
PointNet++論文學習筆記
PointNet++論文學習筆記
本文記錄了博主在學習論文《PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space》過程中認為重要的內容。更新於2018.11.05。
文章目錄
綜述
之前博主學習過這篇論文的前序結構PointNet,並記錄了筆記。與PointNet相比,PointNet無法獲取每個點所在的度量空間所產生的區域性結構,從而限制了其對於整齊排布的圖形的識別能力以及對複雜場景的範化性。
論文作者指出,PointNet++的設計需要解決兩個問題:如何生成點雲的分割槽,以及如何通過一個區域性特徵學習演算法抽象點雲或區域性特徵。然而,這兩個問題其實是相關的,因為分割槽的設計必須保證每個分割槽具有相似的結構,從而使得區域性特徵學習演算法的引數可以在分割槽之間共享。
這裡選擇的區域性特徵學習演算法就是PointNet,而分割槽則是選取了在最底層的歐氏空間內由質心(centroid)和尺寸(scale)描述的球形。為了保證整個點雲被均勻覆蓋,質心的選擇應用了farthest point sampling(FPS)演算法,其原理是先隨機選一個點,然後選擇離這個點距離最遠的點(度量空間下距離度量最大的點)加入起點,如此迭代,直到選出需要的個數為止。相比較應用固定步長的卷積神經網路,這種適應性的結構既考慮了輸入資料,也考慮了度量,因此論文聲稱這種方法更有效和高效。
這麼做的難點在於如何確定球的尺寸,類似於如何確定CNN的卷積核尺寸。但是與CNN中不同的是,儘管有論文證明較小的卷積核尺寸可以提高CNN的表現(參考文獻25),但是,論文的作者發現對於點雲資料,小尺寸可能使得沒有足夠的點以供學習物體的模式。
論文的主要貢獻在於,利用了多尺度鄰域以同時實現魯棒性和細節獲取。
問題描述
假設 是一個度量繼承自歐氏空間 的離散度量空間,其中 是一個點集, 是距離度量。且 在整個歐氏空間內的密度可能不同。
我們想要學習的是一個函式 ,其以 (和每個點的特徵)作為輸入,隨後輸出根據 生成的語義興趣資訊(information of semantic interest)。在實際應用中,這個 可能是給 標註類別的分類函式,也可能是給 的每個成員逐點標註的分割函式。
方法
結構介紹
論文首先回顧了PointNet,這裡就不寫了,感興趣的看這裡。相比較PointNet,PointNet++增加了獲取不同尺度下的目標的能力,即新增了逐尺度抽象的結構,代替了原來的直接抽象整個點雲的做法。下圖是這一組集合抽象層(set abstraction layers)的結構:
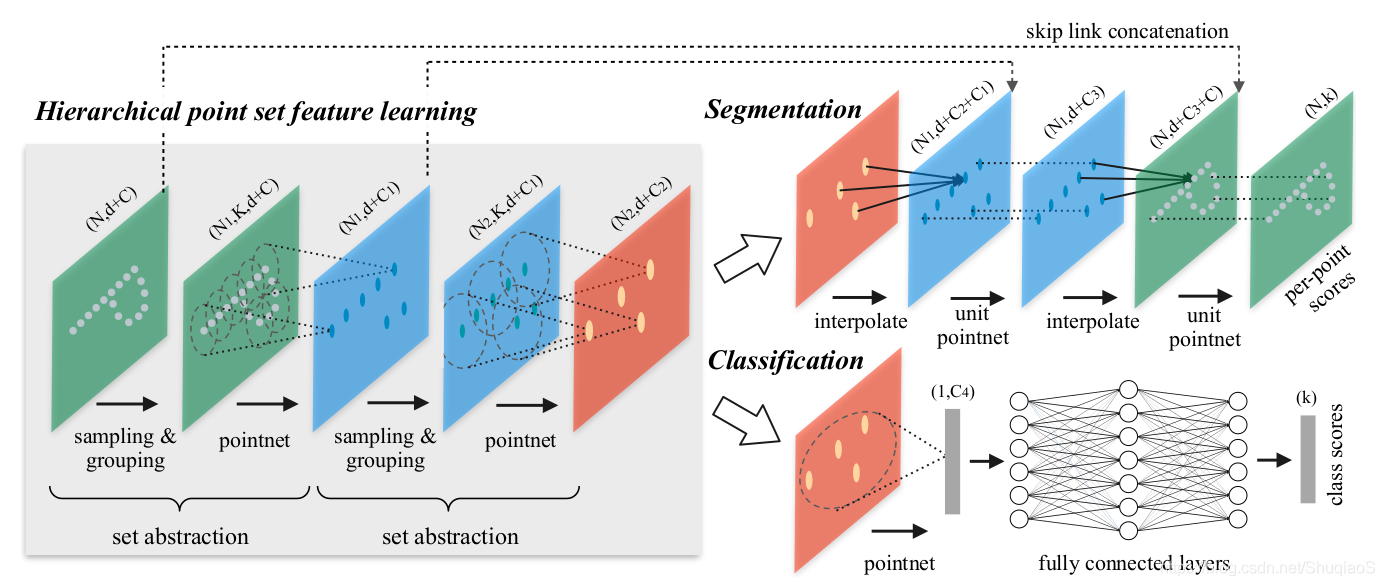
這個結構主要分為三個部分:
- 取樣層(Sampling Layer):用於從輸入點雲中選取一部分點,這些點也就是區域性區域的質心;
- 組合層(Grouping Layer):用於根據鄰域規則,選取與質心“相鄰”的點;
- PointNet層(PointNet Layer):用mini-PointNet將區域性區域的圖形編碼成特徵向量。
輸入:維度為
的矩陣,含義是具有
維座標資訊和
維特徵的
個點。
輸出:維度為
的矩陣,含義是具有
維座標資訊和總結區域性資訊的新
維特徵的二次抽樣得到的
個點。
下面具體介紹一下這幾個層:
取樣層: 給定輸入點集 ,論文中迭代應用最遠點取樣(Farthest Point Sampling, FSP)選取出一個子集 ,其中 是在度量空間內距離集合 最遠的點。
組合層: 這一層的輸入是一個尺寸為 的點集和一組尺寸為 的質心座標。輸出為尺寸是 的點集的組合,其中每個組都對應一個區域性區域且 是質心點鄰域的點數。需要注意的是,每組的 都是不同的,需要依靠隨後的PointNet將它們轉變成長度一致的區域性特徵向量。
相比較kNN而言,ball query方法使得鄰域的區域尺寸固定,從而使提取的特徵更能滿足範化性要求。
PointNet層: 這一層的輸入是 個點區域性區域,資料尺寸為 。輸出為每個區域的質心和描述質心鄰域的區域性特徵,尺寸 。區域性區域中的點的座標先根據質心的座標 調整為 ,其中 , 。
在非均勻取樣密度下的魯棒特徵學習
非均勻取樣密度:non-uniform sampling density
前文提到過點雲資料在不同區域很有可能擁有不同的點密度,這就導致在稠密情況下訓練出來的網路不一定適應稀疏條件下的估計,而滿足稀疏條件估計的網路又很難範化至稠密區域。為了解決這個問題,論文提出了下面兩個密度適應網路結構:
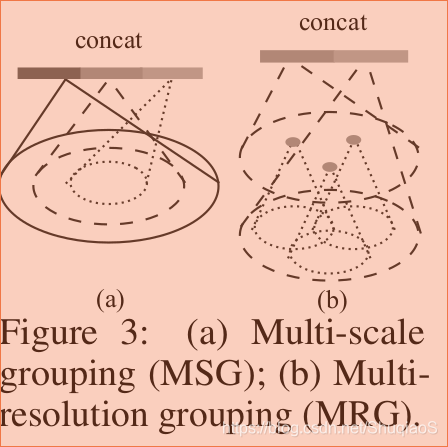
訓練時,為了保證網路能夠適應不同的點雲密度,論文作者採用了隨機選取的dropout概率 ,其範圍在 之間,其中 。實際操作中,為了避免產生空集,作者取 。
這兩個結構中,MSG的計算量非常大,因此作者提出了其替代結構MRG。
分割問題下的點特徵傳遞
經過了前面的做法後,點雲內包含的點的數量相比較原始輸入是減小了的。因此,對於像分割這一類問題,就需要將點的個數恢復成原始水平。論文中採取了inverse distance weighted average的方法實現差值,公式如下: