
視訊行為識別檢測綜述 IDT TSN CNN-LSTM C3D CDC R-C3D
阿新 • • 發佈:2018-12-19
轉載於:https://blog.csdn.net/xiaoxiaowenqiang/article/details/80752849 若有侵權 聯絡刪除
Video Analysis之Action Recognition(行為識別)
行為識別就是對時域預先分割好的序列判定其所屬行為動作的型別,即“讀懂行為”。
- 1
行為檢測 Action Detection 類似影象目標檢測
但在現實應用中更容易遇到的情況是序列尚未在時域分割(Untrimmed), 因此需要同時對行為動作進行時域定位(分割)和型別判定,這類任務一般稱為行為檢測。 傳統 DTW 動態時間規整 分割視訊 現在 利用RNN網路對未分割序列進行行為檢測(行為動作的起止點的定位 和 行為動作型別的判定) Action Detection 目的:不僅要知道一個動作在視訊中是否發生,還需要知道動作發生在視訊的哪段時間 特點:需要處理較長的,未分割的視訊。且視訊通常有較多幹擾,目標動作一般只佔視訊的一小部分。 分類:根據待檢測視訊是一整段讀入的還是逐次讀入的,分為online和offline兩種 Offline action detection: 特點:一次讀入一整段視訊,然後在這一整段視訊中定位動作發生的時間 Online action detection: 特點:不斷讀入新的幀,在讀入幀的過程中需要儘可能早的發現動作的發生(在動作尚未結束時就檢測到)。 同時online action detection 還需要滿足實時性要求,這點非常重要。 這導致online action detection不能採用計算複雜度過大的方法(在現有的計算能力下) 現有方法: 逐幀檢測法: 即在視訊序列的每幀上獨立判斷動作的型別,可以用CNN等方法,僅用上了spatial的資訊 滑窗法: 即設定一個固定的滑窗大小,在視訊序列上進行滑窗,然後對滑窗得到的視訊小片斷利用action recognition的方法進行分類。 現狀:由於此問題難度比action recognition高很多,所以現在還沒有效果較好的方法
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
1. 任務特點及分析
目的
給一個視訊片段進行分類,類別通常是各類人的動作
- 1
特點
簡化了問題,一般使用的資料庫都先將動作分割好了,一個視訊片斷中包含一段明確的動作,
時間較短(幾秒鐘)且有唯一確定的label。
所以也可以看作是輸入為視訊,輸出為動作標籤的多分類問題。
此外,動作識別資料庫中的動作一般都比較明確,周圍的干擾也相對較少(不那麼real-world)。
有點像影象分析中的Image Classification任務。
- 1
- 2
- 3
- 4
- 5
難點/關鍵點
強有力的特徵: 即如何在視訊中提取出能更好的描述視訊判斷的特徵。 特徵越強,模型的效果通常較好。 特徵的編碼(encode)/融合(fusion): 這一部分包括兩個方面, 第一個方面是非時序的,在使用多種特徵的時候如何編碼/融合這些特徵以獲得更好的效果; 另外一個方面是時序上的,由於視訊很重要的一個特性就是其時序資訊, 一些動作看單幀的影象是無法判斷的,只能通過時序上的變化判斷, 所以需要將時序上的特徵進行編碼或者融合,獲得對於視訊整體的描述。 演算法速度: 雖然在發論文刷資料庫的時候演算法的速度並不是第一位的。 但高效的演算法更有可能應用到實際場景中去.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
2. 常用資料庫
行為識別的資料庫比較多,這裡主要介紹兩個最常用的資料庫,也是近年這個方向的論文必做的資料庫。
1. UCF101:來源為YouTube視訊,共計101類動作,13320段視訊。
共有5個大類的動作:
1)人-物互動;
2)肢體運動;
3)人-人互動;
4)彈奏樂器;
5)運動。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2. HMDB51:來源為YouTube視訊,共計51類動作,約7000段視訊。 HMDB: a large human motion database
- 1
- 2
3. 在Actioin Recognition中,實際上還有一類骨架資料庫,
比如MSR Action 3D,HDM05,SBU Kinect Interaction Dataset等。
這些資料庫已經提取了每幀視訊中人的骨架資訊,基於骨架資訊判斷運動型別。
4. ACTIVITYNET Large Scale Activity Recognition Challenge
- 1
- 2
- 3
- 4
- 5
3. 研究進展
如今人體行為識別是計算機視覺研究的一個熱點,
人體行為識別的目標是從一個未知的視訊或者是影象序列中自動分析其中正在進行的行為。
簡單的行為識別即動作分類,給定一段視訊,只需將其正確分類到已知的幾個動作類別,
複雜點的識別是視訊中不僅僅只包含一個動作類別,而是有多個,
系統需自動的識別出動作的類別以及動作的起始時刻。
行為識別的最終目標是分析視訊中
哪些人 who
在什麼時刻 when
什麼地方, where
幹什麼事情, what
即所謂的“W4系統”
人體行為識別應用背景很廣泛,主要集中在智慧視訊監控,
病人監護系統,人機互動,虛擬現實,智慧家居,智慧安防,
運動員輔助訓練,另外基於內容的視訊檢索和智慧影象壓縮等
有著廣闊的應用前景和潛在的經濟價值和社會價值,
其中也用到了不少行為識別的方法。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
3.1 傳統方法
特徵綜述
密集軌跡演算法(DT演算法) iDT(improved dense trajectories)特徵
Action Recognition by Dense Trajectories
Action recognition with improved trajectories
- 1
- 2
[DT論文](Action Recognition by Dense Trajectories)
基本思路:
DT演算法的基本思路為利用光流場來獲得視訊序列中的一些軌跡,
再沿著軌跡提取HOF,HOG,MBH,trajectory4種特徵,其中HOF基於灰度圖計算,
另外幾個均基於dense optical flow計算。
最後利用FV(Fisher Vector)方法對特徵進行編碼,再基於編碼結果訓練SVM分類器。
而iDT改進的地方在於它利用前後兩幀視訊之間的光流以及SURF關鍵點進行匹配,
從而消除/減弱相機運動帶來的影響,改進後的光流影象被成為warp optical flow
總結:
A. 利用光流場來獲得視訊序列中的一些軌跡;
a. 通過網格劃分的方式在圖片的多個尺度上分別密集取樣特徵點,濾除一些變換少的點;
b. 計算特徵點鄰域內的光流中值來得到特徵點的運動速度,進而跟蹤關鍵點;
B. 沿軌跡提取HOF,HOG,MBH,trajectory,4種特徵
其中HOG基於灰度圖計算,
另外幾個均基於稠密光流場計算。
a. HOG, 方向梯度直方圖,分塊後根據畫素的梯度方向統計畫素的梯度幅值。
b. HOF, 光流直方圖,光流通過當前幀梯度矩陣和相鄰幀時間上的灰度變換矩陣計算得到,
之後再對光流方向進行加權統計。
c. MBH,運動邊界直方圖,實質為光流梯度直方圖。
d. Trajectories, 軌跡特徵,特徵點在各個幀上位置點的差值,構成軌跡變化特徵。
C.特徵編碼—Bag of Features;
a. 對訓練集資料提取上述特徵,使用K_means聚類演算法,對特徵進行聚類,得到特徵字典;
b. 使用字典單詞對測試資料進行量化編碼,得到固定長度大小的向量,可使用VQ或則SOMP演算法。
D. 使用SVM進行分類
對編碼量化之後的特徵向量使用SVM支援向量機進行分類。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
iDT(improved dense trajectories) 改進
1. 剔除相機運動引起的背景光流
a. 使用SURF特徵演算法匹配前後兩幀的 匹配點對,這裡會使用人體檢測,剔除人體區域的匹配點,運動量大,影響較大;
b. 利用光流演算法計算匹配點對,剔除人體區域的匹配點對;
c. 合併SURF匹配點對 和 光流匹配點對,利用RANSAC 隨機取樣序列一致性演算法估計前後兩幀的 單應投影變換矩陣H;
d. 利用矩陣H的逆矩陣,計算得到當前幀除去相機運動的狀態I’= H.inv * I ;
e. 計算去除相機運動後的幀I' 的 光流。
f. 光流演算法 Ft
假設1:光照亮度恆定:
I(x, y, t) = I(x+dx, y+dy, t+dt)
泰勒展開:
I(x+dx, y+dy, t+dt) =
I(x, y, t) + dI/dx * dx + dI/dy * dy + dI/dt * dt
= I(x, y, t) + Ix * dx + Iy * dy + It * dt
得到:
Ix * dx + Iy * dy + It * dt = 0
因為 畫素水平方向的運動速度 u=dx/dt, 畫素垂直方向的運動速度 v=dy/dt
等式兩邊同時除以 dt ,得到:
Ix * dx/dt + Iy * dy/dt + It = 0
Ix * u + Iy * v + It = 0
寫成矩陣形式:
[Ix, Iy] * [u; v] = -It, 式中Ix, Iy為影象空間畫素差值(梯度), It 為時間維度,畫素差值
假設2:區域性區域 運動相同
對於點[x,y]附近的點[x1,y1] [x2,y2] , ... , [xn,yn] 都具有相同的速度 [u; v]
有:
[Ix1, Iy1; [It1
Ix2, Iy2; It2
... * [u; v] = - ...
Ixn, Iyn;] Itn]
寫成矩陣形式:
A * U = b
由兩邊同時左乘 A逆 得到:
U = A逆 * b
由於A矩陣的逆矩陣可能不存在,可以曲線救國改求其偽逆矩陣
U = (A轉置*A)逆 * A轉置 * b
得到畫素的水平和垂直方向速度以後,可以得到:
速度幅值:
V = sqrt(u^2 + v^2)
速度方向:Cet = arctan(v/u)
2. 特徵歸一化方式
在iDT演算法中,對於HOF,HOG和MBH特徵採取了與DT演算法(L2範數歸一化)不同的方式。
L2範數歸一化 : Xi' = Xi/sqrt(X1^2 + ... + Xn^2)
L1正則化後再對特徵的每個維度開平方。
L1範數歸一化 : Xi' = Xi/(abs(X1) + ... + abs(Xn))
Xi'' = sqrt(Xi')
這樣做能夠給最後的分類準確率帶來大概0.5%的提升
3. 特徵編碼—Fisher Vector
特徵編碼階段iDT演算法不再使用Bag of Features/ BOVM方法,
(提取影象的SIFT特徵,通過(KMeans聚類),VQ向量量化,構建視覺詞典(碼本))
而是使用效果更好的Fisher Vector編碼.
FV採用混合高斯模型(GMM)構建碼本,
但是FV不只是儲存視覺詞典的在一幅影象中出現的頻率,
並且FV還統計視覺詞典與區域性特徵(如SIFT)的差異
Fisher Vector同樣也是先用大量特徵訓練碼書,再用碼書對特徵進行編碼。
在iDT中使用的Fisher Vector的各個引數為:
1. 用於訓練的特徵長度:trajectory+HOF+HOG+MBH = 30+96+108+192 = 426維
2. 用於訓練的特徵個數:從訓練集中隨機取樣了256000個
3. PCA降維比例:2,即維度除以2,降維後特徵長度為 D = 426 / 2 = 213。
先降維,後編碼
4. Fisher Vector中 高斯聚類的個數K:K=256
故編碼後得到的特徵維數為2*K*D個,即109056維。
在編碼後iDT同樣也使用了SVM進行分類。
在實際的實驗中,推薦使用liblinear,速度比較快。
4. 其他改進思想
原先是沿著軌跡提取手工設計的特徵,可以沿著軌跡利用CNN提取特徵。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
Fisher Vector 特徵編碼 主要思想是使用高斯分佈來擬合單詞 而不是簡簡單單的聚類產生中心點
在一般的分類問題中,通常的套路都是提取特徵,將特徵輸入分類器訓練,得到最終的模型。
但是在具體操作時,一開始提出的特徵和輸入分類器訓練的特徵是不一樣的。
比如假設有N張100×100的影象,分別提取它們的HoG特徵x∈Rp×q,p為特徵的維數,q為這幅影象中HoG特徵的個數。
如果把直接把這樣的一萬個x直接投入分類器訓練,效果不一定好,
因為不一定每個畫素點的資訊都是有價值的,裡面可能有很多是冗餘的資訊。
而且特徵維度太高會導致最終的訓練時間過長。
所以通常會對raw features做一些預處理。最常用的就是詞袋模型(bag of words)。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
K-means是最常用的聚類方法之一,我們的例子中,有N幅影象,每幅影象有x∈Rp×q的特徵,
那麼所有資料的特徵矩陣為X∈Rp×Nq。也就是說現在一共存在Nq個數據點,它們分佈在一個p維的空間中,
通過聚類後可以找到M個聚類中心。然後對於每一幅影象而言,
分別計算它的q個p維特徵屬於哪一個聚類中心(距離最近),最終統計M個聚類中心分別擁有多少特徵,
得到一個M維的向量。這個向量就是最終的特徵。
k-means的缺點在於,它是一個hard聚類的方法,比如有一個點任何一個聚類中心都不屬於,
但是詞袋模型仍然可能會把它強行劃分到一個聚類中心去。
對於一個點,它屬不屬於某個聚類中心的可能性是個屬於(0,1)的整數值。
相反,高斯混合模型(Gaussian Mixture Model) 就是一種soft聚類的方法,
它建立在一個重要的假設上,即任意形狀的概率分佈都可以用多個高斯分佈函式去近似。
類似傅立葉變換,任何訊號曲線都可以用正餘弦函式來近似。
顧名思義,高斯混合模型是由很多個高斯分佈組成的模型,每一個高斯分佈都是一個component。
每一個component Nk∼(μk,σk),k=1,2,…K對應的是一個聚類中心,這個聚類中心的座標可以看作(μk,σk)
一般解高斯混合模型都用的是EM演算法(期望最大化演算法)。
EM演算法分為兩步:
在E-step中,估計資料由每個component生成的概率。
假設μ,Σ,ϕ已知,對於每個資料 xi 來說,它由第k個component 生成的概率為
在M-step中,估計每個component的引數μk,Σk,πkk=1,…K。
利用上一步得到的pik,它是對於每個資料 xi 來說,它由第k個component生成的概率,
也可以當做第k個component在生成這個資料上所做的貢獻,或者說,
我們可以看作 xi這個值其中有pikxi 這部分是由 第k個component所生成的。
現在考慮所有的資料,可以看做第k個component生成了 p1kx1,…,pNkxN 這些點。
由於每個component 都是一個標準的 Gaussian 分佈,可以很容易的根據期望、方差的定義求出它們:
重複迭代前面兩步,直到似然函式的值收斂為止。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
FV採用GMM構建視覺詞典,為了視覺化,這裡採用二維的資料,
然這裡的資料可以是SIFT或其它區域性特徵,
具體實現程式碼如下:
%採用GMM模型對資料data進行擬合,構建視覺詞典
numFeatures = 5000 ; %樣本數
dimension = 2 ; %特徵維數
data = rand(dimension,numFeatures) ; %這裡隨機生成一些資料,這裡data可以是SIFT或其它區域性特徵
numClusters = 30 ; %視覺詞典大小
[means, covariances, priors] = vl_gmm(data, numClusters); %GMM擬合data資料分佈,構建視覺詞典
這裡得到的means、covariances、priors分別為GMM的均值向量,協方差矩陣和先驗概率,也就是GMM的引數。
這裡用GMM構建視覺詞典也存在一個問題,這是GMM模型固有的問題,
就是當GMM中的高斯函式個數,也就是聚類數,也就是numClusters,
若與真實的聚類數不一致的話,
GMM表現的不是很好(針對期望最大化EM方法估計引數),具體請參見GMM。
接下來,我們建立另一組隨機向量,這些向量用Fisher Vector和剛獲得的GMM來編碼,
具體程式碼如下:
numDataToBeEncoded = 1000;
dataToBeEncoded = rand(dimension,numDataToBeEncoded); %2*1000維資料
% 進行FV編碼
encoding = vl_fisher(datatoBeEncoded, means, covariances, priors);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
idt演算法總結
1、密集取樣:
多尺度(8個)
間隔取樣(5)
無紋理區域點的剔除
2、光流法跟蹤:
I(x, y, t) = I(x+dx, y+dy, t+dt)
泰勒展開:
[Ix, Iy] * [u; v] = -It
區域性區域 運動相同:
A * U = b
U = (A轉置*A)逆 * A轉置 * b 偽逆求解
光流中指濾波:
Pt+1=(xt+1,yt+1)=(xt,yt)+(M∗Ut)|xt,yt
3、特徵計算:
區域選取:
1、選取相鄰L幀(15);
2、對每條軌跡在每個幀上取N*N
的畫素區域(32*32)
3、對上述區域劃分成nc*nc個
格子(2*2)
4、在時間空間上劃分成nt段(3段)
5、這樣就有 nc*nc*nt個空間劃
分割槽域。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
傳統視訊行為分析演算法總結
a. 特徵提取方法
1. 方向梯度直方圖 HOG
影象平面畫素水平垂直誤差;
再求和成梯度幅值和梯度方向;
劃分梯度方向,按梯度大小加權統計。
2. 光流直方圖 HOF
需要梯度圖和時間梯度圖來計算畫素水平和垂直速度,
再求合成速度幅值和方向,
按上面的方式統計。
這裡還可以使用 目標檢測 去除背景光溜,只保留人體區域的光流。
3. 光流梯度直方圖 MBH
在光流圖上計算水平和垂直光流梯度,
計算合成光流梯度幅值和方向,
再統計。
4. 軌跡特徵 Trajectories,
匹配點按照光流速度得到座標,
獲取相鄰幀匹配點的座標差值;
按一條軌跡串聯起來;
正則化之後就是一個軌跡特徵。
5. 人體骨骼特徵
通過RGB影象進行關節點估計(Pose Estimation)獲得;
或是通過深度攝像機直接獲得(例如Kinect)。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
b. 特徵歸一化方法
L2範數歸一化 :
Xi' = Xi/sqrt(X1^2 + ... + Xn^2)
L1範數歸一化後再對特徵的每個維度開平方。
L1範數歸一化 : Xi' = Xi/(abs(X1) + ... + abs(Xn))
開平方 :Xi'' = sqrt(Xi')
- 1
- 2
- 3
- 4
- 5
c. 特徵編碼方法
1) 視覺詞袋BOVM模型
1. 使用K_mean聚類演算法對訓練資料集特徵集合進行聚類,
得到特徵單詞字典;
2. 使用向量量化VQ演算法 或者 同步正交匹配追蹤SOMP演算法
對分割後的測試樣本資料的特徵 用特徵單詞字典進行編碼;
3.計算一個視訊的 字典單詞 的視訊表示向量,得到視訊的特徵向量。
2) Fisher Vector 特徵編碼,高斯混合模型擬閤中心點
1. 使用高斯混合模型GMM演算法提取訓練集特徵中的聚類資訊,得到 K個高斯分佈表示的特徵單詞字典;
2. 使用這組組K個高斯分佈的線性組合來逼近這些 測試集合的特徵,也就是FV編碼.
Fisher vector本質上是用似然函式的梯度vector來表達一幅影象, 說白了就是資料擬閤中對引數調優的過程。
由於每一個特徵是d維的,需要K個高斯分佈的線性組合,有公式5,一個Fisher vector的維數為(2*d+1)*K-1維。
3.計算一個視訊的 字典單詞 的視訊表示向量,得到視訊的特徵向量。
Fisher Vector步驟總結:
1.選擇GMM中K的大小
1.用訓練圖片集中所有的特徵(或其子集)來求解GMM(可以用EM方法),得到各個引數;
2.取待編碼的一張影象,求得其特徵集合;
3.用GMM的先驗引數以及這張影象的特徵集合按照以上步驟求得其fv;
4.在對訓練集中所有圖片進行2,3兩步的處理後可以獲得fishervector的訓練集,然後可以用SVM或者其他分類器進行訓練。
3) 兩種編碼方式對比
經過fisher vector的編碼,大大提高了影象特徵的維度,能夠更好的用來描述影象。
FisherVector相對於BOV的優勢在於,BOV得到的是一個及其稀疏的向量,
由於BOV只關注了關鍵詞的數量資訊,這是一個0階的統計資訊;
FisherVector並不稀疏,同時,除了0階資訊,
Fisher Vector還包含了1階(期望)資訊、2階(方差資訊),
因此FisherVector可以更加充分地表示一幅圖片。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
d. 視訊分割 類似語言識別中的 間隔點檢測
1) 動態時間規整DTW
- 1
1) 按b的方法提取訓練集和測試集的特徵
2) 計算訓練集和測試集特徵相似度距離
3) 使用動態規劃演算法為測試機樣本在訓練集中找出最匹配的一個
4) 對訓練集剩餘部分採用3) 的方法依次找出最匹配的一個
1)輸入:
1. 所有單個訓練視訊樣本的量化編碼後的特徵向量.
2. 包含多個行為動作的測試視訊的量化編碼後的特徵向量.
2)演算法描述:
1. 測試樣本特徵向量 和 多個訓練樣本特徵向量分別計算特徵匹配距離。
2. 單個測試視訊的每一幀的特徵向量和測試視訊的每一幀的特徵向量計算相似度(歐氏距離).
3. 以訓練視訊的最後一幀的特徵向量和測試視訊的每一幀的特徵向量的距離點位起點,
使用 動態規劃 的方法,找出一條最優匹配路徑,最後計算路徑上特徵匹配距離之和,
找出一個最小的,對應的分割點即為測試視訊與當前訓練樣本的最優匹配。
4. 迭代找出測試視訊樣本和其他訓練樣本的最有匹配,得到最優匹配距離。
5. 在所有的好的匹配距離中找出一個最小的距離,即為對應測試視訊匹配的行為動作。
6. 將測試視訊中已經分割出去的視訊序列剔除,剩餘的視訊重複1~5的步驟,獲取對應的標籤和時間分割資訊。
2) CDP
3) HMM
1) 將訓練集的每一種行為當成系統的隱含狀態
2) 根據測試視訊這個可見狀態鏈推測最有可能的隱含狀態鏈
3)需要求的每種隱含狀態之間的狀態轉移概率,
以及每種隱含狀態輸出一個可見狀態的概率。
4) 使用維特比演算法進行求解出一個最大概率的隱含狀態鏈(即行為狀態序列)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
1) 將訓練集的每一種行為當成系統的隱含狀態
2) 根據測試視訊這個可見狀態鏈推測最有可能的隱含狀態鏈
3)需要求的每種隱含狀態之間的狀態轉移概率,
以及每種隱含狀態輸出一個可見狀態的概率。
4) 使用維特比演算法進行求解出一個最大概率的隱含狀態鏈(即行為狀態序列)
4) 深度學習的方法分割動作
DTW/HMM/CRBM/高斯過程
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
e. 分類器分類
1. SVM 支援向量機進行分類。
2. KNN 最近鄰分類器進行分類。
- 1
- 2
3.2 深度學習方法
時空雙流網路結構 Two Stream Network及衍生方法
空時注意力模型(Attention)之於行為識別
- 1
提出
Two Stream方法最初在這篇文章中被提出:
在空間部分,以單個幀上的外觀形式,攜帶了視訊描繪的場景和目標資訊。
其自身靜態外表是一個很有用的線索,因為一些動作很明顯地與特定的目標有聯絡。
在時間部分,以多幀上的運動形式,表達了觀察者(攝像機)和目標者的運動。
基本原理為:
1. 對視訊序列中每兩幀計算密集光流,得到密集光流的序列(即temporal資訊)。
2. 然後對於視訊影象(spatial)和密集光流(temporal)分別訓練CNN模型,
兩個分支的網路分別對動作的類別進行判斷,
3. 最後直接對兩個網路的class score進行fusion(包括直接平均和svm兩種方法),得到最終的分類結果。
注意,對與兩個分支使用了相同的2D CNN網路結構,其網路結構見下圖。
實驗效果:UCF101-88.0%,HMDB51-59.4%
結構:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14

光流 和 軌跡
- 1

改進1 CNN網路進行了spatial以及temporal的融合

這篇論文的主要工作為:
1. 在two stream network的基礎上,
利用CNN網路進行了spatial以及temporal的融合,從而進一步提高了效果。
2. 此外,該文章還將基礎的spatial和temporal網路都換成了VGG-16 network。
實驗效果:UCF101-92.5%,HMDB51-65.4%
- 1
- 2
- 3
- 4
- 5
改進2 LSTM網路 融合雙流 spatial以及temporal
這篇文章主要是用LSTM來做two-stream network的temporal融合。效果一般
- 1
TSN 結構
這篇文章是港中文Limin Wang大神的工作,他在這方面做了很多很棒的工作,
可以followt他的主頁:http://wanglimin.github.io/ 。
這篇文章提出的TSN網路也算是spaital+temporal fusion,結構圖見下圖。
這篇文章對如何進一步提高two stream方法進行了詳盡的討論,主要包括幾個方面(完整內容請看原文):
1. 據的型別:除去two stream原本的RGB image和 optical flow field這兩種輸入外,
章中還嘗試了RGB difference及 warped optical flow field兩種輸入。
終結果是 RGB+optical flow+warped optical flow的組合效果最好。
2. 構:嘗試了GoogLeNet,VGGNet-16及BN-Inception三種網路結構,其中BN-Inception的效果最好。
3. 包括 跨模態預訓練,正則化,資料增強等。
4. 果:UCF101-94.2%,HMDB51-69.4%
two-stream 卷積網路對於長範圍時間結構的建模無能為力,
主要因為它僅僅操作一幀(空間網路)或者操作短片段中的單堆幀(時間網路),
因此對時間上下文的訪問是有限的。
視訊級框架TSN可以從整段視訊中建模動作。
和two-stream一樣,TSN也是由空間流卷積網路和時間流卷積網路構成。
但不同於two-stream採用單幀或者單堆幀,TSN使用從整個視訊中稀疏地取樣一系列短片段,
每個片段都將給出其本身對於行為類別的初步預測,從這些片段的“共識”來得到視訊級的預測結果。
在學習過程中,通過迭代更新模型引數來優化視訊級預測的損失值(loss value)。
TSN網路示意圖如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
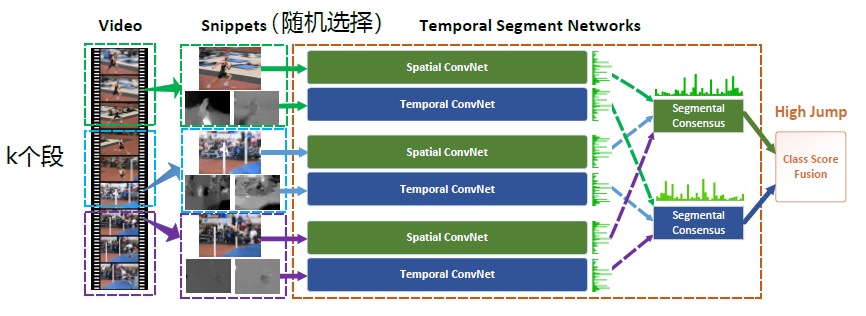
由上圖所示,一個輸入視訊被分為 K 段(segment),一個片段(snippet)從它對應的段中隨機取樣得到。
不同片段的類別得分採用段共識函式(The segmental consensus function)
進行融合來產生段共識(segmental consensus),這是一個視訊級的預測。
然後對所有模式的預測融合產生最終的預測結果。
具體來說,給定一段視訊 V,把它按相等間隔分為 K 段 {S1,S2,⋯,SK}。
接著,TSN按如下方式對一系列片段進行建模:
TSN(T1,T2,⋯,TK)=H(G(F(T1;W),F(T2;W),⋯,F(TK;W)))
其中:
(T1,T2,⋯,TK) 代表片段序列,每個片段 Tk 從它對應的段 Sk 中隨機取樣得到。
F(Tk;W) 函式代表採用 W 作為引數的卷積網路作用於短片段 Tk,函式返回 Tk 相對於所有類別的得分。
段共識函式 G(The segmental consensus function)結合多個短片段的類別得分輸出以獲得他們之間關於類別假設的共識。
基於這個共識,預測函式 H 預測整段視訊屬於每個行為類別的概率(本文 H 選擇了Softmax函式)。
結合標準分類交叉熵損失(cross-entropy loss);
網路結構
一些工作表明更深的結構可以提升物體識別的表現。
然而,two-stream網路採用了相對較淺的網路結構(ClarifaiNet)。
本文選擇BN-Inception (Inception with Batch Normalization)構建模組,
由於它在準確率和效率之間有比較好的平衡。
作者將原始的BN-Inception架構適應於two-stream架構,和原始two-stream卷積網路相同,
空間流卷積網路操作單一RGB影象,時間流卷積網路將一堆連續的光流場作為輸入。
網路輸入
TSN通過探索更多的輸入模式來提高辨別力。
除了像two-stream那樣,
空間流卷積網路操作單一RGB影象,
時間流卷積網路將一堆連續的光流場作為輸入,
作者提出了兩種額外的輸入模式:
RGB差異(RGB difference)和
扭曲的光流場(warped optical flow fields,idt中去除相機運動後的光流)。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
TSN改進版本之一 加權融合
改進的地方主要在於fusion部分,不同的片段的應該有不同的權重,而這部分由網路學習而得,最後由SVM分類得到結果。
- 1
TSN改進版本二 時間推理
這篇是MIT周博磊大神的論文,作者是也是最近提出的資料集 Moments in time 的作者之一。
該論文關注時序關係推理。
對於哪些僅靠關鍵幀(單幀RGB影象)無法辨別的動作,如摔倒,其實可以通過時序推理進行分類。
除了兩幀之間時序推理,還可以拓展到更多幀之間的時序推理。
通過對不同長度視訊幀的時序推理,最後進行融合得到結果。
該模型建立TSN基礎上,在輸入的特徵圖上進行時序推理。
增加三層全連線層學習不同長度視訊幀的權重,及上圖中的函式g和h。
除了上述模型外,還有更多關於時空資訊融合的結構。
這部分與connection部分有重疊,所以僅在這一部分提及。
這些模型結構相似,區別主要在於融合module的差異,細節請參閱論文。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
LSTM 結構融合雙流特徵
這篇文章主要是用LSTM來做two-stream network的temporal融合。效果一般
實驗效果:UCF101-88.6%
- 1
- 2
RNN的展開結構 ht = f(w1*xt + w2*ht-1 + b) 複合函式+遞推數列
後一項的值由前一項的值ht-1 和 當前時刻的輸入值xt 決定,有機會通過當前的輸入值改變自己的命運。
ht-1提現了記憶功能,ht-1是由ht-2和xt-1所決定,所以ht的值實際上是由 x1, x2, x3,..., xt決定的,
它記住了之前完整的序列資訊。
- 1
- 2
- 3
- 4
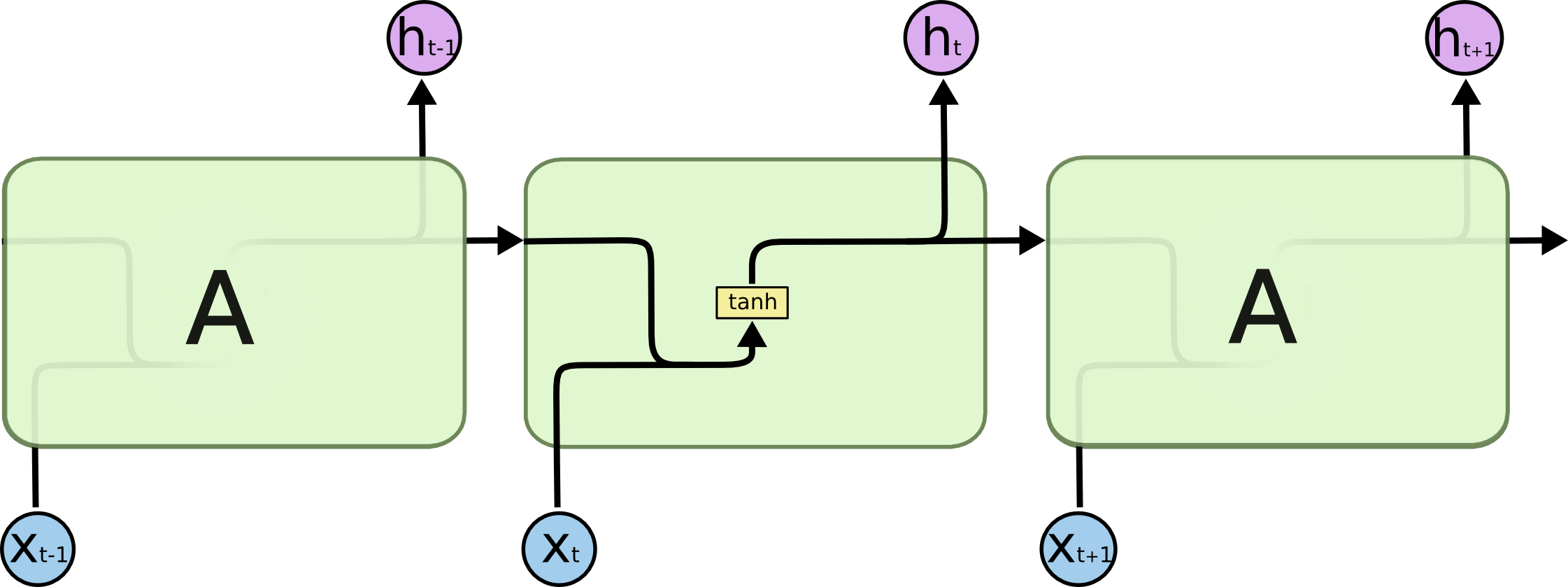
LSTM的展開結構
- 1
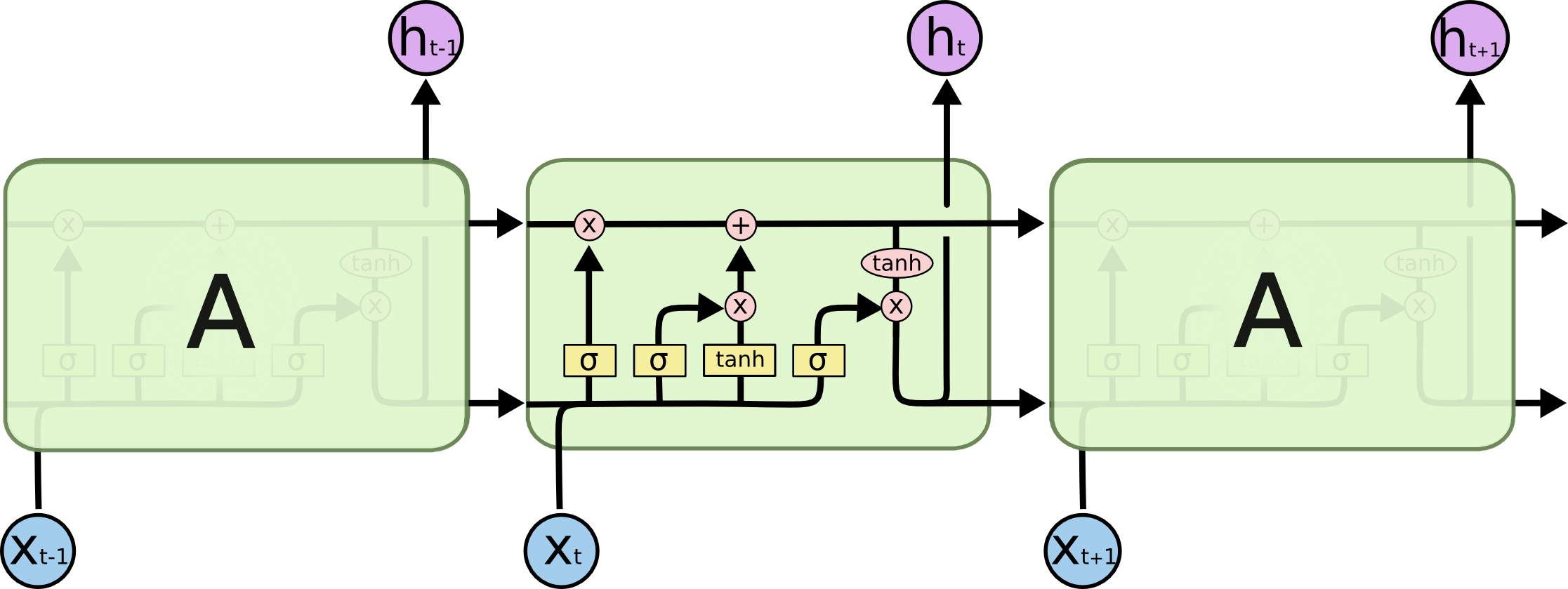
LSTM 功能
- 1
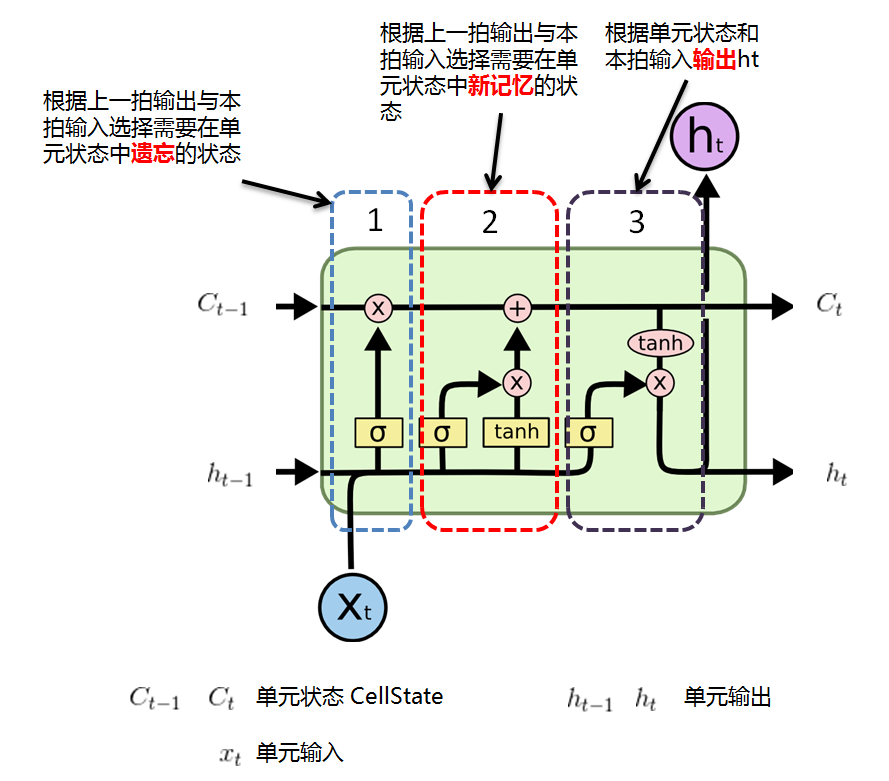
行為識別 人體骨架檢測+LSTM
人體骨架怎麼獲得呢?
主要有兩個途徑:
通過RGB影象進行關節點估計(Pose Estimation openpose工具箱)獲得,
或是通過深度攝像機直接獲得(例如Kinect)。
每一時刻(幀)骨架對應人體的K個關節點所在的座標位置資訊,一個時間序列由若干幀組成。
- 1
- 2
- 3
- 4
- 5
思路:
在視訊上先對每一幀做姿態估計(Kinetics 資料集上文章用的是OpenPose),然後可以構建出一個空間上的骨架時序圖。
然後應用ST-GCN網路提取高層特徵
最後用softmax分類器進行分類
- 1
- 2
- 3
- 4
1. 空時注意力模型(Attention)之於行為識別
LSTM網路框架和關節點共現性(Co-occurrence)的挖掘之於行為識別。
時域注意力模型:
設計了時域注意力模型,通過一個LSTM子網路來自動學習和獲知序列中不同幀的重要性,
使重要的幀在分類中起更大的作用,以優化識別的精度。
空域注意力:
設計了一個LSTM子網路,依據序列的內容自動給不同關節點分配不同的重要性,即給予不同的注意力。
由於注意力是基於內容的,即當前幀資訊和歷史資訊共同決定的,
因此,在同一個序列中,關節點重要性的分配可以隨著時間的變化而改變。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2. LSTM網路框架和關節點共現性(Co-occurrence)的挖掘之於行為識別
3. RNN 基於聯合分類和迴歸的迴圈神經網路之於行為動作檢測
3D卷積 C3D Network
提出 C3D
C3D是facebook的一個工作,採用3D卷積和3D Pooling構建了網路。
通過3D卷積,C3D可以直接處理視訊(或者說是視訊幀的volume)
實驗效果:UCF101-85.2% 可以看出其在UCF101上的效果距離two stream方法還有不小差距。
我認為這主要是網路結構造成的,C3D中的網路結構為自己設計的簡單結構,如下圖所示。
速度:
C3D的最大優勢在於其速度,在文章中其速度為314fps。而實際上這是基於兩年前的顯示卡了。
用Nvidia 1080顯示卡可以達到600fps以上。
所以C3D的效率是要遠遠高於其他方法的,個人認為這使得C3D有著很好的應用前景。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
改進 I3D[Facebook]
即基於inception-V1模型,將2D卷積擴充套件到3D卷積。
- 1
T3D 時空 3d卷積
該論文值得注意的,
一方面是採用了3D densenet,區別於之前的inception和Resnet結構;
另一方面,TTL層,即使用不同尺度的卷積(inception思想)來捕捉訊息。
- 1
- 2
- 3
P3D [MSRA]
改進ResNet內部連線中的卷積形式。然後,超深網路,一般人顯然只能空有想法,望而卻步。
- 1
CDC 3D卷積方式的 改進 TPC 時序保留卷積 這裡也是 行為檢測
思路:
這篇文章是在CDC網路的基礎進行改進的,CDC最後是採用了時間上上取樣,
空間下采樣的方法做到了 per-frame action predictions,而且取得了可信的行為定位的結果。
但是在CDC filter之前時間上的下采樣存在一定時序資訊的丟失。
作者提出的TPC網路,採用時序保留卷積操作,
這樣能夠在不進行時序池化操作的情況下獲得同樣大小的感受野而不縮短時序長度。
- 1
- 2
- 3
- 4
- 5
- 6
其他方法
TPP Temporal Pyramid Pooling
Pooling。時空上都進行這種pooling操作,旨在捕捉不同長度的訊息。
- 1
TLE 時序線性編碼層
1. 本文主要提出了“Temporal Linear Encoding Layer” 時序線性編碼層,主要對視訊中不同位置的特徵進行融合編碼。
至於特徵提取則可以使用各種方法,文中實驗了two stream以及C3D兩種網路來提取特徵。
2. 實驗效果:UCF101-95.6%,HMDB51-71.1% (特徵用two stream提取)。
應該是目前為止看到效果最好的方法了(CVPR2017裡可能會有更好的效果)
- 1
- 2
- 3
- 4
- 5
key volume的自動識別
本文主要做的是key volume的自動識別。
通常都是將一整段動作視訊進行學習,而事實上這段視訊中有一些幀與動作的關係並不大。
因此進行關鍵幀的學習,再在關鍵幀上進行CNN模型的建立有助於提高模型效果。
本文達到了93%的正確率嗎,為目前最高。
實驗效果:UCF101-93.1%,HMDB51-63.3%
- 1
- 2
- 3
- 4
- 5
使用LSTM,RNN迴圈神經網路來完成時間上的建模
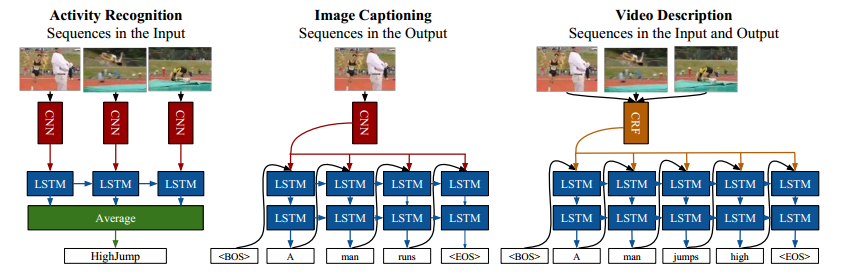
資料資料的提純
輸入一方面指輸入的資料型別和格式,也包括資料增強的相關操作。
雙流網路中,空間網路通道的輸入格式通常為單RGB影象或者是多幀RGB堆疊。
而空間網路一般是直接對ImageNet上經典的網路進行finetune。
雖然近年來對motion資訊的關注逐漸上升,指責行為識別過度依賴背景和外貌特徵,
而缺少對運動本身的建模,但是,事實上,運動既不是名詞,
也不應該是動詞,而應該是動詞+名詞的形式,例如:play+basketball,也可以是play+football。
所以,個人認為,雖然應該加大的時間資訊的關注,但不可否認空間特徵的重要作用。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
空間流上 改進 提取關鍵幀
空間網路主要捕捉視訊幀中重要的物體特徵。
目前大部分公開資料集其實可以僅僅依賴單影象幀就可以完成對視訊的分類,
而且往往不需要分割,那麼,在這種情況下,
空間網路的輸入就存在著很大的冗餘,並且可能引入額外的噪聲。
是否可以提取出視訊中的關鍵幀來提升分類的水平呢?下面這篇論文就提出了一種提取關鍵幀的方法。
- 1
- 2
- 3
- 4
- 5
- 6
提取關鍵幀 改進
雖然上面的方法可以整合到一個網路中訓練,
但是思路是按照影象分類演算法RCNN中需要分步先提出候選框,挑選出關鍵幀。
既然挑選前需要輸入整個視訊,可不可以省略挑選這個步驟,
直接在卷積/池化操作時,重點關注那些關鍵幀,而忽視那些冗餘幀呢?
去年就有人提出這樣的解決方法。
- 1
- 2
- 3
- 4
- 5
注:AdaScan的效果一般,關鍵幀的質量比上面的Key Volume Mining效果要差一點。不過模型整體比較簡單。
- 1
時間流 上輸入的改進 光流資訊
輸入方面,空間網路目前主要集中在關鍵幀的研究上。
而對於temporal通道而言,則是更多人的關注焦點。
首先,光流的提取需要消耗大量的計算力和時間(有論文中提到幾乎佔據整個訓練時間的90%);
其次,光流包含的未必是最優的的運動特徵。
- 1
- 2
- 3
- 4
cnn網路自學習 光流提取
那麼,光流這種運動特徵可不可以由網路自己學呢?
- 1
該論文主要參考了flownet,即使用神經網路學習生成光流圖,然後作為temporal網路的輸入。
該方法提升了光流的質量,而且模型大小也比flownet小很多。
有論文證明,光流質量的提高,尤其是對於邊緣微小運動光流的提升,對分類有關鍵作用。
另一方面,該論文中也比較了其餘的輸入格式,如RGB diff。但效果沒有光流好。
目前,除了可以考慮嘗試新的資料增強方法外,如何訓練出替代光流的運動特徵應該是接下來的發展趨勢之一。
- 1
- 2
- 3
- 4
- 5
- 6
資訊的融合
這裡連線主要是指雙流網路中時空資訊的互動。
一種是單個網路內部各層之間的互動,如ResNet/Inception;
一種是雙流網路之間的互動,包括不同fusion方式的探索,
目前值得考慮的是參照ResNet的結構,連線雙流網路。
- 1
- 2
- 3
- 4
基於 ResNet 的雙流融合
空間和時序網路的主體都是ResNet,
增加了從Motion Stream到Spatial Stream的互動。論文還探索多種方式。
- 1
- 2
金字塔 雙流融合
行為識別的關鍵就在於如何很好的融合空間和時序上的特徵。
作者發現,傳統雙流網路雖然在最後有fusion的過程,但訓練中確實單獨訓練的,
最終結果的失誤預測往往僅來源於某一網路,並且空間/時序網路各有所長。
論文分析了錯誤分類的原因:
空間網路在視訊背景相似度高的時候容易失誤,
時序網路在long-term行為中因為snippets length的長度限制容易失誤。
那麼能否通過互動,實現兩個網路的互補呢?
該論文重點在於STCB模組,詳情請參閱論文。
互動方面,在保留空間、時序流的同時,對時空資訊進行了一次融合,最後三路融合,得出最後結果
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
SSN(structured segment network,結構化的段網路)
通過結構化的時間金字塔對每個行為例項的時間結構進行建模。
金字塔頂層有decomposed discriminative model(分解判別模型),
包含兩個分類器:用於分類行為(針對recognition)和確定完整性(針對localization)。
整合到統一的網路中,可以以端到端的方式高效地進行訓練。
為了提取高質量行為時間proposal,採用temporal actionness grouping (TAG)演算法。
- 1
- 2
- 3
- 4
- 5
這兩篇論文從pooling的層面提高了雙流的互動能力
基於ResNet的結構探索新的雙流連線方式
4. 視訊行為檢測
CDC 用於未修剪視訊中精確時間動作定位的卷積-反-卷積網路

CDC網路[13]是在C3D網路基礎上,借鑑了FCN的思想。
在C3D網路的後面增加了時間維度的上取樣操作,做到了幀預測(frame level labeling)。
1、第一次將卷積、反捲積操作應用到行為檢測領域,CDC同時在空間下采樣,在時間域上上取樣。
2、利用CDC網路結構可以做到端到端的學習。
3、通過反捲積操作可以做到幀預測(Per-frame action labeling)。
- 1
- 2
- 3
- 4
- 5
- 6

CDC6 反捲積
3DCNN能夠很好的學習時空的高階語義抽象,但是丟失了時間上的細粒度,
眾所周知的C3D架構輸出視訊的時序長度減小了8倍
在畫素級語義分割中,反捲積被證明是一種有效的影象和視訊上取樣的方法,
用於產生與輸入相同解析度的輸出。
對於時序定位問題,輸出的時序長度應該和輸入視訊一致,
但是輸出大小應該被減小到1x1。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
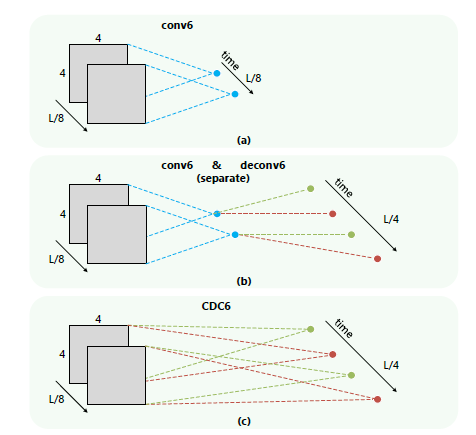
網路步驟如下所示:
輸入的視訊段是112x112xL,連續L幀112x112的影象
經過C3D網路後,時間域上L下采樣到 L/8, 空間上影象的大小由 112x112下采樣到了4x4
CDC6: 時間域上上取樣到 L/4, 空間上繼續下采樣到 1x1
CDC7: 時間域上上取樣到 L/2
CDC8:時間域上上取樣到 L,而且全連線層用的是 4096xK+1, K是類別數
softmax層
- 1
- 2
- 3
- 4
- 5
- 6
- 7
R-C3D(Region 3-Dimensional Convolution)網路
是基於Faster R-CNN和C3D網路思想。
對於任意的輸入視訊L,先進行Proposal,然後用3D-pooling,最後進行分類和迴歸操作。
文章主要貢獻點有以下3個。
1、可以針對任意長度視訊、任意長度行為進行端到端的檢測
2、速度很快(是目前網路的5倍),通過共享Progposal generation 和Classification網路的C3D引數
3、作者測試了3個不同的資料集,效果都很好,顯示了通用性。
- 1
- 2
- 3
- 4
- 5
- 6
R-C3D網路可以分為4個部分
1、特徵提取網路:對於輸入任意長度的視訊使用C3D進行特徵提取;
2、Temporal Proposal Subnet: 用來提取可能存在行為的時序片段(Proposal Segments);
3、Activity Classification Subnet: 行為分類子網路;
4、Loss Function。
- 1
- 2
- 3
- 4
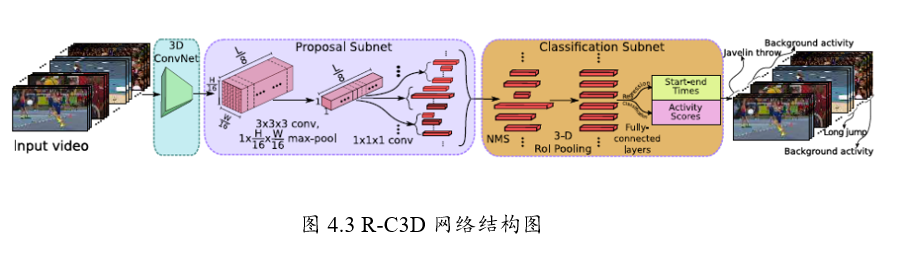
1、特徵提取網路
骨幹網路作者選擇了C3D網路,經過C3D網路的5層卷積後,
可以得到512 x L/8 x H/16 x W/16大小的特徵圖。
這裡不同於C3D網路的是,R-C3D允許任意長度的視訊L作為輸入。
- 1
- 2
- 3
2、時序候選區段提取網路
類似於Faster R-CNN中的RPN,用來提取一系列可能存在目標的候選框。
這裡是提取一系列可能存在行為的候選時序。
- 1
- 2
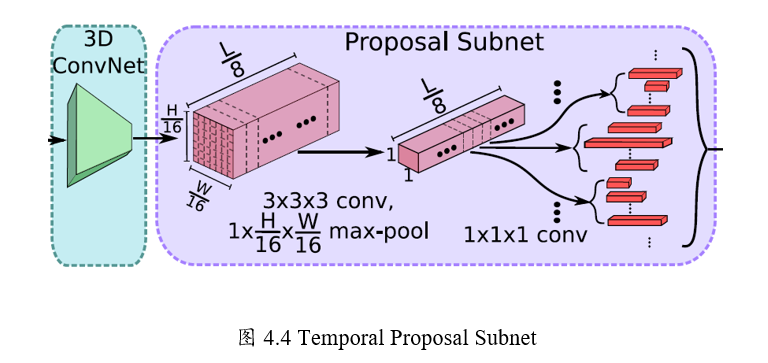
Step1:候選時序生成
輸入視訊經過上述C3D網路後得到了512 x L/8 x H/16 x W/16大小的特徵圖。
然後作者假設anchor均勻分佈在L/8的時間域上,
也就是有L/8個anchors,
每個anchors生成K個不同scale的候選時序。
Step2: 3D Pooling
得到的 512xL/8xH/16xW/16的特徵圖後,
為了獲得每個時序點(anchor)上每段候選時序的中心位置偏移和時序的長度,
作者將空間上H/16 x W/16的特徵圖經過一個3x3x3的卷積核
和一個3D pooling層下采樣到 1x1。最後輸出 512xL/8x1x1.
Step3: Training
類似於Faster R-CNN,這裡也需要判定得到的候選時序是正樣本還是負樣本。\
文章中的判定如下。
正樣本:IoU > 0.7,候選時序幀和ground truth的重疊數
負樣本: IOU < 0.3
為了平衡正負樣本,正/負樣本比例為1:1.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
3、行為分類子網路
行為分類子網路有如下幾個功能:
1、從TPS(Temporal Proposal subnet)中選擇出Proposal segment
2、對於上述的proposal,用3D RoI 提取固定大小特徵
3、以上述特徵為基礎,將選擇的Proposal做類別判斷和時序邊框迴歸。
- 1
- 2
- 3
- 4
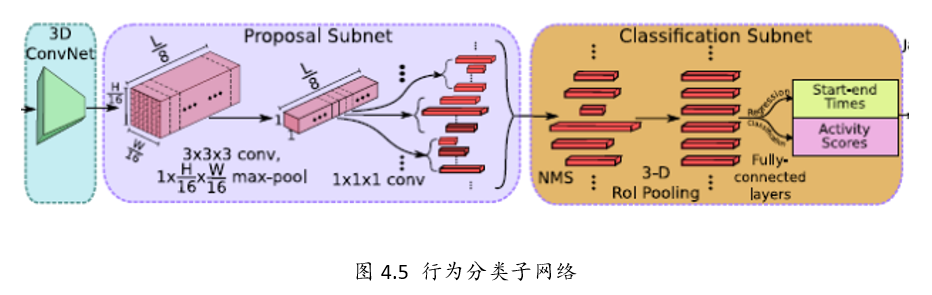
Step1: NMS
針對上述Temporal Proposal Subnet提取出的segment,
採用NMS(Non-maximum Suppression)非極大值抑制生成優質的proposal。
NMS 閾值為0.7.
Step2:3D RoI
RoI (Region of interest,興趣區域).
這裡,個人感覺作者的圖有點問題,提取興趣區域的特徵圖的輸入應該是C3D的輸出,
也就是512xL/8xH/16xW/16,可能作者