR3-1600 記憶體, 三塊400GB SSD本地磁碟
下面的圖片展示了在使用-XX:+UseG1GC -Xms100g -Xmx100g -XX:MaxGCPauseMillis=100在一小時100% read下情況。我們指定了收集器的堆大小和期望GC停機時間。 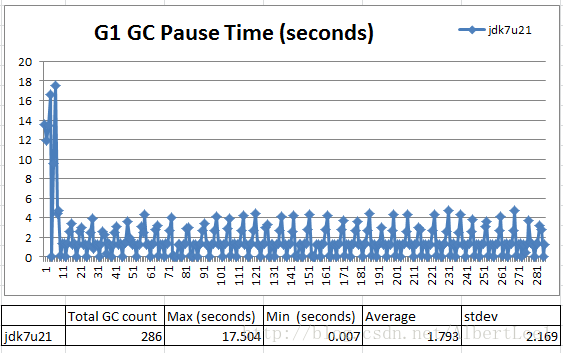
Figure 1: Wild swings in GC Pause time
在這種場景下,我們得到的GC停機時間浮動很大。GC停機時間在初始化時的峰值17.5s之後,從7ms到5s不等。
下面這張圖展示了在GC穩定期的更多細節。 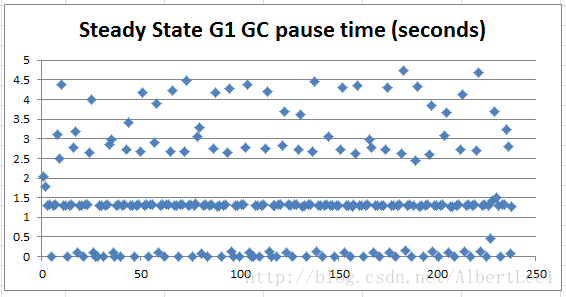
Figure 2: GC pause details, during steady state
上面這張圖告訴我們GC停機時間有三個浮動區間,(1)在1~1.5s之間,(2)在0.007~5s之間,(3)在1.5和5s間。挺奇怪的,所以我們使用更新的版本jdk7u60來看看會有什麼不同情況發生:
我們使用相同的100% read場景和相同的JVM引數測試:-XX:+UseG1GC -Xms100g -Xmx100g -XX:MaxGCPauseMillis=100 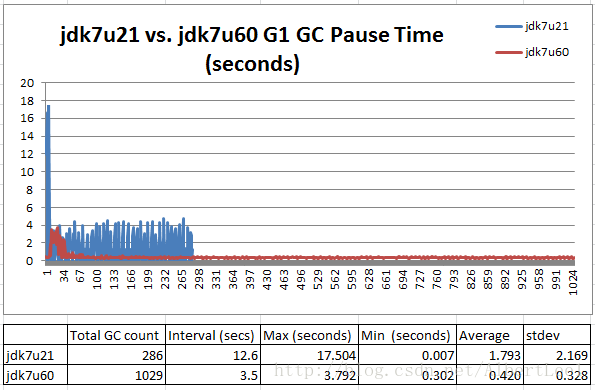
Figure 3: Greatly improved handling of pause time spikes
Jdk7u60能極大的提升GC停機時間的浮動。Jdk7u60在執行的這一小時當中共進行了1029次Young和Mixed GC。GC大約每3.5s進行一次。Jdk7u21進行了 286 次GC,每次大約12.6s。Jdk7u60可以將GC時間控制在0.3~1s之內,沒有太大的浮動。
圖4,展示了穩定狀態期間的150次GC 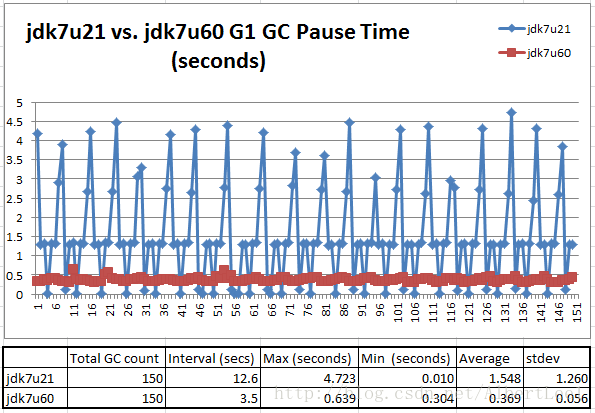
Figure 4: Better, but not good enough
在穩定期期間,jdk7u60可以將停機均值時間控制在369ms。比jdk7u21好太多,但是還不是通過–Xx:MaxGCPauseMillis=100配置的100ms以內。
為了確定通過其他的什麼方式我們才能得到100ms的停機時間,我們需要理解G1 記憶體管理行為上的更多細節。下面這張圖展示了G1 在Young代回時如何工作。 
Figure 5: Slide from the 2012 JavaOne presentation by Charlie Hunt and Monica Beckwith: “G1 Garbage Collector Performance Tuning”
當JVM基於引數啟動,它會向作業系統申請一大塊連續的記憶體空間來裝載JVM Heap。這個大塊連續的記憶體空間被分割成了JVM中的一個個Region。 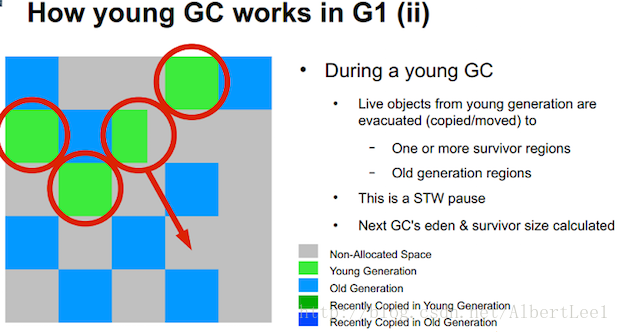
Figure 6: Slide from the 2012 JavaOne presentation by Charlie Hunt and Monica Beckwith: “G1 Garbage Collector Performance Tuning”
如圖6所示,每個通過Java API初始化的物件會被分配在Young代的Eden區左側。過一段時間,Eden區滿了,Young代GC被處罰。仍然有引用的物件會被拷貝到Survivor區。當物件通過這種方式存活幾次後,會被晉升到Old代空間。
當Young GC發生時,Java應用的執行緒會為了安全的標記和拷貝存活物件進行停機。這個停機就是臭名昭著的STW,會使得Java應用直到STW結束前都無相應。
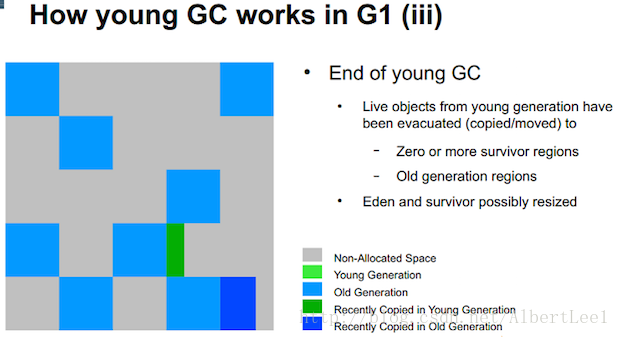
Figure 7: Slide from the 2012 JavaOne presentation by Charlie Hunt and Monica Beckwith: “G1 Garbage Collector Performance Tuning”
老年代也會變得擁擠。到達通過-XX:InitiatingHeapOccupancyPercent=?設定的一個程度後(預設值是45%),mixed GC被觸發。它同時收集Young代和Old代。Mixed GC的停機時間由Young代有多長的清理時間決定。
所以,我們 可以看到G1的STW由G1的標記和拷貝Eden區存活物件決定。考慮到這一點,我們來分析HBase記憶體分配模式如何幫助我們除錯G1 gc到我們的100ms期望停機時間。
在HBase中,有兩個在記憶體中的結構消費了絕大多數的heap空間。BlockCache快取讀操作的HFile block,Memstore快取近期的寫操作。 
Figure 8: In HBase, two in-memory structures consume most of its heap.
HBase預設的BlockCache實現是LruBlockCache,可以簡單地使用一個很大的byte陣列裝在所有的HBase Block。當Block被“驅逐(evicted)”,block引用的的java物件被刪除,允許GC重新分配記憶體。
LruBlockCache和Memstore中的新物件首先會被放在Young代。如果存活時間夠長(比如他們未被LruBlockCache驅逐或Memstore沒有flush操作),之後經過了幾次Young代GC,他們被晉升到了堆記憶體Old代。當Old代剩餘空間低於一個給定的threshOld閾值(InitiatingHeapOccupancyPercent控制),mixed GC在老年代清理出dead物件,從Young代將存活物件拷貝到老年代,並且重新計算Young代Eden區和Old代HeapOccupancyPercent使用情況,當到達HeapOccupancyPercent的程度,FULL GC被觸發,FULL GC會進行一次長時間的停機以清理掉Old代死掉的物件。
在學習了-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy列印的GC log後,我們注意到在100%讀場景下,堆記憶體從未到達HeapOccupancyPercent以產生一次Full GC。我們看到的GC停機是由Young代STW引起引用處理超時。
綜上所述,我們制定了預設G1 GC的三組修改:
1. 使用-XX:+ParallelRefProcEnabled
這個標識被開啟,GC使用多執行緒在Young和mixed GC期間處理增加的引用。HBase使用這個標記後,GC remarking時間減少了75%,整體GC停機時間減少了30%。
2. 配置-XX:-ResizePLAB and -XX:ParallelGCThreads=8+(logical processors-8)(5/8)
Promotion Local Allocation Buffers(PLABs)是在Young代回收時被使用。並且是多執行緒。每個需要分配空間的物件被拷貝到Survior或者Old代。PLABs 需要避免使用執行緒共享的資料結構為了管理空閒記憶體。每個GC執行緒有一個PLAB用於一個Survival區和一個Old區。我們需要重新配置PLAB的大小來避免GC執行緒間的大量通訊,這也是影響GC的一個變數。
3. 修改-XX:G1NewSizePercent,預設是100G HEAP的5%。因為使用了-XX:+PrintGCDetails and -XX:+PrintAdaptiveSizePolicy,我們注意到G1沒有達到100ms預期gc時間的原因是因為把時間花在了Eden上。換句話說,G1清空5GEden空間的均值是369ms。所以,我們使用-XX:G1NewSizePercent=修改Eden大小,從預設的5降到1。基於這個變更,我們看到GC停機時間減少到了100ms。
從這個實驗來看,我們發現G1清理Eden空間的速度是每1GB使用100ms,或者10GB每秒。
基於這個速度,我們配置-XX:G1NewSizePercent=使得Eden空間保持1GB左右。 例如:
- 32GB heap,-XX:G1NewSizePercent=3
- 64GB heap, -XX:G1NewSizePercent=2
- 100GB heap以上,-XX:G1NewSizePercent=1
- 所以,最後的HRegionServer引數確定為
- -XX:+UseG1GC
- -Xms100g -Xmx100g
- -XX:MaxGCPauseMillis=100
- –XX:+ParallelRefProcEnabled
- -XX:-ResizePLAB
- -XX:ParallelGCThreads= 8+(40-8)(5/8)=28
- -XX:G1NewSizePercent=1
下面是100% read執行1小時後,得到的GC圖:
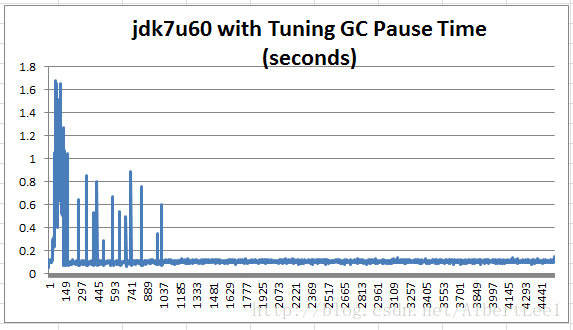
Figure 9: The highest initial settling spikes were reduced by more than half.
在圖裡,最高的波動從3.792s減少到了1.684s。初始化時的浮動減少了1s。修改過這些配置後,GC可以保持在100ms內。
下面這張圖對比了jdk7u60調優前和調優後,在穩定期的對比情況: 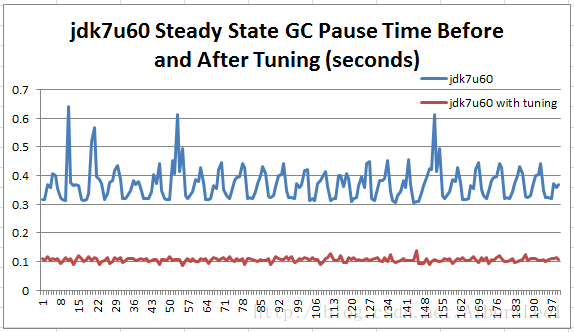
Figure 10: jdk7u60 runs with and without tuning, during steady state.
經過這個簡單的GC調優,我們得到了理想的GC停機時間,在100ms左右,106ms的均值,7ms的標準差。
總結
HBase是一個響應時間敏感,並且需要對GC時間可控的應用。通過jdk7u60,基於GC回收資訊命令-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy,我們可以除錯GC的停機時間到理想的100ms