
《python資料分析和資料探勘》——時間序列分析學習筆記
時間序列分析
給定一個已被觀測了的時間序列,預測該序列的的未來值。
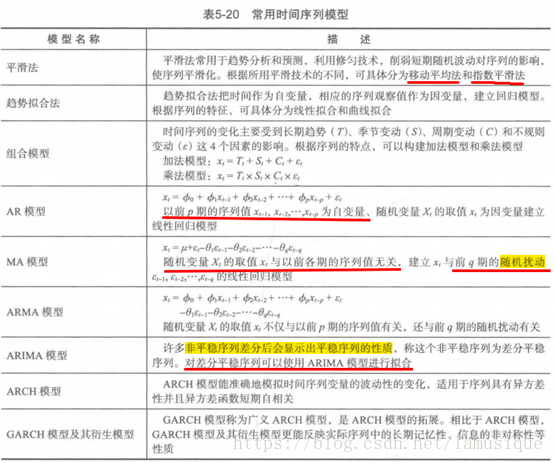
重點介紹AR模型、MA模型、ARMA模型和ARIMA模型
1、時間序列的預處理
拿到一個觀察值序列後,首先要對它的純隨機性和平穩性進行檢驗,稱之為預處理。在此區別純隨機序列、平穩非白噪聲序列、非平穩序列。
純隨機序列(白噪聲序列),序列的各項之間沒有任何相關關係,序列有著完全無序的隨機波動,可以終止對該序列的分析。白噪聲序列是沒有資訊可提取的平穩序列。
平穩非白噪聲序列,他的均值和方差是常數,現在普遍採用ARMA模型進行處理,提取該序列的有用資訊
非平穩序列,由於均值和方差不穩定,處理方法一般將其轉換成平穩序列,以平穩序列的分析方法進行研究。如果一個時間序列經差分運算後具有平穩性,則該序列為差分平穩序列,可用ARIMA模型分析
1) 平穩性檢驗:
貼了一部分定義,只用明白什麼是自相關係數(表示資料和資料間的關係),什麼樣是平穩性(訊號的均值或說期望是常數)。
a)平穩時間序列的定義

b) 平穩性的檢驗
兩種檢驗方法。一種是根據時序圖和自相關圖的特徵作出判斷的圖檢驗,操作簡單、應用廣泛,但帶有主觀性;另一種是構造檢驗統計量進行檢驗,目前常用的方法是單位根檢驗
I 時序圖檢驗。根據平穩時間序列的均值和方差都為常數的性質,平穩序列的時序圖顯示該序列值式中在一個常數附近波動,並且波動的範圍有界。倘若有明顯的趨勢性或週期性,那他通常不是平穩序列。
II 自相關圖檢驗。平穩序列具有短期相關,說明對平穩序列而言通常近期的序列值對
現有值影響較大,間隔越遠的過去值對現有值影響較小。隨著延遲期數k的增加,平穩序列的自相關係數ρk(延遲k期)會比較快的衰減趨向於0,在0處波動,而非平穩序列則衰減速度較慢,這就是利用自相關圖進行平穩性檢驗的標準。
III 單位根檢驗。單位根檢驗是指檢驗序列中是否存在單位根,如果存在單位根就是非平穩時間序列了。涉及到“單位根檢驗p值”。
2) 純隨機性檢驗:白噪聲檢測,構造驗證統計量來檢驗序列的純隨機性,常用的驗證統計量有Q統計量、LB統計量,一般很少出現純隨機狀態(即序列值之間沒有任何關係)。涉及統計量 “白噪聲檢驗p值”
2、平穩時間序列分析
對於擬合平穩序列最常用的模型就是ARMA模型,又可以AR模型、MA模型和ARMA三大類。
1) AR模型

在t時刻的值由前p期
a.均值——求期望
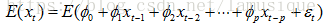
已知

b.方差——有界等於常數
c.自相關係數(ACF)

平穩AR(p)模型的自相關係數呈指數的速度衰減,始終有非零取值,不會再k大於某個常數之後就恆等於0,具有拖尾性。
d.偏自相關係數(PACF)
單純地表明測度對的影響,即平穩AR(p)模型的偏自相關係數具有p階截尾性。
2) MA模型

在t時刻的隨機變數


3) ARMA模型
自迴歸移動平均模型,簡記為ARMA(p,q)

即在t時刻的隨機變數的取值是由前p期

4) 平穩時間序列建模
某個時間序列經過預處理,被判定為平穩非白噪聲序列,就可以利用ARMA模型進行建模。計算出平穩非白噪聲序列的自相關係數和偏自相關係數,再由AR(p)模型、MA(p)、ARMA(p)的自相關係數和偏自相關係數的性質,選擇合適的模型。
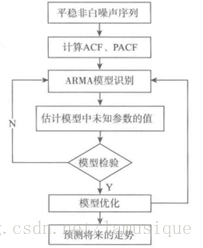
3. 非平穩時間序列分析
絕大多數序列都是非平穩序列,更多采用隨機時序分析,具體建立的模型由ARIMA模型、殘差自迴歸模型、季節模型等。重點採用ARIMA模型對非平穩時間序列進行分析建模。
1) 差分運算
p階差分:相距一期的兩個序列值之間的減法運算稱為1階差分。
k步差分:相距k期的兩個序列值之間的減法運算稱為k步差分
2) ARIMA模型
本質是差分運算和ARMA模型結合。

根據這個步驟可總結如下:
I 平穩性檢測。畫個序列變化圖,看他變化是不是穩定,均值要保持穩定;然後再看他的自相關圖,如果自相關係數長期不等於0,說明序列具有很強的長期相關性,序列要有很強的短期相關性;但是我推薦使用平方根檢驗方法,判斷(平方根檢驗統計量對應的)p值是否大於0.05,此處可判斷序列是否為非平穩序列。(非平穩序列一定不是白噪聲序列)
II 如果不是非平穩序列,那做個一階差分試試,再根據第I步進行平穩性驗證,不滿足就再差分一次試試,直至得到穩定序列
III 針對第II步得到的平穩序列,我們做白噪聲檢驗,(白噪聲檢驗統計量對應的)p值遠小於0.05,說明得到但是平穩非白噪聲序列。
IV 針對平穩非白噪聲序列,仿照ARMA模型進行分析。確定p、q
1. 人的主觀識別,根據截尾、拖尾確定p、q,我可做不到這點
2. 相對最優模型識別。計算ARMA(p,q),當p和q均小於等於3的所有組合的BIC資訊量,取其中BIC資訊量達到最小的模型階數。BIC矩陣中最小值的索引(a,b),p=a,q=b,如最小BIC值的索引為(0,1),表示p=0,q=1.即p,q定階完成。
綜上n階差分後確定的模型為ARIMA(p,n,q),此處為ARIMA(0,1,1)。
需要指出模型不一定是唯一的,ARIMA(1,1,0)和ARIMA(1,1,1)也可以通過檢驗。
V 針對建立好的ARIMA模型檢驗殘差(保證為白噪聲序列,認為是無偏的),再估計待求係數引數,最後進行模型預測。

利用模型向前預測的時期越長,預測誤差將會越大,這是時間序列分析的典型特點。

4. Python主要時序演算法函式
主要呼叫庫Statsmodel,演算法主要是ARIMA模型,在使用該模型進行建模時,需要進行一系列判斷操作,主要包含平穩性檢驗、白噪聲檢測、是否差分、AIC和BIC指標值、模型定階,最終做預測。相關函式如下
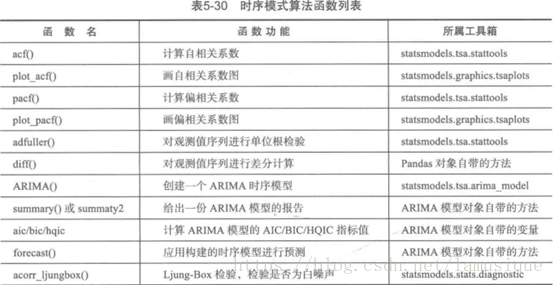
需要指出
summary()和summary2()函式生成已有模型的報告, 使用格式:
arima.summary(),其中arima為已經建立好的ARIMA模型,返回一份格式化的模型 報告,包含模型的係數、表胡宗南誤差、p值、AIC和BIC等詳細指標。
Adffuller()是對觀測值序列進行單位根檢驗(ADF test),使用格式:
h=adffuller(Series,maxlag=None,regression=’c’,autolag=’AIC’,store=False,regresults=False)輸入引數Series為一維觀測值序列、返回值依次為adf、pvalue、usedlag、nobs、criticalvalues、icbest、regresults、resstore。
其他函式的具體用法可百度。