
sklearn系列之----線性迴歸
阿新 • • 發佈:2019-01-04
原理
線性迴歸,原理很簡單,就是擬合一條直線使得損失最小,損失可以有很多種,比如平方和最小等等;
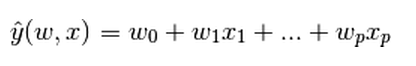
y是輸出,x是輸入,輸出是輸入的一個線性組合。
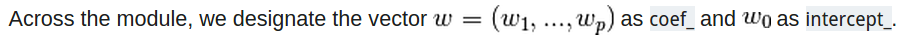
係數矩陣就是coef,截距就是intercept;
例子:
我們的輸入和輸出是numpy的ndarray,輸入是類似於列向量的,輸出類似於行向量,看它們各自的shape就是:
輸出:y.shape ——>(1,)
輸入:x.shape——->(m,1) #m是一個數字
大家記得不要把形式弄錯啦,不然可就走不起來了;
下面是個最簡單的例子:
>>> from sklearn import 稍微複雜點的例子:
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
# 讀取自帶的diabete資料集 可以看出,使用還是很簡單的,就是準備好資料集:
regr = linear_model.LinearRegression() #使用線性迴歸
regr.fit(diabetes_X_train, diabetes_y_train) #訓練獲得一個model
regr.predict(diabetes_X_test) # 預測
regr.score(diabetes_X_test, diabetes_y_test) # 獲取模型的score值
OK,就到這,下次繼續!