python資料探勘實戰筆記——文字挖掘(1):語料庫構建
阿新 • • 發佈:2018-12-11
什麼是文字挖掘 ?
文字挖掘是抽取有效、新穎、有用、可理解的、散佈在文字檔案中的有價值知識,並且利用這些知識更好地組織資訊的過程。
一、搭建語料庫
語料庫:要進行文字分析的所有文件的集合。
需要用到的模組:os、os.path、codecs、pandas
程式碼如下:
import os import os.path import codecs import pandas filePaths = [] for root, dirs, files in os.walk( r"C:\Users\www12\Desktop\data\2.1\SogouC.mini\Sample" ): #使用os.walk()方法遍歷輸出一個資料夾下的所有檔名
1.os.walk()方法:
os.walk() 方法用於通過在目錄樹中游走輸出在目錄中的檔名,向上或者向下。
語法:
walk()方法語法格式如下:os.walk(top[, topdown=True[, onerror=None[, followlinks=False]]])
引數:
> top – 是你所要遍歷的目錄的地址, 返回的是一個三元組(root,dirs,files)。root 所指的是當前正在遍歷的這個資料夾的本身的地址 dirs 是一個 list ,內容是該資料夾中所有的目錄的名字(不包括子目錄)
files 同樣是 list , 內容是該資料夾中所有的檔名(不包括子目錄) topdown --可選,為 True,則優先遍歷 top
目錄,否則優先遍歷 top 的子目錄(預設為開啟)。如果 topdown 引數為 True,walk 會遍歷top資料夾,與top
資料夾中每一個子目錄。onerror – 可選, 需要一個 callable 物件,當 walk 需要異常時,會呼叫。
followlinks – 可選, 如果為 True,則會遍歷目錄下的快捷方式(linux 下是 symbolic
link)實際所指的目錄(預設關閉)。返回值:
該方法沒有返回值。
#os.path.join()方法拼接檔名返回所有檔案的路徑,並儲存在變數filePaths中
for name in files:
filePaths.append(os.path.join(root, name))
f = codecs.open(filePath, 'r', 'utf-8') fileContent = f.read() f.close() fileContents.append(fileContent) #codecs.open()方法開啟每個檔案,用檔案的read()方法依次讀取其中的文字,將所有文字內容依次儲存到變數fileContenst中,然後close()方法關閉檔案。
#建立資料框corpos,新增filePaths和fileContents兩個變數作為陣列
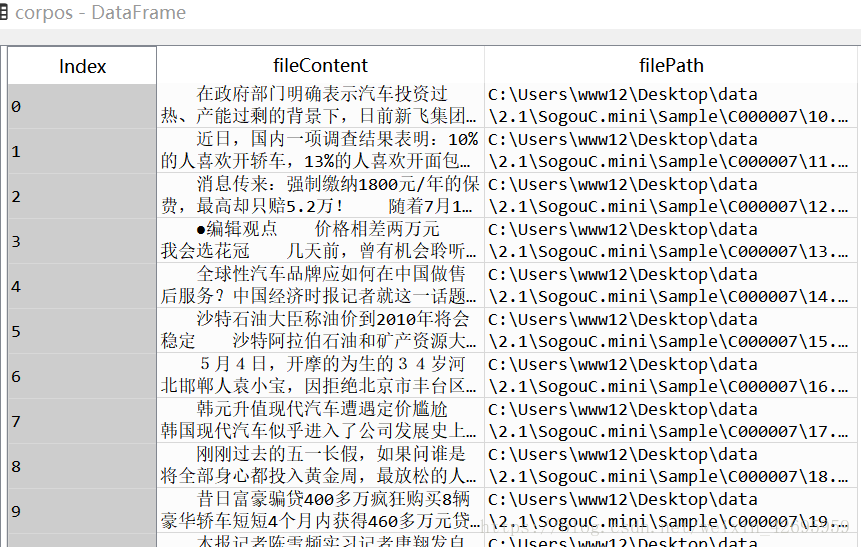
corpos = pandas.DataFrame({
'filePath': filePaths,
'fileContent': fileContents})
這個資料框就是我們要進行文字分析的語料庫了。
如圖: