R-CNN論文詳解
廢話不多說,上車吧,少年
&創新點
採用CNN網路提取影象特徵,從經驗驅動的人造特徵正規化HOG、SIFT到資料驅動的表示學習正規化,提高特徵對樣本的表示能力;
採用大樣本下有監督預訓練+小樣本微調的方式解決小樣本難以訓練甚至過擬合等問題。
&問題是什麼
近10年以來,以人工經驗特徵為主導的物體檢測任務mAP【物體類別和位置的平均精度】提升緩慢;
隨著ReLu激勵函式、dropout正則化手段和大規模影象樣本集ILSVRC的出現,在2012年ImageNet大規模視覺識別挑戰賽中,Hinton及他的學生採用CNN特徵獲得了最高的影象識別精確度;
上述比賽後,引發了一股“是否可以採用CNN特徵來提高當前一直停滯不前的物體檢測準確率“的熱潮。
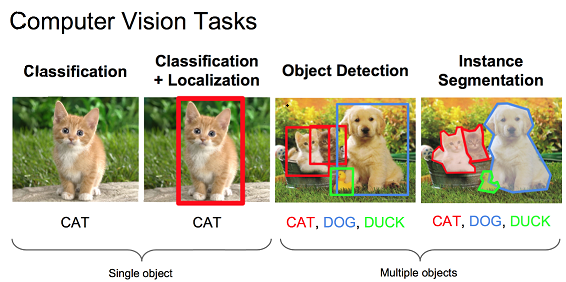
【寫給小白:一圖理解影象分類,影象定位,目標檢測和例項分割】
&如何解決問題
。測試過程
輸入一張多目標影象,採用selective search演算法提取約2000個建議框;
先在每個建議框周圍加上16個畫素值為建議框畫素平均值的邊框,再直接變形為227×227的大小;
先將所有建議框畫素減去該建議框畫素平均值後【預處理操作】,再依次將每個227×227的建議框輸入AlexNet CNN網路獲取4096維的特徵【比以前的人工經驗特徵低兩個數量級】,2000個建議框的CNN特徵組合成2000×4096維矩陣;
將2000×4096維特徵與20個SVM組成的權值矩陣4096×20相乘【20種分類,SVM是二分類器,則有20個SVM
】,獲得2000×20維矩陣表示每個建議框是某個物體類別的得分;分別對上述2000×20維矩陣中每一列即每一類進行非極大值抑制剔除重疊建議框,得到該列即該類中得分最高的一些建議框;
分別用20個迴歸器對上述20個類別中剩餘的建議框進行迴歸操作,最終得到每個類別的修正後的得分最高的bounding box。
。解釋分析
selective search
採取過分割手段,將影象分割成小區域,再通過顏色直方圖,梯度直方圖相近等規則進行合併,最後生成約2000個建議框的操作,具體見部落格。為什麼要將建議框變形為227×227?怎麼做?
本文采用AlexNet CNN網路進行CNN特徵提取,為了適應AlexNet網路的輸入影象大小:227×227,故將所有建議框變形為227×227。
那麼問題來了,如何進行變形操作呢?作者在補充材料中給出了四種變形方式:① 考慮context【影象中context指RoI周邊畫素】的各向同性變形,建議框像周圍畫素擴充到227×227,若遇到影象邊界則用建議框畫素均值填充,下圖第二列;
② 不考慮context的各向同性變形,直接用建議框畫素均值填充至227×227,下圖第三列;
③ 各向異性變形,簡單粗暴對影象就行縮放至227×227,下圖第四列;
④ 變形前先進行邊界畫素填充【padding】處理,即向外擴充套件建議框邊界,以上三種方法中分別採用padding=0下圖第一行,padding=16下圖第二行進行處理;經過作者一系列實驗表明採用padding=16的各向異性變形即下圖第二行第三列效果最好,能使mAP提升3-5%。
CNN特徵如何視覺化?
文中採用了巧妙的方式將AlexNet CNN網路中Pool5層特徵進行了視覺化。該層的size是6×6×256,即有256種表示不同的特徵,這相當於原始227×227圖片中有256種195×195的感受視野【相當於對227×227的輸入影象,卷積核大小為195×195,padding=4,step=8,輸出大小(227-195+2×4)/8+1=6×6】;
文中將這些特徵視為”物體檢測器”,輸入10million的Region Proposal集合,計算每種6×6特徵即“物體檢測器”的啟用量,之後進行非極大值抑制【下面解釋】,最後展示出每種6×6特徵即“物體檢測器”前幾個得分最高的Region Proposal,從而給出了這種6×6的特徵圖表示了什麼紋理、結構,很有意思。為什麼要進行非極大值抑制?非極大值抑制又如何操作?
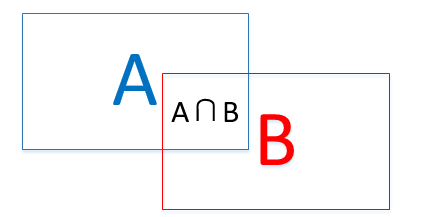
先解釋什麼叫IoU。如下圖所示IoU即表示(A∩B)/(A∪B)
在測試過程完成到第4步之後,獲得2000×20維矩陣表示每個建議框是某個物體類別的得分情況,此時會遇到下圖所示情況,同一個車輛目標會被多個建議框包圍,這時需要非極大值抑制操作去除得分較低的候選框以減少重疊框。
具體怎麼做呢?
① 對2000×20維矩陣中每列按從大到小進行排序;
② 從每列最大的得分建議框開始,分別與該列後面的得分建議框進行IoU計算,若IoU>閾值,則剔除得分較小的建議框,否則認為影象中存在多個同一類物體;
③ 從每列次大的得分建議框開始,重複步驟②;
④ 重複步驟③直到遍歷完該列所有建議框;
⑤ 遍歷完2000×20維矩陣所有列,即所有物體種類都做一遍非極大值抑制;
⑥ 最後剔除各個類別中剩餘建議框得分少於該類別閾值的建議框。【文中沒有講,博主覺得有必要做】為什麼要採用迴歸器?迴歸器是什麼有什麼用?如何進行操作?
首先要明確目標檢測不僅是要對目標進行識別,還要完成定位任務,所以最終獲得的bounding-box也決定了目標檢測的精度。
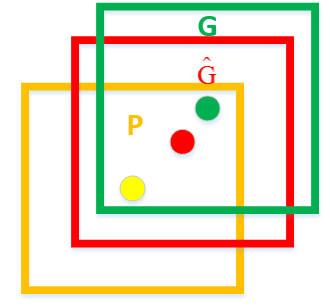
這裡先解釋一下什麼叫定位精度:定位精度可以用演算法得出的物體檢測框與實際標註的物體邊界框的IoU值來近似表示。如下圖所示,綠色框為實際標準的卡宴車輛框,即Ground Truth;黃色框為selective search演算法得出的建議框,即Region Proposal。即使黃色框中物體被分類器識別為卡宴車輛,但是由於綠色框和黃色框IoU值並不大,所以最後的目標檢測精度並不高。採用迴歸器是為了對建議框進行校正,使得校正後的Region Proposal與selective search更接近, 以提高最終的檢測精度。論文中採用bounding-box迴歸使mAP提高了3~4%。
那麼問題來了,迴歸器如何設計呢?
如上圖,黃色框口P表示建議框Region Proposal,綠色視窗G表示實際框Ground Truth,紅色視窗G^ 表示Region Proposal進行迴歸後的預測視窗,現在的目標是找到P到G^ 的線性變換【當Region Proposal與Ground Truth的IoU>0.6時可以認為是線性變換】,使得G^ 與G越相近,這就相當於一個簡單的可以用最小二乘法解決的線性迴歸問題,具體往下看。
讓我們先來定義P視窗的數學表示式:Pi=(Pix,Piy,Piw,Pih) ,其中(Pix,Piy) 表示第一個i視窗的中心點座標,Piw ,Pih 分別為第i個視窗的寬和高;G視窗的數學表示式為:Gi=(Gix,Giy,Giw,Gih) ;G^ 視窗的數學表示式為:G^i=(G^ix,G^iy,G^iw,G^ih) 。以下省去i上標。
這裡定義了四種變換函式,dx(P) ,dy(P) ,dw(P) ,dh(P) 。dx(P) 和dy(P) 通過平移對x和y進行變化,dw(P) 和dh(P) 通過縮放對w和h進行變化,即下面四個式子所示:
G^x=Pwdx(P)+Px(1) G^y=Phdy(P)+Py(2) G^w=Pwexp(dw(P))(3) 相關推薦
R-CNN論文詳解(學習筆記)
R-CNN:基於候選區域的目標檢測 Region proposals 基本概念(看論文前需要掌握的): 1.cnn(卷積神經網路):CNN從入門到精通(初學者) 2.Selective search:選擇性搜素 3.warp:圖形region變換 4.Supervised pre-t
R-CNN論文詳解
廢話不多說,上車吧,少年 &創新點 採用CNN網路提取影象特徵,從經驗驅動的人造特徵正規化HOG、SIFT到資料驅動的表示學習正規化,提高特徵對樣本的表示能力; 採用大樣本下有監督
Faster R-CNN論文詳解
廢話不多說,上車吧,少年 &創新點 設計Region Proposal Networks【RPN】,利用CNN卷積操作後的特徵圖生成region proposals,代替了Selective Search、EdgeBoxes等方法,速度上提
Fast R-CNN論文詳解
廢話不多說,上車吧,少年 &創新點 規避R-CNN中冗餘的特徵提取操作,只對整張影象全區域進行一次特徵提取; 用RoI pooling層取代最後一層max pooling層,同時引入建議框資訊,提取相應建議框特徵; Fast R-CNN網路
Faster R-CNN:詳解目標檢測的實現過程
最大的 中心 width 小數據 等等 eat tar 優先 博文 本文詳細解釋了 Faster R-CNN 的網絡架構和工作流,一步步帶領讀者理解目標檢測的工作原理,作者本人也提供了 Luminoth 實現,供大家參考。 Luminoth 實現:h
Faster R-CNN網路的另一種優化思路:cascade R-CNN網路詳解
論文:Cascade R-CNN: Delving into High Quality Object Detection 論文地址:https://arxiv.org/pdf/1712.00726.pdf Github專案地址:https://github.com/zhaoweicai/
R-CNN演算法詳解
這是一篇比較早的Object Detection演算法,發表在2014年的CVPR,也是R-CNN系列演算法的開山之作,網上可以搜到很多相關的部落格講解,本篇博文沒有按論文順序來講述,而是結合自己經驗來看這個演算法,希望給初學者一個直觀的感受,細節方面不需要太糾
Face Paper: R-FCN論文詳解
本篇部落格一方面介紹R-FCN演算法(NISP2016文章),該演算法改進了Faster RCNN,另一方面介紹其Caffe程式碼,這樣對演算法的認識會更加深入。要解決的問題:這篇論文提出一種基於region的object detection演算法:R-FCN(Region-
cascade R-CNN演算法詳解
cascade R-CNN演算法詳解 演算法背景 問題 解決方案 演算法介紹 演算法結構 邊界框迴歸 分類 檢測質量 級聯損失函式 實驗
深度學習 + 論文詳解: Fast R-CNN 原理與優勢
論文連結p.s. 鑑於斯坦福大學公開課裡面模糊的 R-CNN 描述,這邊決定精讀對應的論文並把心得和摘要記錄於此。前言在機器視覺領域的物體識別分支中,有兩個主要的兩大難題需要解決:目標圖片裡面含了幾種“物體”,幾個“物體”?該些物體分別坐落於圖片的哪個位置?而 R-CNN 的
CVPR 2018 | 騰訊AI Lab入選21篇論文詳解
騰訊 AI CVPR 近十年來在國際計算機視覺領域最具影響力、研究內容最全面的頂級學術會議CVPR,近日揭曉2018年收錄論文名單,騰訊AI Lab共有21篇論文入選,位居國內企業前列,我們將在下文進行詳解,歡迎交流與討論。 去年CVPR的論文錄取率為29%,騰訊AI Lab 共有6篇論文入選,點
【目標檢測】Cascade R-CNN 論文解析
都是 org 檢測 rpn 很多 .org 實驗 bubuko pro 目錄 0. 論文鏈接 1. 概述 @ 0. 論文鏈接 Cascade R-CNN 1. 概述 ??這是CVPR 2018的一篇文章,這篇文章也為我之前讀R-CNN系列困擾的一個問題提供了一個解決方案
支援向量機—SMO論文詳解(序列最小最優化演算法)
SVM的學習演算法可以歸結為凸二次規劃問題。這樣的凸二次規劃問題具有全域性最優解,並且許多最優化演算法可以用來求解,但是當訓練樣本容量很大時,這些演算法往往變得非常低效,以致無法使用。論文《Sequential Minimal Optimization:A Fast Algori
Faster R-CNN論文及原始碼解讀
R-CNN是目標檢測領域中十分經典的方法,相比於傳統的手工特徵,R-CNN將卷積神經網路引入,用於提取深度特徵,後接一個分類器判決搜尋區域是否包含目標及其置信度,取得了較為準確的檢測結果。Fast R-CNN和Faster R-CNN是R-CNN的升級版本,在準確率和實時性方面都得到了較大提升。在F
Fast R-CNN論文學習
R-CNN論文學習 Abstract 1. Introduction 1.1 R-CNN 和 SPPnet R-CNN的問題 SPPnet的改進和問題 1.2 本論文的貢獻
Faster R-CNN 論文學習
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 演算法簡介 Abstract 1. Introduction 2. Relat
Fast R-CNN論文筆記
本文分兩個部分,第一個部分是論文的筆記,第二個部分是結合程式碼來看fast-RCNN。 論文部分: 主要是為了對RCNN,SPPnet的效果上的改進,下面簡述了一些RCNN的缺點: Training is a multi-stage pipeline Training
[Network Architecture]Mask R-CNN論文解析(轉)
前言 最近有一個idea需要去驗證,比較忙,看完Mask R-CNN論文了,最近會去研究Mask R-CNN的程式碼,論文解析轉載網上的兩篇部落格 技術挖掘者 remanented 文章1 論文題目:Mask R-CNN 論文連結:論文連結 論文程式碼:Facebook程式
《Dilated Residual Networks》論文詳解
體會 感覺這篇文章的關鍵不是idea,而是寫法; 通過實驗和公式說明了這樣組合的優勢; 動機 之前的卷積神經網路都是通過不斷降低影象精度,直到影象被一個僅保留微弱空間資訊的特徵map表示(一般最後卷積層輸出僅為7×7),最後通過計算類別概率來分類影象
R-CNN論文翻譯:豐富的功能層次結構,用於精確的物件檢測和語義分割
R-CNN論文地址:R-CNN R-CNN專案地址: http://www.rossgirshick.info/ 摘要 在典型的PASCAL VOC資料集上測量的物件檢測效能在過去幾年中已經穩定下來。最好的方法是複雜的系統,通常將多個低階影象特徵與高階語境相結合。在本文中,我們