
貝葉斯 演算法 理論
Bayes公式
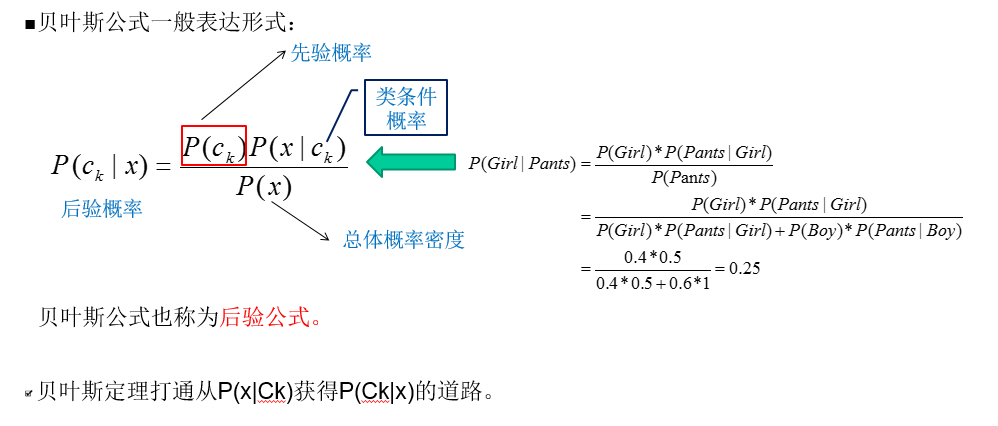
先驗概率和後驗概率

貝葉斯文字分類示例

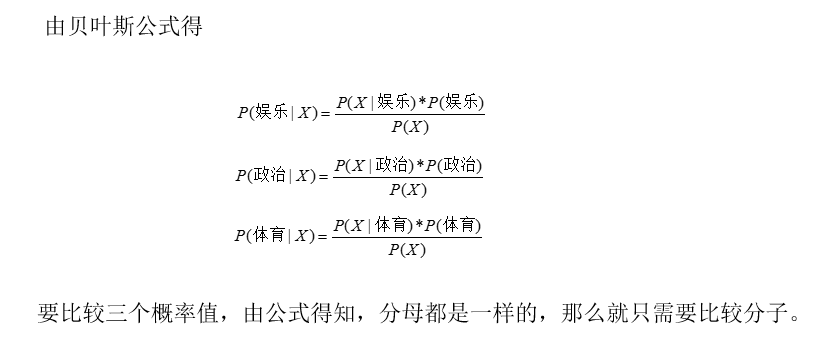



樸素貝葉斯分類決策



最小錯誤率決策

最小風險決策

最小風險貝葉斯決策—基本思想

最小風險貝葉斯決策—損失函式
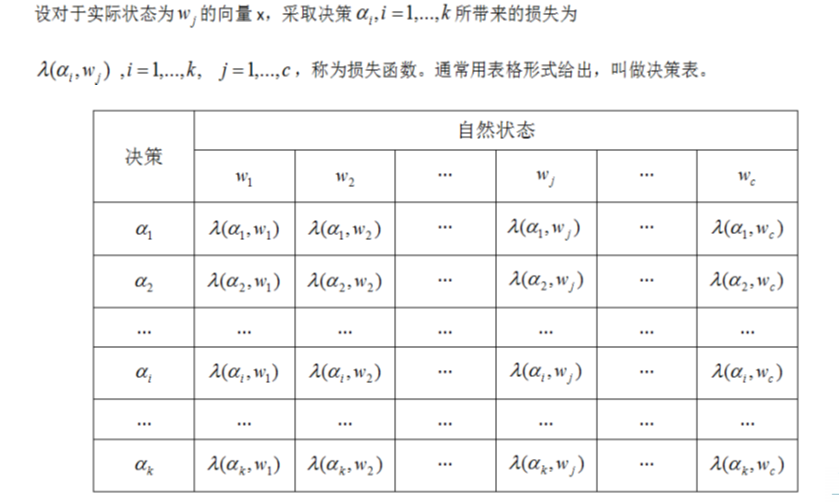

最小風險貝葉斯決策—步驟

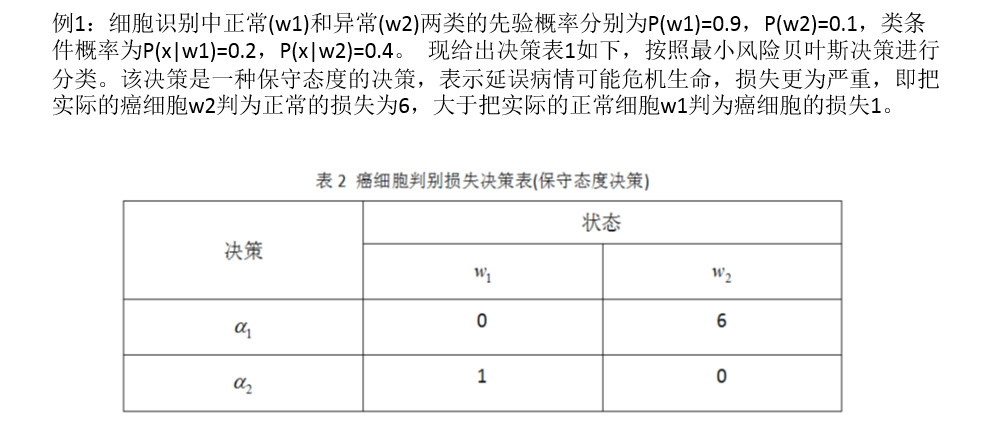
最小風險癌細胞例項

相關推薦
貝葉斯 演算法 理論
Bayes公式 先驗概率和後驗概率 貝葉斯文字分類示例 樸素貝葉斯分類決策 最小錯誤率決策 最小風險決策 最小風險貝葉斯決策—基本思想
機器學習裡的貝葉斯基本理論、模型和演算法
本文轉自中國人工智慧學會通訊第3期,已獲授權,特此感謝! 歡迎人工智慧領域技術投稿、約稿、給文章糾錯,請傳送郵件至[email protected] 3月3日,中國人工智慧學會AIDL第二期【人工智慧前沿講習班】在北京中科院自動化所舉
小白python學習——機器學習篇——樸素貝葉斯演算法
一.大概思路: 1.找出資料集合,所有一個單詞的集合,不重複,各個文件。 2.把每個文件換成0,1模型,出現的是1,就可以得到矩陣長度一樣的各個文件。 3.計算出3個概率,一是侮辱性的文件概率,二是侮辱性文件中各個詞出現的概率,三是非侮辱性文件中各個詞出現的概率。 4.二、三計算方法
樸素貝葉斯演算法原理
(作者:陳玓玏) 1. 損失函式 假設我們使用0-1損失函式,函式表示式如下: Y Y Y為真實
哈爾濱工業大學計算機學院-模式識別-課程總結-貝葉斯決策理論(一)
風險 沒有 關系 有關 href 屬性 決策 分類 tps 一、貝葉斯決策理論 貝葉斯決策理論是解決分類問題的一種基本統計途徑,其出發點是利用概率的不同分類決策,與相應決策所付出的代價進行折中,它假設決策問題可以用概率的形式描述,並且假設所有有關的概率結構均已知。 二、各種
【sklearn例項】1-貝葉斯演算法
問題 樸素貝葉斯求解 樸素貝葉斯公式: 求解思想:即求先驗概率與條件概率乘積的最大值 求解 注意: 本人求解過程中忘記了 Laplace 平滑 (⊙︿⊙),但好在預測值裡面沒有學歷為博士的一項,所以不平滑也不影響預測,但這樣是不規範的
樸素貝葉斯演算法應用——垃圾簡訊分類
理解貝葉斯公式其實就只要掌握:1、條件概率的定義;2、乘法原理 P (
機器學習——樸素貝葉斯演算法
概率定義為一件事情發生的可能性 概率分為聯合概率和條件概率 聯合概率:包含多個條件,且所有條件同時成立的概率 記作:P(A,B) P(A,B)=P(A)P(B) 條件概率:就是事件A在另外一個事件B已經發生的條件概率 記作:P(A|B)
機器學習實踐(九)—sklearn之樸素貝葉斯演算法
一、樸素貝葉斯演算法 什麼是樸素貝葉斯分類方法 屬於哪個類別概率大,就判斷屬於哪個類別 概率基礎 概率定義為一件事情發生的可能性 P(X) : 取值在[0, 1] 聯合概率、條件概率與相互獨立
樸素貝葉斯演算法優化與 sklearn 實現
1. 引言 上一篇日誌中,我們主要介紹了貝葉斯演算法,並提供了 python 實踐: 樸素貝葉斯演算法的推導與實踐 但執行上一篇日誌中的示例,我們發現出現了下面的結果: ['love', 'my', 'dalmation'] 屬於非侮辱類 ['stu
樸素貝葉斯演算法的推導與實踐
1. 概述 在此前的文章中,我們介紹了用於分類的演算法: k 近鄰演算法 決策樹的構建演算法 – ID3 與 C4.5 演算法 但是,有時我們無法非常明確地得到分類,例如當資料量非常大時,計算每個樣本與預測樣本之間的距
人工智慧初學- 1.2 最大似然估計及貝葉斯演算法
最大似然思想 最大似然法是一種具有理論性的引數估計方法。 基本思想是:當從模型總體隨機抽取n組樣本觀測值後,最合理的引數估計量應該使得從模型中抽取該n組樣本觀測值的概率最大。一般步驟包括: 寫出似然函式 對似然
機器學習——樸素貝葉斯演算法Python實現
簡介 這裡參考《統計學習方法》李航編進行學習總結。詳細演算法介紹參見書籍,這裡只說明關鍵內容。 即 條件獨立下:p{X=x|Y=y}=p{X1=x1|Y=y} * p{X2=x2|Y=y} *...* p{Xn=xn|Y=y} (4.4)等價於p{Y=ck|X=x
python資料分析與挖掘之貝葉斯演算法演算法實現
程式碼中有詳細的註釋 訓練檔案: Txt檔案中為0,1矩陣,將圖片轉換為0,1矩陣見上一篇部落格方法 import numpy import operator from os import listdir class Bayes: def __init__(self):
貝葉斯決策理論之入門篇
貝葉斯定理 首先是條件概率公式如下: P(A|B)=P(B|A)P(A)P(B)P(A|B)=P(B|A)P(A)P(B) 為了方便理解,可以參考下圖 已知兩個獨立事件AA和BB,那麼事件BB發生的前提下,事件AA發生的概率可以表示為P(A|B)
第3章 樸素貝葉斯演算法 (二 演算法實戰)
3.6樸素貝葉斯實踐 3.6.1樸素貝葉斯之微博評論篩選 以微博評論為例。為了不影響微博的發展,我們要遮蔽低俗的言論,所以要構建一個快速過濾器,如果某條評論使用了負面或者侮辱性等低俗的語言,那麼就將該留言標誌為內容不當。過濾這類內容是一個很常見的需求。對此問題建
機器學習系列文章:貝葉斯決策理論
引言 訓練計算機使之根據資料進行推斷是統計學和電腦科學的交叉領域,其中統計學家提供有資料做推斷的數學框架,而電腦科學家研究推斷方法如果在計算機上有效地實現。 資料來自於一個不完全清楚的過程,將該過程作為隨機過程建模表明我們缺乏知識。也許該過程實際上是確定性的,但
機器學習樸素貝葉斯演算法
樸素貝葉斯屬於監督學習的生成模型,實現簡單,沒有迭代,學習效率高,在大樣本量下會有較好表現。但因為假設太強——特徵條件獨立,在輸入向量的特徵條件有關聯的場景下,並不適用。 樸素貝葉斯演算法:主要思路是通過聯合概率建模,運用貝葉斯定理求解後驗概率;將後驗概率最大者對應的類別作
機器學習學習筆記 第十五章 貝葉斯演算法
貝葉斯演算法 貝葉斯要解決的問題 正向概率 逆向概率 舉例:一個班級中,男生 60%,女生 40%,男生總是穿長褲,女生則一半穿長褲一半穿裙子 正向概率:隨機選取一個學生,他(她)穿長褲的概率和穿
【ML學習筆記】樸素貝葉斯演算法的demo(機器學習實戰例子)
礙於這學期課程的緊迫,現在需要儘快從課本上掌握一些ML演算法,我本不想經過danger zone,現在看來卻只能儘快進入danger zone,數學理論上的缺陷只能後面找時間彌補了。 如果你在讀這篇文章,希望你不要走像我一樣的道路,此舉實在是出於無奈,儘量不要去做一個心