
[深度學習]RCNNs系列(2)RCNN介紹
阿新 • • 發佈:2019-01-03
RCNN是整個RCNN系列的開端,也是使用卷積神經網路進行目標檢測的一類重要方法的開端,下面我們來看一下RCNN演算法。
RCNN是rbg大神在2013年發表的《Rich feature hierarchies for accurate object detection and semantic segmentation》一文中提出的演算法,其實演算法的思想在現在來看非常的簡單,而且也很容易想到,然而這個演算法一出卻極大的提升了檢測的效果。
1. RCNN的檢測流程
RCNN主要分為3個大部分,第一部分產生候選區域,第二部分對每個候選區域使用CNN提取長度固定的特徵;第三個部分使用一系列的SVM進行分類。
下面就是RCNN的整體檢測流程:
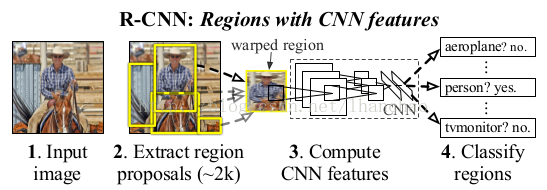
(1)首先輸入一張自然影象;
(2)使用Selective Search提取大約2000個候選區域(proposal);
(3)對每個候選區域的影象進行拉伸形變,使之成為固定大小的正方形影象,並將該影象輸入到CNN中提取特徵;
(4)使用線性的SVM對提取的特徵進行分類
下面我們來分佈介紹這幾個步驟。
1.1 候選區域的產生
這裡介紹的比較簡單,RCNN使用Selective Search演算法提取影象中的候選區域(因為我關注RCNN系列比較晚,直接應用的Faster RCNN,就沒有關注Selective Search演算法,這裡也就不介紹了)1.2 CNN特徵提取

最終作者選擇的是D中的直接拉伸的方法。
1.3 SVM特徵分類
好吧,作者論文裡並沒有介紹怎麼進行SVM的特徵分類,不過要注意的是作者為每個類都訓練了一個SVM分類器,在訓練/檢測的過程中使用這些分類器為每一類進行分類。2. 訓練與測試階段
2.1 應用測試階段
在測試階段,首先使用selective search提取測試影象的2000個proposals,然後將所有proposal影象拉伸到合適的大小並用CNN進行特徵提取,得到固定長度的特徵向量。最終對於每個類別,使用為該類別訓練的SVM分類器對得到的所有特徵向量(對應每個proposal影象)進行打分(代表的是這個proposal是該類的概率)。 注意到這裡作者應用了一次NMS(非最大值抑制),具體來說就是對每一類而言,若一個proposal與一個分值比它大的proposal相交,且IoU(intersection over union,即相交面積比這兩個proposal的並集面積之比)大於一定閾值的情況下,則拋棄該proposal。 作者對測試階段的時間進行了分析,認為RCNN的優勢在於:(1)CNN中共享網路引數(CNN本身特性);(2)CNN提取後的特徵維度較低(相比之前的方法),計算更快。2.2 訓練階段
2.2.1 ImageNet預訓練階段
作者首先在ImageNet上進行了CNN的預訓練,由於VOC 2012中訓練資料較少(相對而言),所以使用ImageNet預訓練然後再fine tune效果會更好。2.2.2 Fine-tuning(微調)階段
在微調階段,作者把ImageNet上預訓練的網路從1000個輸出改為21個輸出(VOC的20類+1類background),然後將所有與groundtruth的包圍框的IoU>= 0.5的proposal看作正類(20類之一),其他的全部看作背景類。在訓練時使用隨機梯度下降(SGD),學習率為0.001,在訓練的過程中隨機選取32個postive樣本和96個negative樣本,這樣選擇是因為在提取的proposal中background樣本要遠遠多於postive樣本。2.2.3 SVM分類器訓練階段
在訓練SVMs的過程中,作者把IoU低於0.3的proposal設定為negative樣本,對於postive則是groundtruth的包圍盒影象。作者對每個類別都訓練了一個線性的SVM分類器,由於訓練影象過多,同時為了保證訓練的效果,所以作者在訓練的過程中採用了hard negative mining方法(hard negative mining訓練方法在我看來就是通過訓練挑出訓練集中那些總是被識別錯誤的負樣本作為訓練集)。 作者的文章的附錄B中討論了兩個問題,這裡我也簡單介紹一下: (1)為什麼fine-tuning時採用的IoU閾值和SVM訓練時採用的閾值不同呢? 首先作者承認,在實驗開始他們並沒有fine-tuning的過程,而最開始使用SVM訓練時閾值就是0.3,在後面的實驗中加入finetuing以後,採用相同的閾值發現效果比使用現在的0.5閾值要差很多。作者的猜想是閾值的設定並不是很重要,而是微調時資料量的問題,在微調時採用0.5閾值的話會出現很多所謂的“抖動”的樣本,這些樣本於groundtruth的IoU在0.5到1之間,採用0.5的閾值以後正樣本增加了30倍,所以fine-tuning時訓練資料增多,效果會更好。 (2)為什麼不直接使用CNN的分類結果,而還要繼續訓練若干個SVM分類器呢? 作者也直接使用CNN分類結果進行了實驗,發現效果相比SVM有所降低,他發現使用CNN直接分類結果並不注重於精確定位(我覺得這個情況很合理,因為CNN識別能力非常強大,非常的魯棒,所以不是那麼精確的定位也可以得到比較好的結果,所以不注重精確定位)第二個原因在於SVM訓練時採用的hard negative mining選擇的樣本比CNN中隨機選擇的樣本要好,所以結果會更好。作者也提出,可能通過更改fine-tuning的一些細節可以提升效果(他們也是這麼做的,Fast RCNN中他們改變了loss函式)。3. Bounding-box迴歸
這裡需要重點提一下的是,作者在完成了前面提到的“生成候選區域——CNN提取特徵——SVM進行分類”以後,為了進一步的提高定位效果,在文章的附錄C中介紹了Bounding-box Regression的處理。 Bounding-box Regression訓練的過程中,輸入資料為N個訓練對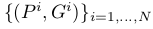 ,其中
,其中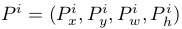 為proposal的位置,前兩個座標表示proposal的中心座標,後面兩個座標分別表示proposal的width和height,而
為proposal的位置,前兩個座標表示proposal的中心座標,後面兩個座標分別表示proposal的width和height,而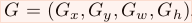 表示groundtruth的位置,regression的目標就是學會一種對映將P轉換為G。
作者設計了四種座標對映方法
表示groundtruth的位置,regression的目標就是學會一種對映將P轉換為G。
作者設計了四種座標對映方法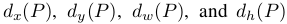 ,其中前兩個表示對proposal中心座標的尺度不變的平移變換,後面兩個則是對proposal的width和height的對數空間的變換,文章中的對映方式為:
,其中前兩個表示對proposal中心座標的尺度不變的平移變換,後面兩個則是對proposal的width和height的對數空間的變換,文章中的對映方式為:

其中
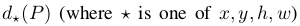 表示對該proposal的Pool5層提取的特徵
表示對該proposal的Pool5層提取的特徵 進行線性變化操作,即
進行線性變化操作,即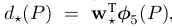 ,最終的優化方法為:
,最終的優化方法為:
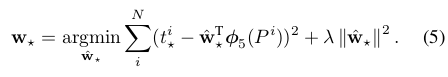
其中
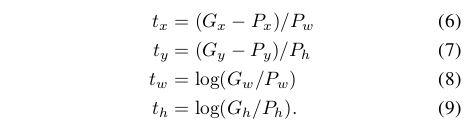
這是一個典型的最小二乘問題。 最終在進行實驗時,lambda = 1000,同時作者發現同一對中P和G相距過遠時通過上面的變換是不能完成的,而相距過遠實際上也基本不會是同一物體,因此作者在進行實驗室,對於pair(P,G)的選擇是選擇離P較近的G進行配對,這裡表示較近的方法是需要P和一個G的最大的IoU要大於0.6,否則則拋棄該P。 其實現在RCNN應用已經非常少了,我這裡重點介紹迴歸的原因就是以後的RCNN系列將這個迴歸的過程作為一個loss函式加入到了卷積神經網路中,他們的做法與這裡的非常相似。