
Python資料探勘實戰——迴歸
阿新 • • 發佈:2019-01-05
一、迴歸分析(Regression Analysis)
研究自變數與因變數之間關係形式的分析方法,它主要是通過建立 因變數y 與影響它的自變數Xi(i=1,2,3....)之間的迴歸模型,來預測 因變數y 的發展趨勢。
二、迴歸分析的分類
2.1線性迴歸分析:簡單線性迴歸、多重線性迴歸
2.2非線性迴歸分析:邏輯迴歸、神經網路
三、簡單線性迴歸模型
y = a + bx + e(一元一次方程)
1)y——因變數
2)x——自變數
3)a——常數項,截距
4)b——迴歸係數,斜率
5)e——隨機誤差
3.1迴歸分析的步驟
1)根據預測目標,確定自變數和因變數
2)繪製散點圖,確定迴歸模型型別
3)估計模型引數,建立迴歸模型
4)對迴歸模型進行檢驗
5)利用迴歸模型進行預測
3.2案例
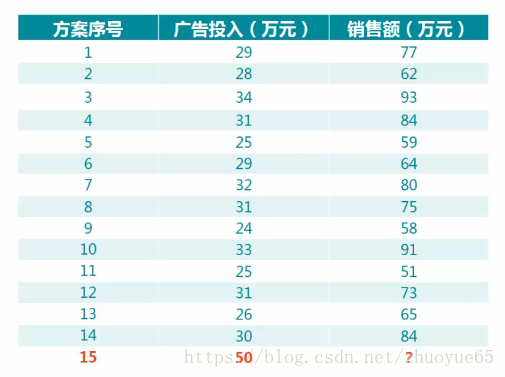
步驟一:
根據預測目標,確定自變數(已知)和因變數(未知)
問題:投入50萬的廣告費用,能夠帶來多少的銷售額
因此,廣告費用是自變數,銷售額是因變數
步驟二:
繪製散點圖,確定迴歸模型型別

步驟三:
估計模型引數,建立迴歸模型

最小2乘法(最小平方法):
實際點和估計點之間的距離的平方和達到最小。
步驟四:

步驟五:
利用迴歸模型進行預測:
根據已有的自變數資料,預測需要的因變數對應的結果。
四、程式碼實戰
data.csv:

import numpy; from pandas import read_csv; from matplotlib import pyplot as plt; from sklearn.linear_model import LinearRegression data = read_csv( 'C:\\Python_DM\\4.1\\data.csv' ) #第二步,畫出散點圖,求x和y的相關係數 plt.scatter(data.廣告投入, data.銷售額) data.corr() #第三步,估計模型引數,建立迴歸模型,sklearn整合的方法,直接呼叫 lrModel = LinearRegression() x = data[['廣告投入']] y = data[['銷售額']] #訓練模型,引數a和引數求解的過程 lrModel.fit(x, y) #第四步、對迴歸模型進行檢驗 lrModel.score(x, y) #第五步、利用迴歸模型進行預測(輸入未知的因變數陣列) lrModel.predict([[50], [40], [30]]) """ #檢視截距 alpha = lrModel.intercept_[0] #檢視引數 beta = lrModel.coef_[0][0] alpha + beta*numpy.array([50, 40, 30]) """