
Caffe中實現LSTM網路的思路以及LSTM網路層的介面使用方法。 本文描述了論文《Long-term recurrent convolutional networks fo
程式碼地址:https://github.com/junhyukoh/caffe-lstm、
小demo:http://christopher5106.github.io/deep/learning/2016/06/07/recurrent-neural-net-with-Caffe.html
本文內容:
- 本文描述了Caffe中實現LSTM網路的思路以及LSTM網路層的介面使用方法。
- 本文描述了論文《Long-term recurrent convolutional networks for visual recognition and description》的演算法實驗
- 本文不做LSTM原理介紹,不從數學角度推導反向傳播,不進行Caffe詳細程式碼分析
- 本文基於對Caffe的程式碼及使用有一定的瞭解
涉及LSTM演算法原理的部分可以參考其他文章見如 理解 LSTM 網路等。
1 簡介及相關論文
LSTM為處理具有時間維度以及類似時間維度資訊的RNN深度神經網路的一種改進模型,參考文獻[1,2],在不少問題上能彌補CNN只能處理空間維度資訊的缺陷。不同於CNN的深度體現在網路層數及引數規模上,RNN/LSTM的深度主要體現在時間節點上的深度。
Caffe中的LSTM相關程式碼由Jeff Donahue基於文獻[1]的實驗Merge而來。文獻[3]中有三個關於使用LSTM的實驗:(1)行為識別(介紹及程式碼) (2)影象描述(影象標註,
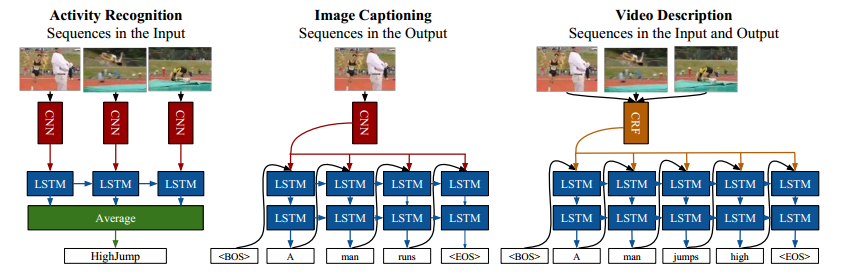
本文主要從文獻[3]第一個實驗出發,介紹LSTM的介面的使用。
2 行為識別實驗
實驗使用UCF-101 資料集。行為識別實驗目的為給定一視訊片段,判斷出視訊片段人物的行為。
2.1 演算法介紹
如1.1圖所示,該實驗的方法為:
- 首先提取視訊的部分幀
- 其次根據標註的幀預訓練一個圖片分類網路(基於AlexNet)
- 訓練LSTM模型
- 預訓練的共享的CNN提取一段視訊序列(時間上相關的幀)的CNN特徵
- 以上特徵輸入至LSTM單元
- 對每個LSTM單元的輸出取平均得到最後的檢測結果
2.2 網路模型
Caffe訓練網路的網路結果如下所示:
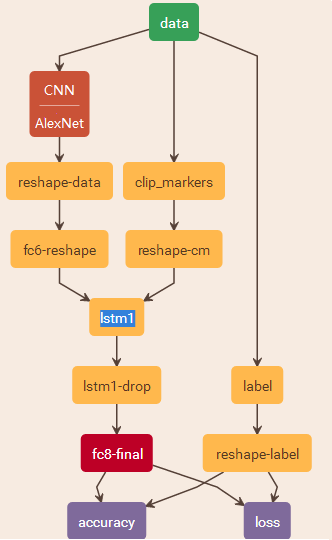
2.3相關術語及變數
-
N 為LSTM同時處理的獨立流的個數,在該實驗中為輸入LSTM相互獨立的視訊的個數,以該實驗測試網路為例,本文取T=3 。 -
T 為LSTM網路層處理的時間步總數,在該實驗中為輸入LSTM的任意一獨立視訊的視訊幀個數,以該實驗測試網路為例,本文取T=16 。 -
因此fc-reshape層輸出維度為
T×N×4096 . 4096為AlexNet中全連線層的維度,即CNN特徵的維度。 -
reshape-cm的輸出維度為
T×N ,即每一個幀有一個是否連續幀的標誌。 -
reshape-label的維度同樣為
T×N
3 Caffe 相關類及介面
3.1 相關類
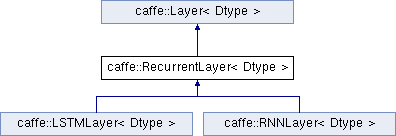
其中:
- RecurrentLayer為一個抽象類,定義了處理時間序列的迴圈神經網路的通用行為
- LSTMLayer及RNNLayer為RecurrentLayer的具體實現,後者為RNN的一般形式
- LSTMUnitLayer在LSTMLayer內部使用,處理了部分核心計算
3.2 介面說明
由官方文件可知,一個 RecurrentLayer/LSTMLayer 的輸入為三個Blob:
- 一. 時間變化資料
x,(T×N×...) 。2.3處已介紹,此實驗測試網路中該維度為16×3×4096 。注意T 在N 前面。 - 二. 序列連續性標誌
cont,(T×N) 。2.3處已介紹,此實驗測試網路中該維度為16×3 ,其中0表示該圖片為視訊幀的開始,1表示該圖片為上一幀的延續。注意不能反過來用1表示為開始,在程式碼實現中,開始幀視訊應當“遺忘”以往的資訊,所以乘以0歸零了之前的資料。 - 三. 時間不變的靜態資料
xstatic,(N×...) (可選)。該項在行為識別中沒有使用,而在第二個實驗圖片描述中有使用。如使用一張不隨時間變化的圖片作為第三個輸入,該圖片的輸入維度為N×4096 .
4 LSTMLayer
Caffe中通過展開LSTMLayer網路層,得到另一個網路從而實現LSTM,即一個LSTMLayer即為一個LSTM網路。以實驗中測試網路為例,及
4.1 實現流程
如圖所示:
- 方框為網路層,文字為網路層型別。
- 橢圓為資料Blob。
- Blob
ci 為細胞狀態; Blobhi 為隱藏狀態 - 藍色為輸入資料或產生輸出資料的網路層。
- 紅色為權重網路層。
- 整體外框為基類RecurrentLayer實現的功能,子框為LSTMLayer實現的功能。
- 輸出為Blob h(1,3,256)。
- 最後的Reduction層生產的偽損失,該網路層不起功能作用,存在的意義只是使這個網路變得完成,而“強制”反向傳播。
- 多個時間步(
T1,…,T16 )間的InnerProduct是共享引數的,及保證了各個時間步的權重能處理同一時間序列。因而整個網路(LSTM網路)只有三個權重Blob:圖中第一個紅色框中的InnerProduct層的權重Wxc 及 偏置bc ,後邊所有紅色權重層的權重Whc (共享的,且無偏置) - Scale層為根據cont提供的序列連續性情況,來決定是否保持(乘1)與放棄(乘0)之前的隱藏狀態
ht−1
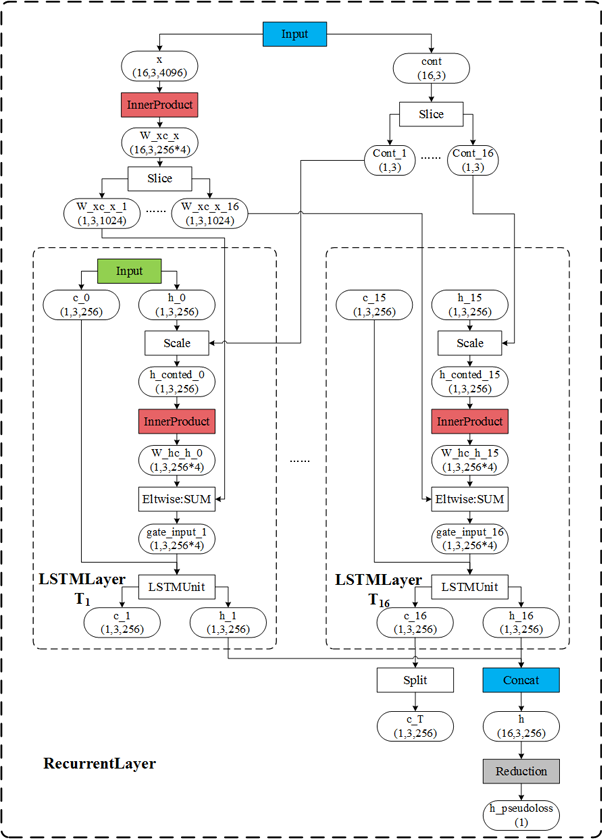
4.2 公式描述
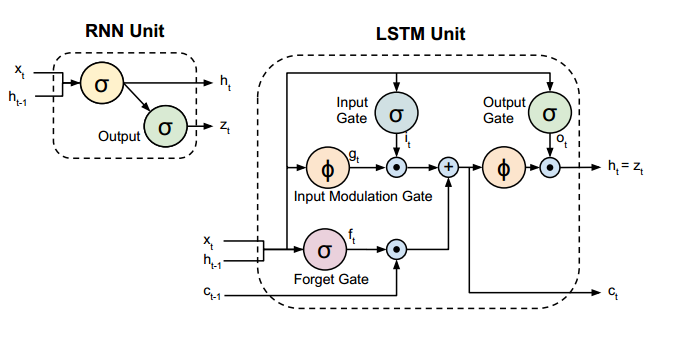
計算公式如下:
相關推薦
Caffe中實現LSTM網路的思路以及LSTM網路層的介面使用方法。 本文描述了論文《Long-term recurrent convolutional networks fo
程式碼地址:https://github.com/junhyukoh/caffe-lstm、 小demo:http://christopher5106.github.io/deep/learning/2016/06/07/recurrent-neural-n
[caffe] Long-term Recurrent Convolutional Networks
Python Layer train_test_lstm_RGB.prototxt name: "lstm_joints" layer { name: "data" type: "Python" top: "data" top:
Cisco Packet Tracer中的基礎命令操作以及組織網路實驗
基於思科模擬器的路由基礎命令操作 1.開啟Cisco packet tracer,選取路由器Router2811(example) 2.雙擊該路由器,在彈出的視窗選擇 CLI 選項,啟動後輸入no,回車即可進入路由器的使用者模式,若要進行對話方塊配
java Web中實現QQ郵箱驗證以及驗證碼註冊使用者
實體類:User.java package com.yinhe.bean; import java.util.Date; public class User { private String uid; private String username; private Str
在caffe 中實現Generative Adversarial Nets(一)
目錄 一、Generative Adversarial Nets 1. GAN簡介 對抗生成網路(GAN)同時訓練兩個模型:能夠得到資料分佈的生成模型(generative model G)和能判夠區別資料是生成的還是真實的判別模型 (discr
(二)ubuntu 14.04+ORB_SLAM2+ROS indigo中實現攝像頭實時定位以及踩過的若干個坑&解決方案
前言 實現方案 前言 上一篇部落格主要講述如何安裝ROS indigo,這篇主要集中在安裝usb_cam以及如何在ORB_SLAM2上實現實時定位。 實現方案 安裝usb_cam 建立一個工作空間,make一下 mkdir -p
《前端之路》- TypeScript (三) ES5 中實現繼承、類以及原理
[TOC] > 這篇文章中的內容會比較的多,而且在基礎中是資料相對比較複雜的基礎,主要是講到了 JS 這門語言中如何實現繼承、多型,以及什麼情況如何定義 私有屬性、方法,共有屬性、方法,被保護的屬性和方法。明確的定義了 JS 中的訪問邊界問題,以及最終實現的原理是什麼。接下來,讓我們仔細瞅瞅這部分吧~ #
python實現sklearn的基本操作流程,sklearn預處理方法,sklearn基礎演算法的使用,以及sklearn模型的選擇方法。
一、資料的獲取與分析 1.讀取資料 本文使用pandas的read_csv方法讀取資料,常用的的方法還有,如pandas.read_sql_query(),pandas.read_excel()等。 import pandas as pd #讀取資料 data
MFC中實現單擊按鈕彈出對話方塊的方法
1、資源檢視-->Dialog-->右鍵-->新增資源-->新建-->對話方塊-->對話方塊按右鍵--新增類。例:新增CNewDlg類,在所要調的程式碼中(按鈕點選方法中),先加標頭檔案#include "CNewDlg.h ",之後
給定一段連續的整數,求出他們中所有偶數的平方和以及所有奇數的立方和。
其中 包括 輸入數據 clu ++ %d int bottom pan Input 輸入數據包含多組測試實例,每組測試實例包含一行,由兩個整數m和n組成。 Output 對於每組輸入數據,輸出一行,應包括兩個整數x和y,分別表示該段連續的整數中所有偶數的平方和以及所有奇
定義抽象類Shape,抽象方法為showArea(),求出面積並顯示,定義矩形類Rectangle,正方形類Square,圓類 Circle,根據各自的屬性,用showArea方法求出各自的面積,在main方法中構造3個對象,調用showArea方法。(體現多態)
子類 protected new 都是 package 使用 類指針 3.1 shape 實現多態的三個條件:1.要有繼承2.要有抽象方法重寫3.用父類指針(引用)指向子類對象 重載重寫重定義的區別: 1.重載:在同一個類中進行; 編譯時根據參數類型和個數決定方法調用;
Java中utf-8格式字符串的存儲方法。
字節 turn byte[] spa 負數 oid 只有一個 ret 字符串截取 知識點:可通過 byte[] bytes=“xxxx”.getBytes("utf-8")得到字符串通過utf-8解析到字節數組。utf-8編碼格式下,計算機采用1個字節存儲ASCII範圍內的
django使用多資料庫,以及admin管理使用的方法。
django中可以從多個數據庫中讀寫資料。 由於業務需要,開發中遇到了需要讀寫另一個數據庫的情況。 以下是工作時的遇到問題的解決方法: django多資料庫的配置: 1. 在資料庫配置欄位,增加需要連線的資料庫 在settings.py檔案下找到 DATABASES =
Bi-LSTM的理解以及 Tensorflow實現
Bidirectional LSTM,由兩個LSTMs上下疊加在 一起組成。輸出由這兩個LSTMs的隱藏層的狀態決定。 def bilstm(self,x): # 輸入的資料格式轉換 # x.shape [batch_size, time_
網路爬蟲以及自動化測試中圖形驗證碼識別解決思路以及方法
前言 做自動化測試的朋友都知道圖形驗證碼在整個自動化執行過程中,很可能是阻礙推進的問題,可以採用萬能驗證碼(開發哥哥會流出一個供自動化測試用的),如果不通過開發預留,有以下解決方案。 解決思路 1.python3自帶光學字元識別模組tesserocr與pytesseract,可以識別簡單驗證碼; 2.稍
Tensorflow: MNIST資料集實現DNN、CNN、LSTM神經網路
最近學了一下tensorflow的基本用法,這裡做一下總結 全連線深度神經網路(FC-DNN) 全連線深度神經網路,每一層的神經元直接都是全連線,並且不共享權值。在普通的分類的問題中表現的不錯,但是對於圖片處理等具有網格形式的資料,最好採用CNN(卷積神經網路),對於序列化資料如NL
Tensorflow中的RNN以及LSTM
先了解RNN: 每個RNNCell都有一個call方法,使用方式是:(output, next_state) = call(input, state)。每呼叫一次RNNCell的call方法,就相當於在時間上“推進了一步”,這就是RNNCell的基本功能。 import
長短期記憶神經網路(LSTM)介紹以及簡單應用分析
本文分為四個部分,第一部分簡要介紹LSTM的應用現狀;第二部分介紹LSTM的發展歷史,並引出了受眾多學者關注的LSTM變體——門控遞迴單元(GRU);第三部分介紹LSTM的基本結構,由基本迴圈神經網路結構引出LSTM的具體結構。第四部分,應用Keras框架提供的API,比較和分析簡單迴
spring boot中實現響應圖片的方法以及改進
spring-bootController響應,噴出圖片,是一個很常見的功能,代碼如下@RequestMapping(value = { "/img/{filename:.+}" }, method = RequestMethod.GET, produces = { MediaType.I
動態SQL中 實現條件參數 varchar類型的參數名稱 以及模糊查詢實現
pty set tab 條件 name 條件參數 arc str ble set @strSQL=‘select * from testtable AS P WHERE P.Type=‘+@PType+‘