
人體骨骼關鍵點檢測綜述
導言
人體骨骼關鍵點對於描述人體姿態,預測人體行為至關重要。因此人體骨骼關鍵點檢測是諸多計算機視覺任務的基礎,例如動作分類,異常行為檢測,以及自動駕駛等等。近年來,隨著深度學習技術的發展,人體骨骼關鍵點檢測效果不斷提升,已經開始廣泛應用於計算機視覺的相關領域。本文主要介紹2D人體骨骼關鍵點的基本概念和相關演算法,其中演算法部分著重介紹基於深度學習的人體骨骼關鍵點檢測演算法的兩個方向,即自上而下(Top-Down)的檢測方法和自下而上(Bottom-Up)的檢測方法。
相關介紹
什麼是人體骨骼關鍵點檢測
人體骨骼關鍵點檢測即Pose Estimation,主要檢測人體的一些關鍵點,如關節,五官等,通過關鍵點描述人體骨骼資訊;
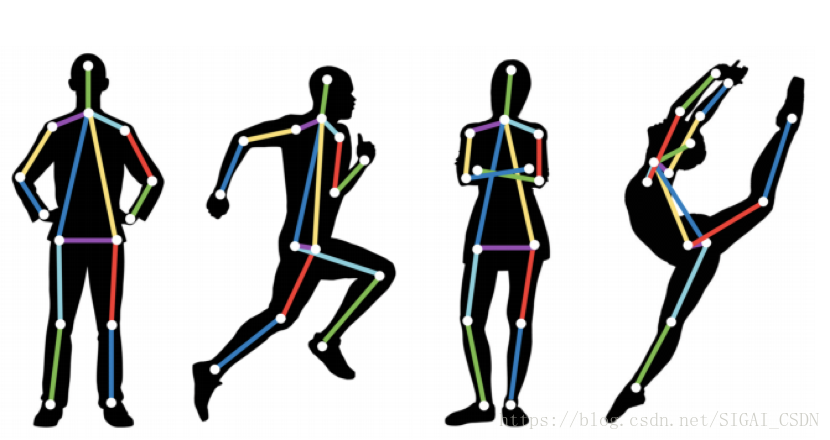
應用與挑戰
人體骨骼關鍵點檢測是計算機視覺的基礎性演算法之一,在計算機視覺的其他相關領域的研究中都起到了基礎性的作用,如行為識別、人物跟蹤、步態識別等相關領域。具體應用主要集中在智慧視訊監控,病人監護系統,人機互動,虛擬現實,人體動畫,智慧家居,智慧安防,運動員輔助訓練等等。
由於人體具有相當的柔性,會出現各種姿態和形狀,人體任何一個部位的微小變化都會產生一種新的姿態,同時其關鍵點的可見性受穿著、姿態、視角等影響非常大,而且還面臨著遮擋、光照、霧等環境的影響,除此之外,2D人體關鍵點和3D人體關鍵點在視覺上會有明顯的差異,身體不同部位都會有視覺上縮短的效果(foreshortening),使得人體骨骼關鍵點檢測成為計算機視覺領域中一個極具挑戰性的課題。
相關資料集
LSP(Leeds Sports Pose Dataset):單人人體關鍵點檢測資料集,關鍵點個數為14,樣本數2K,在目前的研究中基本上被棄用;
FLIC(Frames Labeled In Cinema):單人人體關鍵點檢測資料集,關鍵點個數為9,樣本數2W,在目前的研究中基本上被棄用;
MPII(MPII Human Pose Dataset):單人/多人人體關鍵點檢測資料集,關鍵點個數為16,樣本數25K;
MSCOCO:多人人體關鍵點檢測資料集,關鍵點個數為17,樣本數多於30W,目前的相關研究基本上還需要在該資料集上進行驗證;
AI Challenger:多人人體關鍵點檢測資料集,關鍵點個數為14,樣本數約38W,競賽資料集;
PoseTrack:最新的關於人體骨骼關鍵點的資料集,多人人體關鍵點跟蹤資料集,包含單幀關鍵點檢測、多幀關鍵點檢測、多人關鍵點跟蹤三個人物,多於500個視訊序列,幀數超過20K,關鍵點個數為15。
傳統演算法概述
傳統的人體骨骼關鍵點檢測演算法基本上都是在幾何先驗的基礎上基於模版匹配的思路來進行,那麼核心就在於如何去用模版表示整個人體結構,包括關鍵點的表示,肢體結構的表示以及不同肢體結構之間的關係的表示。一個好的模版匹配的思路,可以模擬更多的姿態範圍,以至於能夠更好的匹配並檢測出對應的人體姿態。
Pictorial Structure是其中一個較為經典的演算法思路,主要包含兩個部分,其一是單元模版(Unary Templates),其二是模版關係(Pairwise Springs),對於模版關係,提出了著名的彈簧形變模型,彈簧形變模型,即對部件模型與整體模型的相對空間位置關係進行建模,利用了物體的一些空間先驗知識,既合理約束了整體模型和部件模型的空間相對位置,又保持了一定的靈活性。
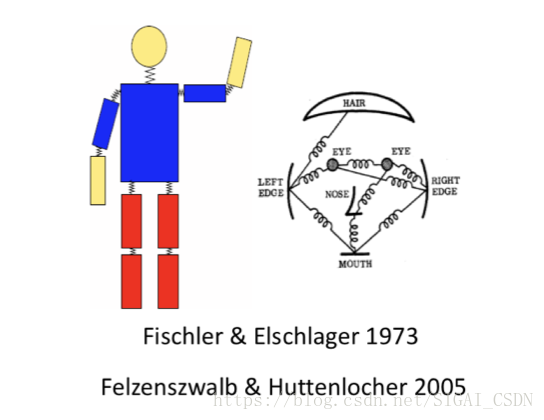
在接下來的研究中,為了匹配更大的姿態範圍,Yang & Ramanan提出了“mini parts”的概念,即將每個肢體結構(part)切分成更小的parts以能夠模擬更多的姿態變化,從而提高模版匹配的效果,具體示意圖如下圖(摘自論文[7]對應slides)所示。
人體骨骼關鍵點檢測
演算法概述
多人人體骨骼關鍵點檢測主要有兩個方向,一種是自上而下,一種是自下而上,其中自上而上的人體骨骼關鍵點定位演算法主要包含兩個部分,人體檢測和單人人體關鍵點檢測,即首先通過目標檢測演算法將每一個人檢測出來,然後在檢測框的基礎上針對單個人做人體骨骼關鍵點檢測,其中代表性演算法有G-RMI, CFN, RMPE, Mask R-CNN, and CPN,目前在MSCOCO資料集上最好的效果是72.6%;自下而上的方法也包含兩個部分,關鍵點檢測和關鍵點聚類,即首先需要將圖片中所有的關鍵點都檢測出來,然後通過相關策略將所有的關鍵點聚類成不同的個體,其中對關鍵點之間關係進行建模的代表性演算法有PAF, Associative Embedding, Part Segmentation, Mid-Range offsets,目前在MSCOCO資料集上最好的效果是68.7%。
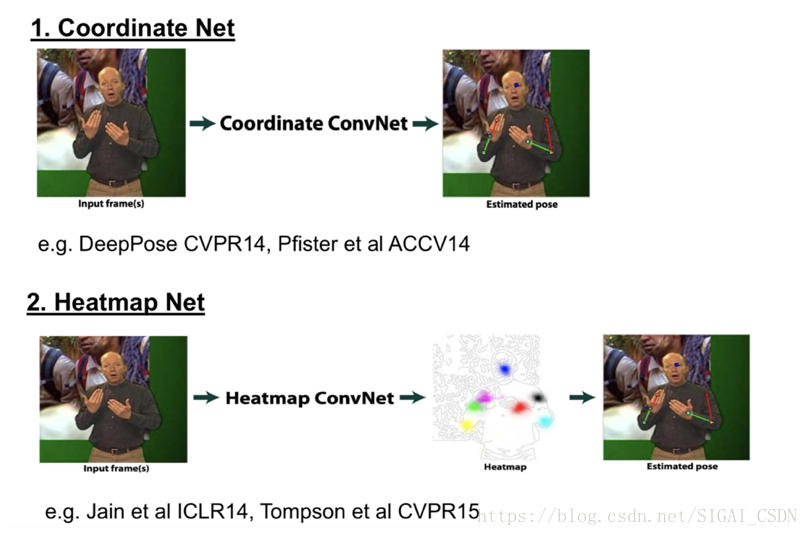
Coordinate、Heatmap和Heatmap + Offsets
在介紹多人人體骨骼關鍵點檢測演算法之間,首先介紹一下關鍵點回歸的Ground Truth的構建問題,主要有兩種思路,Coordinate和Heatmap,Coordinate即直接將關鍵點座標作為最後網路需要回歸的目標,這種情況下可以直接得到每個座標點的直接位置資訊;Heatmap即將每一類座標用一個概率圖來表示,對圖片中的每個畫素位置都給一個概率,表示該點屬於對應類別關鍵點的概率,比較自然的是,距離關鍵點位置越近的畫素點的概率越接近1,距離關鍵點越遠的畫素點的概率越接近0,具體可以通過相應函式進行模擬,如Gaussian等,如果同一個畫素位置距離不同關鍵點的距離大小不同,即相對於不同關鍵點該位置的概率不一樣,這時可以取Max或Average,如下圖(摘自論文[16])所示。
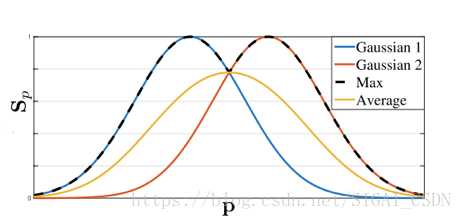
對於兩種Ground Truth的差別,Coordinate網路在本質上來說,需要回歸的是每個關鍵點的一個相對於圖片的offset,而長距離offset在實際學習過程中是很難迴歸的,誤差較大,同時在訓練中的過程,提供的監督資訊較少,整個網路的收斂速度較慢;Heatmap網路直接回歸出每一類關鍵點的概率,在一定程度上每一個點都提供了監督資訊,網路能夠較快的收斂,同時對每一個畫素位置進行預測能夠提高關鍵點的定位精度,在視覺化方面,Heatmap也要優於Coordinate,除此之外,實踐證明,Heatmap確實要遠優於Coordinate,具體結構如下圖所示。
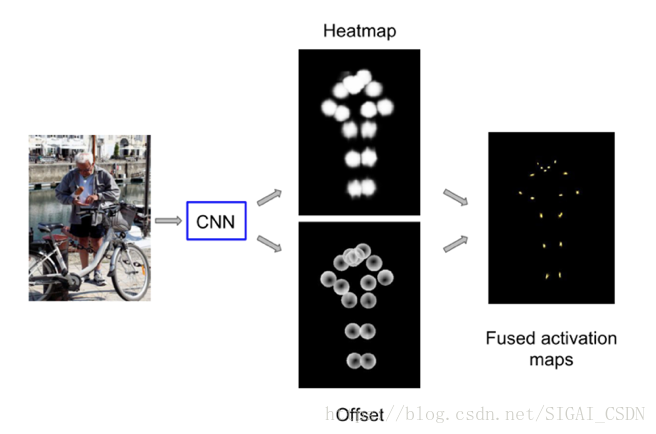
最後,對於Heatmap + Offsets的Ground Truth構建思路主要是Google在CVPR 2017上提出的,與單純的Heatmap不同的是,Google的Heatmap指的是在距離目標關鍵點一定範圍內的所有點的概率值都為1,在Heatmap之外,使用Offsets,即偏移量來表示距離目標關鍵點一定範圍內的畫素位置與目標關鍵點之間的關係。目前還沒有在公開的論文看到有人比較過這兩種Ground Truth構建思路的效果差異,但是個人認為Heatmap + Offsets不僅構建了與目標關鍵點之間的位置關係,同時Offsets也表示了對應畫素位置與目標關鍵點之間的方向資訊,應該要優於單純的Heatmap構建思路。如下圖所示(摘自論文[9])。
自上而下的人體關鍵點檢測演算法
自上而下(Top-Down)的人體骨骼關鍵點檢測演算法主要包含兩個部分,目標檢測和單人人體骨骼關鍵點檢測,對於目標檢測演算法,這裡不再進行描述,而對於關鍵點檢測演算法,首先需要注意的是關鍵點區域性資訊的區分性很弱,即背景中很容易會出現同樣的區域性區域造成混淆,所以需要考慮較大的感受野區域;其次人體不同關鍵點的檢測的難易程度是不一樣的,對於腰部、腿部這類關鍵點的檢測要明顯難於頭部附近關鍵點的檢測,所以不同的關鍵點可能需要區別對待;最後自上而下的人體關鍵點定位依賴於檢測演算法的提出的Proposals,會出現檢測不準和重複檢測等現象,大部分相關論文都是基於這三個特徵去進行相關改進,接下來我將簡要介紹其中幾種經典的演算法思路。

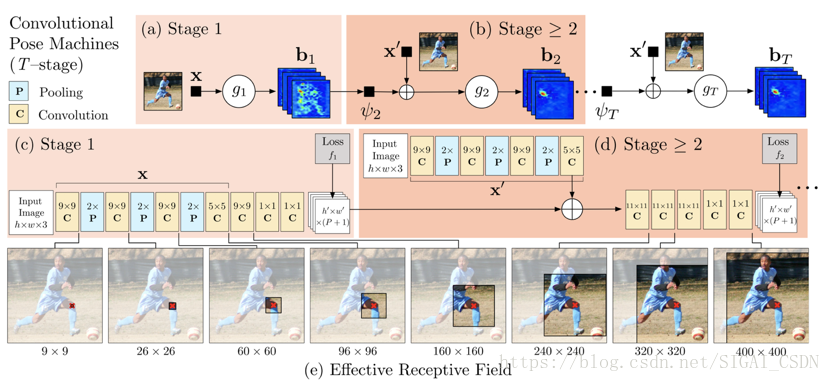
Convolutional Pose Machines:本論文將深度學習應用於人體姿態分析,同時用卷積圖層表達紋理資訊和空間資訊。主要網路結構分為多個stage,其中第一個stage會產生初步的關鍵點的檢測效果,接下來的幾個stage均以前一個stage的預測輸出和從原圖提取的特徵作為輸入,進一步提高關鍵點的檢測效果。具體的流程圖如下圖(摘自論文[12])所示。
用各部件響應圖來表達各部件之間的空間約束,響應圖和特徵圖一起作為資料在網路中傳遞。人體關鍵點在空間上的先驗分佈會指導網路的學習,假如stage 1的預測結果中右肩關鍵點的預測結果是正確的,而右肘關鍵點的預測是錯誤的,那麼在接下來的stage中肩和肘在空間上的先驗分佈會指導網路的學習。如下圖(摘自論文[12])所示。
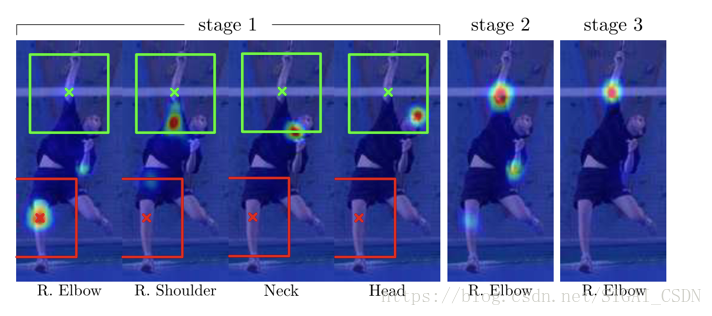
除此之外,使用多階段監督,對於各個階段的預測輸出都有監督訓練,避免過深網路難以優化的問題,而且感受野隨著stage的增多而逐漸增大,最後值得一提的是第一階段對原圖提取特徵的網路區別於stage > 1的特徵提取網路,因為第一個階段網路的作用是預測初步的結果,而後幾個階段的作用是結合關鍵點空間先驗知識和對原圖提取的特徵對上一個stage預測的結果做進一步精化。
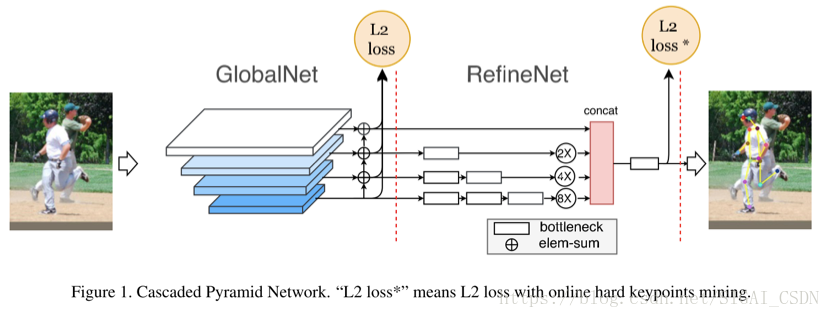
Cascaded Pyramid Network:本論文主要關注的是不同類別關鍵點的檢測難度是不一樣的,整個結構的思路是先檢測比較簡單的關鍵點、然後檢測較難的關鍵點、最後檢測更難的或不可見的關鍵點。具體Pipeline如下圖(摘自論文[13]對應slides)所示。
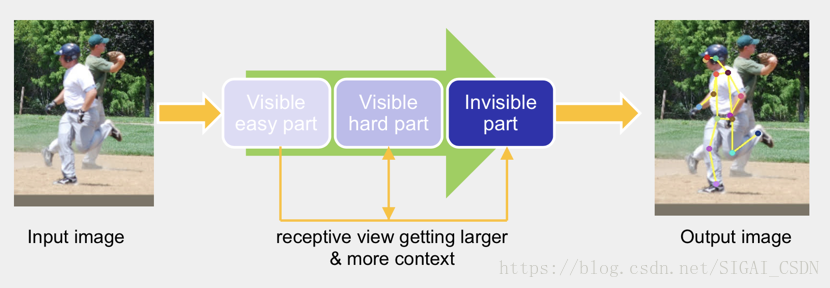
具體實現時,分為兩個stage,GlobalNet和RefineNet。其中GlobalNet主要負責檢測容易檢測和較難檢測的關鍵點,對於較難關鍵點的檢測,主要體現在網路的較深層,通過進一步更高層的語義資訊來解決較難檢測的關鍵點問題;RefineNet主要解決更難或者不可見關鍵點的檢測,這裡對關鍵點進行難易程度進行界定主要體現在關鍵點的訓練損失上,使用了常見的Hard Negative Mining策略,在訓練時取損失較大的top-K個關鍵點計算損失,然後進行梯度更新,不考慮損失較小的關鍵點。網路結果如下圖(摘自論文[13]對應slides)所示。
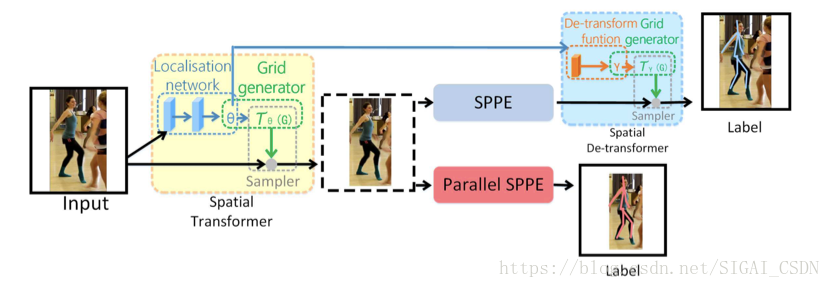
RMPE:本論文主要考慮的是自上而下的關鍵點檢測演算法在目標檢測產生Proposals的過程中,可能會出現檢測框定位誤差、對同一個物體重複檢測等問題。檢測框定位誤差,會出現裁剪出來的區域沒有包含整個人活著目標人體在框內的比例較小,造成接下來的單人人體骨骼關鍵點檢測錯誤;對同一個物體重複檢測,雖然目標人體是一樣的,但是由於裁剪區域的差異可能會造成對同一個人會生成不同的關鍵點定位結果。本文提出了一種方法來解決目標檢測產生的Proposals所存在的問題,即通過空間變換網路將同一個人體的產生的不同裁剪區域(Proposals)都變換到一個較好的結果,如人體在裁剪區域的正中央,這樣就不會產生對於一個人體的產生的不同Proposals有不同關鍵點檢測效果。具體Pipeline如下圖(摘自論文[14])所示。
自下而上的人體關鍵點檢測演算法
自下而上(Bottom-Up)的人體骨骼關鍵點檢測演算法主要包含兩個部分,關鍵點檢測和關鍵點聚類,其中關鍵點檢測和單人的關鍵點檢測方法上是差不多的,區別在於這裡的關鍵點檢測需要將圖片中所有類別的所有關鍵點全部檢測出來,然後對這些關鍵點進行聚類處理,將不同人的不同關鍵點連線在一塊,從而聚類產生不同的個體。而這方面的論文主要側重於對關鍵點聚類方法的探索,即如何去構建不同關鍵點之間的關係,接下來我將介紹幾種經典的方法。
Part Segmentation:即對人體進行不同部位分割,而關鍵點都落在分割區域的特定位置,通過部位分割對關鍵點之間的關係進行建模,既可以顯式的提供人體關鍵點的空間先驗知識,指導網路的學習,同時在最後對不同人體關鍵點進行聚類時也能起到相應的連線關鍵點的作用。如下圖(摘自論文[15])所示。

Part Affinity Fields:該方法通過對人體的不同肢體結構進行建模,使用向量場來模擬不同肢體結構,解決了單純使用中間點是否在肢幹上造成的錯連問題。
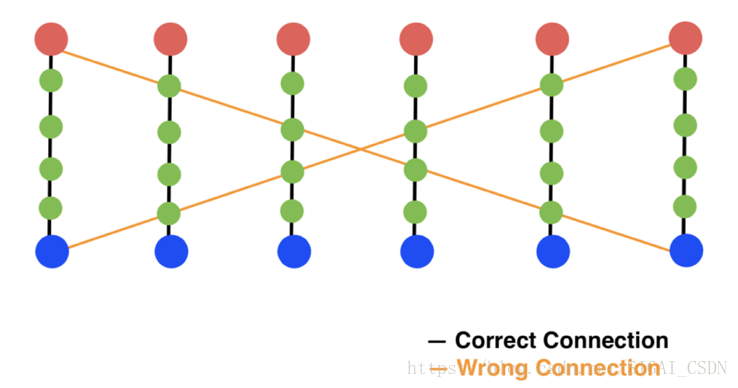
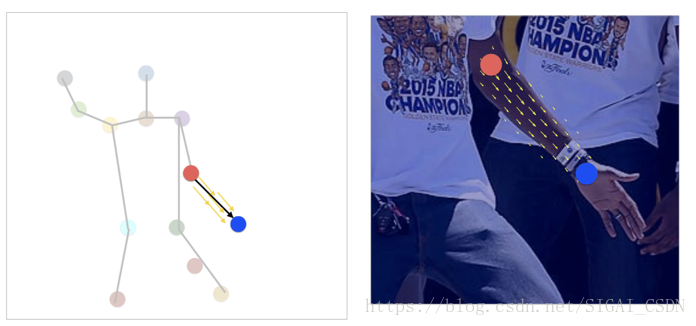
如上圖(摘自論文[16]對應slides)所示,如果只使用中間點對肢幹進行建模,如果中間點都在對應的肢幹上,則判斷兩個關鍵點處在該肢乾的兩端,這樣就會出現如上圖所示的錯連情況。而PAFs則不僅使用中間點來建模肢幹,而且在中間的位置之外還給每個中間點加上了方向的資訊,這樣就能解決出現的錯連問題。具體如下圖(摘自論文[16]對應slides)所示。
Associative Embedding:該方法通過使用高維空間的向量來編碼不同人體的不同關鍵點之間的關係,即同一個人的不同關鍵點在空間上是儘可能接近的,不同人的不同關鍵點在空間上是儘可能遠離的,最後可以通過兩個關鍵點在高維空間上的距離來判斷兩個關鍵點是否屬於同一個人,從而達到聚類的目的。如下圖(摘自論文[17])所示。
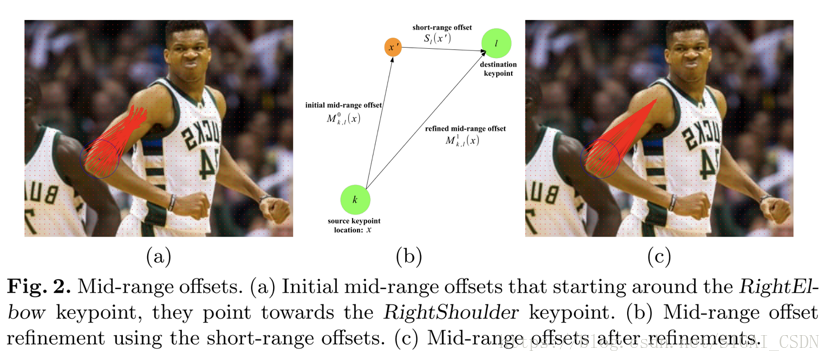
Mid-Range Offsets:該方法通過直接回歸一個關鍵點到另一個關鍵點之間的offset來建模兩個關鍵點之間的關係,這種較長距離的offsets是較難學習的,在迴歸具體數值時會有較大誤差,這裡可以用關鍵點周圍的Short-Range Offsets去進一步Refine對應的offsets。具體如下圖(摘自論文[18])所示。
小結
人體骨骼關鍵點定位至今仍然是計算機視覺領域較為活躍的一個研究方向,人體骨骼關鍵點檢測演算法還沒有達到比較完美的效果,在較為複雜的場景下仍然會出現很多錯誤的檢測結果。自上而下的關鍵點檢測演算法在效果上要明顯好於自下而上的關鍵點檢測演算法,因為自上而下的檢測方法加入了整個人體的一個空間先驗。個人認為,自下而上的關鍵點定位演算法沒有顯示的去建模整個人體的空間關係,而只是建模了局部的空間關係,以至於在效果上目前還遠低於自上而上的關鍵點檢測方法。
參考文獻
[1] Iqbal U, Milan A, Gall J. PoseTrack: Joint Multi-person Pose Estimation and Tracking[C]// Computer Vision and Pattern Recognition. IEEE, 2017:4654-4663.
[2] S. Johnson and M. Everingham. Learning effective human pose estimation from inaccurate annotation. In CVPR, pages 1465–1472. IEEE, 2011.
[3] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ra- manan, P. Dollar, and C. L. Zitnick. Microsoft coco: Com- mon objects in context. In ECCV, 2014.
[4] Mykhaylo Andriluka, Leonid Pishchulin, Peter Gehler, and Bernt Schiele. 2d human pose estimation: New benchmark and state of the art analysis. In Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on, pages 3686– 3693. IEEE, 2014.
[5] Fischler M A, Elschlager R A. The Representation and Matching of Pictorial Structures[J]. IEEE Trans Computers C, 1973, 22(1):67-92.
[6] Pedro F. Felzenszwalb, Daniel P. Huttenlocher. Pictorial Structures for Object Recognition[J]. International Journal of Computer Vision, 2005, 61(1):55-79.
[7] Yang Y, Ramanan D. Articulated pose estimation with flexible mixtures-of-parts[J]. 2011, 32(14):1385-1392.
[8] Toshev A, Szegedy C. DeepPose: Human Pose Estimation via Deep Neural Networks[C]// Computer Vision and Pattern Recognition. IEEE, 2014:1653-1660.
[9] Papandreou G, Zhu T, Kanazawa N, et al. Towards Accurate Multi-person Pose Estimation in the Wild[J]. 2017:3711-3719.
[10] Huang S, Gong M, Tao D. A Coarse-Fine Network for Keypoint Localization[C]// IEEE International Conference on Computer Vision. IEEE, 2017:3047-3056.
[11] He K, Gkioxari G, Dollár P, et al. Mask R-CNN[J]. 2017.
[12] Wei S E, Ramakrishna V, Kanade T, et al. Convolutional Pose Machines[J]. 2016:4724-4732.
[13] Chen Y, Wang Z, Peng Y, et al. Cascaded Pyramid Network for Multi-Person Pose Estimation[J]. 2017.
[14] Fang H S, Xie S, Tai Y W, et al. RMPE: Regional Multi-person Pose Estimation[J]. 2016:2353-2362.
[15] Xia F, Wang P, Chen X, et al. Joint Multi-person Pose Estimation and Semantic Part Segmentation[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2017:6080-6089.
[16] Cao Z, Simon T, Wei S E, et al. Realtime Multi-person 2D Pose Estimation Using Part Affinity Fields[J]. 2016:1302-1310.
[17] Newell A, Huang Z, Deng J. Associative Embedding: End-to-End Learning for Joint Detection and Grouping[J]. 2016.
[18] Papandreou G, Zhu T, Chen L C, et al. PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model[J]. 2018.
推薦閱讀
[1] 機器學習-波瀾壯闊40年 SIGAI 2018.4.13.
[3] 人臉識別演算法演化史 SIGAI 2018.4.20.
[6] 用一張圖理解SVM的脈絡SIGAI 2018.4.28.
[7] 人臉檢測演算法綜述 SIGAI 2018.5.3.
[8] 理解神經網路的啟用函式 SIGAI 2018.5.5.
[10] 理解梯度下降法 SIGAI 2018.5.11
[12] 理解凸優化SIGAI 2018.5.18
[16] 理解牛頓法 SIGAI 2018.5.31
