
機器學習筆試題精選(七)
紅色石頭的個人網站:redstonewill.com
機器學習是一門理論性和實戰性都比較強的技術學科。在應聘機器學習相關工作崗位時,我們常常會遇到各種各樣的機器學習問題和知識點。為了幫助大家對這些知識點進行梳理和理解,以便能夠更好地應對機器學習筆試包括面試。紅色石頭準備在公眾號連載一些機器學習筆試題系列文章,希望能夠對大家有所幫助!
接下來我們繼續來看機器學習筆試題精選(七)的內容。
Q1. 下面哪個對應的是正確的 KNN 決策邊界?
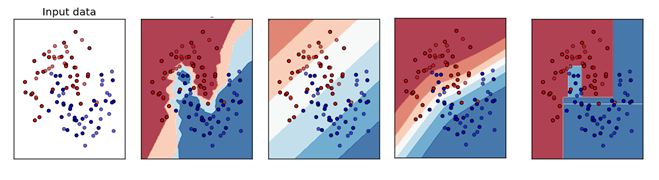
A. A
B. B
C. C
D. D
答案:A
解析:本題考查的是 KNN 的相關知識點。
KNN 分類演算法是一個比較成熟也是最簡單的機器學習(Machine Learning)演算法之一。該方法的思路是:如果一個樣本在特徵空間中與K個例項最為相似(即特徵空間中最鄰近),那麼這 K 個例項中大多數屬於哪個類別,則該樣本也屬於這個類別。其中,計算樣本與其他例項的相似性一般採用距離衡量法。離得越近越相似,離得越遠越不相似。因此,決策邊界可能不是線性的。
Q2. 如果一個經過訓練的機器學習模型在測試集上達到 100% 的準確率,這是否意味著該模型將在另外一個新的測試集上也能得到 100% 的準確率呢?
A. 是的,因為這個模型泛化能力已經很好了,可以應用於任何資料
B. 不行,因為還有一些模型不確定的東西,例如噪聲
答案:B
解析:本題考查的是機器學習泛化能力與噪聲。
現實世界的資料並不總是無噪聲的,所以在這種情況下,我們不會得到 100% 的準確度。
Q3. 下面是交叉驗證的幾種方法:
1. Bootstrap
2. 留一法交叉驗證
3. 5 折交叉驗證
4. 重複使用兩次 5 折交叉驗證
請對上面四種方法的執行時間進行排序,樣本數量為 1000。
A. 1 > 2 > 3 > 4
B. 2 > 3 > 4 > 1
C. 4 > 1 > 2 >3
D. 2 > 4 > 3 > 1
答案
解析:本題考查的是 k 折交叉驗證和 Bootstrap 的基本概念。
Bootstrap 是統計學的一個工具,思想就是從已有資料集 D 中模擬出其他類似的樣本 Dt。Bootstrap 的做法是,假設有 N 筆資料,先從中選出一個樣本,再放回去,再選擇一個樣本,再放回去,共重複 N 次。這樣我們就得到了一個新的 N 筆資料,這個新的 Dt 中可能包含原 D 裡的重複樣本點,也可能沒有原 D 裡的某些樣本,Dt 與 D 類似但又不完全相同。值得一提的是,抽取-放回的操作不一定非要是 N,次數可以任意設定。例如原始樣本有 10000 個,我們可以抽取-放回 3000 次,得到包含 3000 個樣本的 Dt 也是完全可以的。因此,使用 bootstrap 只相當於有 1 個模型需要訓練,所需時間最少。
留一法(Leave-One-Out)交叉驗證每次選取 N-1 個樣本作為訓練集,另外一個樣本作為驗證集,重複 N 次。因此,留一法相當於有 N 個模型需要訓練,所需的時間最長。
5 折交叉驗證把 N 個樣本分成 5 份,其中 4 份作為訓練集,另外 1 份作為驗證集,重複 5 次。因此,5 折交叉驗證相當於有 5 個模型需要訓練。
2 次重複的 5 折交叉驗證相當於有 10 個模型需要訓練。
Q4. 變數選擇是用來選擇最好的判別器子集, 如果要考慮模型效率,我們應該做哪些變數選擇的考慮?(多選)
A. 多個變數是否有相同的功能
B. 模型是否具有解釋性
C. 特徵是否攜帶有效資訊
D. 交叉驗證
答案:ACD
解析:本題考查的是模型特徵選擇。
如果多個變數試圖做相同的工作,那麼可能存在多重共線性,影響模型效能,需要考慮。如果特徵是攜帶有效資訊的,總是會增加模型的有效資訊。我們需要應用交叉驗證來檢查模型的通用性。關於模型效能,我們不需要看到模型的可解釋性。
Q6. 如果線上性迴歸模型中額外增加一個變數特徵之後,下列說法正確的是?
A. R-Squared 和 Adjusted R-Squared 都會增大
B. R-Squared 保持不變 Adjusted R-Squared 增加
C. R-Squared 和 Adjusted R-Squared 都會減小
D. 以上說法都不對
答案:D
解析:本題考查的是線性迴歸模型的評估準則 R-Squared 和 Adjusted R-Squared。
線性迴歸問題中,R-Squared 是用來衡量回歸方程與真實樣本輸出之間的相似程度。其表示式如下所示:
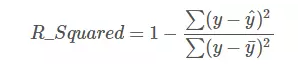
上式中,分子部分表示真實值與預測值的平方差之和,類似於均方差 MSE;分母部分表示真實值與均值的平方差之和,類似於方差 Var。根據 R-Squared 的取值,來判斷模型的好壞:如果結果是 0,說明模型擬合效果很差;如果結果是 1,說明模型無錯誤。一般來說,R-Squared 越大,表示模型擬合效果越好。R-Squared 反映的是大概有多準,因為,隨著樣本數量的增加,R-Square必然增加,無法真正定量說明準確程度,只能大概定量。
單獨看 R-Squared,並不能推斷出增加的特徵是否有意義。通常來說,增加一個特徵,R-Squared 可能變大也可能保持不變,兩者不一定呈正相關。
如果使用校正決定係數(Adjusted R-Square):
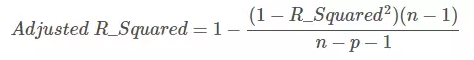
其中,n 是樣本數量,p 是特徵數量。Adjusted R-Square 抵消樣本數量對 R-Square的影響,做到了真正的 0~1,越大越好。若增加的特徵有效,則 Adjusted R-Square 就會增大,反之則減小。
Q7. 如下圖所示,對同一資料集進行訓練,得到 3 個模型。對於這 3 個模型的評估,下列說法正確的是?(多選)
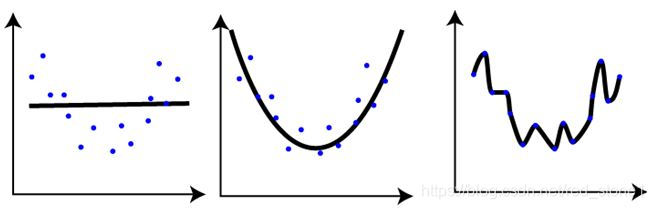
A. 第一個模型的訓練誤差最大
B. 第三個模型效能最好,因為其訓練誤差最小
C. 第二個模型最穩健,其在測試集上表現應該最好
D. 第三個模型過擬合
答案:ACD
解析:本題考查的是機器學習模型欠擬合、過擬合概念。
很簡單,第一個模型過於簡單,發生欠擬合,訓練誤差很大,在訓練樣本和測試樣本上表現都不佳。第二個模型較好,泛化能力強,模型較為健壯,在訓練樣本和測試樣本上表現都不錯。第三個模型過於複雜,發生過擬合,訓練樣本誤差雖然很小,但是在測試樣本集上一般表現很差,泛化能力很差。
模型選擇應該避免欠擬合和過擬合,對於模型複雜的情況可以選擇使用正則化方法。
Q8. 如果使用線性迴歸模型,下列說法正確的是?
A. 檢查異常值是很重要的,因為線性迴歸對離群效應很敏感
B. 線性迴歸分析要求所有變數特徵都必須具有正態分佈
C. 線性迴歸假設資料中基本沒有多重共線性
D. 以上說法都不對
答案:A
解析:本題考查的是線性迴歸的一些基本原理。
異常值是資料中的一個非常有影響的點,它可以改變最終迴歸線的斜率。因此,去除或處理異常值在迴歸分析中一直是很重要的。
瞭解變數特徵的分佈是有用的。類似於正態分佈的變數特徵對提升模型效能很有幫助。例如,資料預處理的時候經常做的一件事就是將資料特徵歸一化到(0,1)分佈。但這也不是必須的。
當模型包含相互關聯的多個特徵時,會發生多重共線性。因此,線性迴歸中變數特徵應該儘量減少冗餘性。C 選擇絕對化了。
Q9. 建立線性模型時,我們看變數之間的相關性。在尋找相關矩陣中的相關係數時,如果發現 3 對變數(Var1 和 Var2、Var2 和 Var3、Var3 和 Var1)之間的相關性分別為 -0.98、0.45 和 1.23。我們能從中推斷出什麼呢?(多選)
A. Var1 和 Var2 具有很高的相關性
B. Var1 和 Var2 存在多重共線性,模型可以去掉其中一個特徵
C. Var3 和 Var1 相關係數為 1.23 是不可能的
答案:ABC
解析:本題考查的是相關係數的基本概念。
Var1 和 Var2 之間的相關性非常高,並且是負的,因此我們可以將其視為多重共線性的情況。此外,當資料中存在多重線性特徵時,我們可以去掉一個。一般來說,如果相關大於 0.7 或小於 -0.7,那麼我們認為特徵之間有很高的相關性。第三個選項是不言自明的,相關係數介於 [-1,1] 之間,1.23 明顯有誤。
Q10. 如果自變數 X 和因變數 Y 之間存在高度的非線性和複雜關係,那麼樹模型很可能優於經典迴歸方法。這個說法正確嗎?
A. 正確
B. 錯誤
答案:A
解析:本題考查的是迴歸模型的選擇。
當資料是非線性的時,經典迴歸模型泛化能力不強,而基於樹的模型通常表現更好。
更多原創內容請點選文末的閱讀原文檢視!
參考文獻:
https://www.analyticsvidhya.com/blog/2016/11/solution-for-skilltest-machine-learning-revealed/
