
Machine Learning第七講SVM -- (三)SVM在實踐中的應用
Using SVM in Practice(SVM在實踐中的應用)
在實際應用中,並不推薦 自己寫SVM的演算法,可以使用別人已經寫好的,那我們需要做什麼呢?
如下圖:
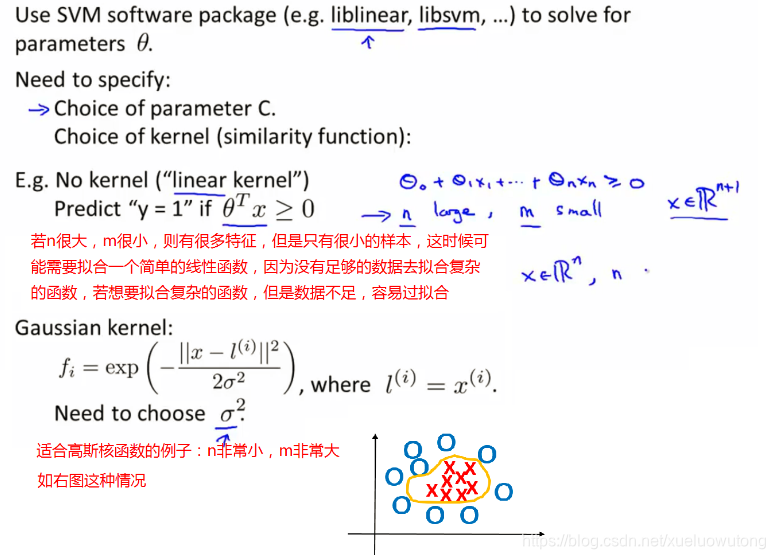
對於核函式的選型,我們一般會選擇線性核函式和高斯核函式。
一般情況下,我們需要自己提供核函式,必要的時間需要做歸一化:

其他核函式的選擇?

多元分類中SVM演算法的應用:

logistic迴歸演算法、神經網路和SVM的比較?

可能我們在遇到實際問題時,還是不知道應該選擇哪一種演算法,沒關係,我們之前講過最後決定結果的是資料集的大小、調優引數等因素,但是SVM仍然是比較高效的一個演算法。
相關推薦
Machine Learning第三講[Logistic迴歸] --(三)多元分類
內容來自Andrew老師課程Machine Learning的第三章內容的Multiclass Classification部分。 一、Multiclass Classification: One-vs-all(多元分類:一對多) (1)下圖左邊是二元分類的
Machine Learning第七講SVM -- (三)SVM在實踐中的應用
Using SVM in Practice(SVM在實踐中的應用) 在實際應用中,並不推薦 自己寫SVM的演算法,可以使用別人已經寫好的,那我們需要做什麼呢? 如下圖: 對於核函式的選型,我們一般會選擇線性核函式和高斯核函式。 一般情況下,我們需要自己提供核函式,必
Machine Learning第七講SVM --(二)核函式
一、Kernels I(核函式I) 在非線性函式中,假設函式為: 將表示式改變一下,將其寫為: 聯想到上次講到的計算機視覺的例子,因為需要很多畫素點,因此若f用這些高階函式表示,則計算量將會很大,那麼對於我們有沒有更好的選擇呢? 由此引入核函式的概念。 對於給定
Machine Learning 第七講SVM -- (一)最大間隔分類
一、Optimization Objective(SVM優化目標) 在logistic迴歸模型中,g(z)=1/(1+e^(-z)),其函式影象如下: 在這基礎上,若logistic迴歸只有一個樣本,則Cost函式如下圖所示: (1)在y=1的情況下,只剩下Cost的左
Machine Learning第九講【異常檢測】-- (三)多元高斯分佈
一、Multivariate Gaussian Distribution(多元高斯分佈) 資料中心例子: 因為上面的原因,會帶來一些誤差,因此我們引入了改良版的演算法: 我們不再單獨地將p(x1),p(x2),p(x3)訓練模型,而是將這些引數都放在一個模型裡,
Machine Learning第八講【非監督學習】--(三)主成分分析(PCA)
一、Principal Component Analysis Problem Formulation(主成分分析構思) 首先來看一下PCA的基本原理: PCA會選擇投影誤差最小的一條線,由圖中可以看出,當這條線是我們所求時,投影誤差比較小,而投影誤差比較大時,一定是這條線偏離最優直線。
Machine Learning第六講[應用機器學習的建議] --(三)建立一個垃圾郵件分類器
內容來自Andrew老師課程Machine Learning的第六章內容的Building a Spam Classifier部分。 一、Prioritizing What to Work on(優
Machine Learning第九講【推薦系統】-- (二)協同過濾
一、Collaborative Filtering(協同過濾) 協同過濾能夠自行學習所需要使用的特徵。 來看下面的例子: 在之前講的基於內容的推薦系統中,我們需要事先建立特徵並知道特徵值,這是比較困難的。 假設我們某一使用者的喜好,即假如Alice、Bob喜歡romance的電影,carol
Machine Learning第九講【推薦系統】--(一)基於內容的推薦系統
符號介紹: 對於每一個使用者j,假設我們已經通過學習找到引數,則使用者j對電影i的評分預測值為:。 對於上面的例子:
Machine Learning第九講【異常檢測】-- (二)建立一個異常檢測系統
一、Developing and Evaluating an Anomaly Detection System(異常檢測系統的衡量指標) 對於某一演算法,我們可以通過藉助某些數字指標來衡量演算法的好壞,仍舊以飛機引擎的例子來說: 假設有10000個正常的引擎,20個有瑕疵的引擎(異常)
Machine Learning第九講【異常檢測】--(一)密度估計
一、Problem Motivation(問題引入) 異常檢測一般應用在非監督學習的問題上,如圖,我們可以通過已知的資料集,訓練模型 根據此模型進行異常檢測: 在使用這些資料訓練的過程中,我們假設這些資料是正常的。 我們可以把異常檢測應用在網站欺詐預測上,比如可以根據使用者平時
Machine Learning第八講【非監督學習】-- (四)PCA應用
一、Reconstruction from Compressed Representation(壓縮特徵的復原) 本部分主要講我們如何將已經壓縮過的特徵復原成原來的,如下圖: 左邊的二維圖是未縮減維數之前的情況,下面的一維圖是利用縮減之後的情況,我們利用公式可以得到x的近似值,如右圖,
Machine Learning第八講【非監督學習】-- (二)動因
一、Motivation I: Data Compression(動因I:資料壓縮) 下面是2個降維處理的例項: 例項1:將cm和inch的2維資料降成1維資料: 例項2:降3維資料降成2維資料: 二、Motivation II: Visualization(動因II:視
Machine Learning第八講[非監督學習] -- (一)聚類
一、Unsupervised Learning: Introduction(非監督學習簡介) 之前介紹的線性迴歸、logistic迴歸以及神經網路等都是監督學習的例子,通過給出一系統樣本,通過這些樣本去訓練模型進行預測,在這些樣本中,是包含y標籤的,即實際值。 在非監督學習中,我們給一系列樣
Machine Learning第六講[應用機器學習的建議] --(二)診斷偏差和方差
一、Diagnosing Bias vs. Variance(診斷偏差 vs. 方差) 如果一個演算法表現的不理想,多半是出現兩種情況,一種情況是偏差比較大(這種情況是欠擬合情況),另一種是方差比較大(這種情況是過擬合的情況)。下圖是欠擬合、剛好、過擬合三種情況的Size-price圖(仍然是預
SLAM從入門到放棄:SLAM十四講第七章習題(9)
以下均為簡單筆記,如有錯誤,請多多指教。 使用Sophus的SE3類,自己設計g2o的節點與邊,實現PnP和ICP的優化。 答:對於PnP問題,需要重新設計的節點包括相機節點、Landmark節點和一
SLAM從入門到放棄:SLAM十四講第七章習題(10)
以下均為簡單筆記,如有錯誤,請多多指教。 在Ceres中實現PnP和ICP的優化。 答:程式碼如下,其結果與g2o差異不大。不過感覺程式碼看起來更加簡潔,個人比較喜歡ceres。 PnP IC
Machine Learning第十講【大規模機器學習】
本部分主要包括如下內容: Learning With Large Datasets (大資料集訓練模型) Stochastic Gradient Descent (隨機梯度下降演算法) &n
陳越《資料結構》第七講 圖(中)二
最短路徑問題 定義: 在網路中,求兩個不同頂點之間的所有路徑中,邊的權值之和最小的那一條路徑。這條路徑就是兩點之間的 最短路徑(Shortest Path)。 - 第一個頂點為 源點
Machine Learning — 關於過度擬合(Overfitting)
機器學習 gis ear http 問題 正則化 數據集 技術 wid 機器學習是在模型空間中選擇最優模型的過程,所謂最優模型,及可以很好地擬合已有數據集,並且正確預測未知數據。 那麽如何評價一個模型的優劣的,用代價函數(Cost function)來度量預測錯誤的程度。代