
機器學習筆試題精選(一)
機器學習是一門理論性和實戰性都比較強的技術學科。在應聘機器學習相關工作崗位時,我們常常會遇到各種各樣的機器學習問題和知識點。為了幫助大家對這些知識點進行梳理和理解,以便能夠更好地應對機器學習筆試包括面試。紅色石頭準備在公眾號連載一些機器學習筆試題系列文章,希望能夠對大家有所幫助!
Q1. 在迴歸模型中,下列哪一項在權衡欠擬合(under-fitting)和過擬合(over-fitting)中影響最大?
A. 多項式階數
B. 更新權重 w 時,使用的是矩陣求逆還是梯度下降
C. 使用常數項
答案:A
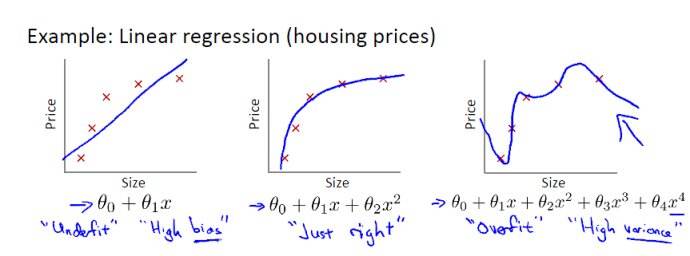
解析:選擇合適的多項式階數非常重要。如果階數過大,模型就會更加複雜,容易發生過擬合;如果階數較小,模型就會過於簡單,容易發生欠擬合。如果有對過擬合和欠擬合概念不清楚的,見下圖所示:
Q2. 假設你有以下資料:輸入和輸出都只有一個變數。使用線性迴歸模型(y=wx+b)來擬合數據。那麼使用留一法(Leave-One Out)交叉驗證得到的均方誤差是多少?
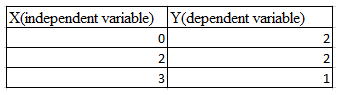
A. 10/27
B. 39/27
C. 49/27
D. 55/27
答案:C
解析:留一法,簡單來說就是假設有 N 個樣本,將每一個樣本作為測試樣本,其它 N-1 個樣本作為訓練樣本。這樣得到 N 個分類器,N 個測試結果。用這 N個結果的平均值來衡量模型的效能。
對於該題,我們先畫出 3 個樣本點的座標:
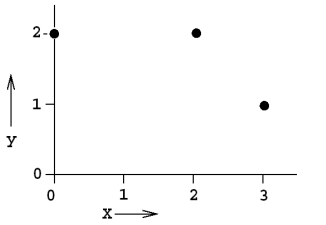
使用兩個點進行線性擬合,分成三種情況,如下圖所示:
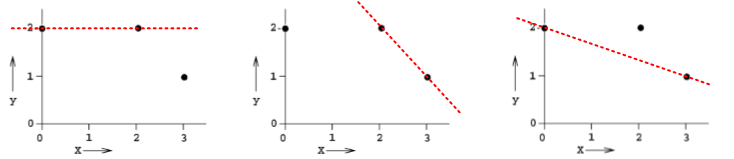
第一種情況下,迴歸模型是 y = 2,誤差 E1 = 1。
第二種情況下,迴歸模型是 y = -x + 4,誤差 E2 = 2。
第三種情況下,迴歸模型是 y = -1/3x + 2,誤差 E3 = 2/3。
則總的均方誤差為:
Q3. 下列關於極大似然估計(Maximum Likelihood Estimate,MLE),說法正確的是(多選)?
A. MLE 可能並不存在
B. MLE 總是存在
C. 如果 MLE 存在,那麼它的解可能不是唯一的
D. 如果 MLE 存在,那麼它的解一定是唯一的
答案:AC
解析:如果極大似然函式 L(θ) 在極大值處不連續,一階導數不存在,則 MLE 不存在,如下圖所示:
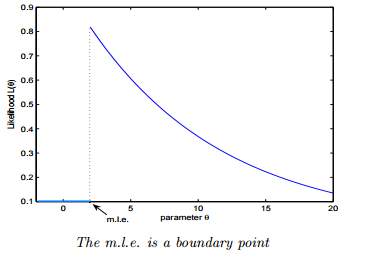 另一種情況是 MLE 並不唯一,極大值對應兩個 θ。如下圖所示: 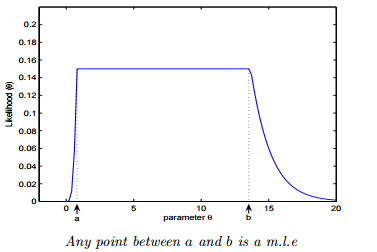 **Q4. 如果我們說“線性迴歸”模型完美地擬合了訓練樣本(訓練樣本誤差為零),則下面哪個說法是正確的?** A. 測試樣本誤差始終為零 B. 測試樣本誤差不可能為零 C. 以上答案都不對 **答案**:C **解析**:根據訓練樣本誤差為零,無法推斷測試樣本誤差是否為零。值得一提是,如果測試樣本樣本很大,則很可能發生過擬合,模型不具備很好的泛化能力! **Q5. 在一個線性迴歸問題中,我們使用 R 平方(R-Squared)來判斷擬合度。此時,如果增加一個特徵,模型不變,則下面說法正確的是?** A. 如果 R-Squared 增加,則這個特徵有意義 B. 如果R-Squared 減小,則這個特徵沒有意義 C. 僅看 R-Squared 單一變數,無法確定這個特徵是否有意義。 D. 以上說法都不對 **答案**:C **解析**:線性迴歸問題中,R-Squared 是用來衡量回歸方程與真實樣本輸出之間的相似程度。其表示式如下所示: 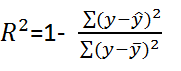 上式中,分子部分表示真實值與預測值的平方差之和,類似於均方差 MSE;分母部分表示真實值與均值的平方差之和,類似於方差 Var。根據 R-Squared 的取值,來判斷模型的好壞:如果結果是 0,說明模型擬合效果很差;如果結果是 1,說明模型無錯誤。一般來說,R-Squared 越大,表示模型擬合效果越好。R-Squared 反映的是大概有多準,因為,隨著樣本數量的增加,R-Square必然增加,無法真正定量說明準確程度,只能大概定量。 對於本題來說,單獨看 R-Squared,並不能推斷出增加的特徵是否有意義。通常來說,增加一個特徵,R-Squared 可能變大也可能保持不變,兩者不一定呈正相關。 如果使用校正決定係數(Adjusted R-Square): 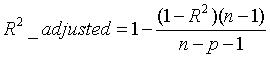 其中,n 是樣本數量,p 是特徵數量。Adjusted R-Square 抵消樣本數量對 R-Square的影響,做到了真正的 0~1,越大越好。 **Q6. 下列關於線性迴歸分析中的殘差(Residuals)說法正確的是?** A. 殘差均值總是為零 B. 殘差均值總是小於零 C. 殘差均值總是大於零 D. 以上說法都不對 **答案**:A **解析**:線性迴歸分析中,目標是殘差最小化。殘差平方和是關於引數的函式,為了求殘差極小值,令殘差關於引數的偏導數為零,會得到殘差和為零,即殘差均值為零。 **Q7. 下列關於異方差(Heteroskedasticity)說法正確的是?** A. 線性迴歸具有不同的誤差項 B. 線性迴歸具有相同的誤差項 C. 線性迴歸誤差項為零 D. 以上說法都不對 **答案**:A **解析**:異方差性是相對於同方差(Homoskedasticity)而言的。所謂同方差,是為了保證迴歸引數估計量具有良好的統計性質,經典線性迴歸模型的一個重要假定:總體迴歸函式中的隨機誤差項滿足同方差性,即它們都有相同的方差。如果這一假定不滿足,即:隨機誤差項具有不同的方差,則稱線性迴歸模型存在異方差性。 通常來說,奇異值的出現會導致異方差性增大。 **Q8. 下列哪一項能反映出 X 和 Y 之間的強相關性?** A. 相關係數為 0.9 B. 對於無效假設 β=0 的 p 值為 0.0001 C. 對於無效假設 β=0 的 t 值為 30 D. 以上說法都不對 **答案**:A **解析**:相關係數的概念我們很熟悉,它反映了不同變數之間線性相關程度,一般用 r 表示。其中,Cov(X,Y) 為 X 與 Y 的協方差,Var[X] 為 X 的方差,Var[Y] 為 Y 的方差。r 取值範圍在 [-1,1] 之間,r 越大表示相關程度越高。A 選項中,r=0.9 表示 X 和 Y 之間有較強的相關性。
而 p 和 t 的數值大小沒有統計意義,只是將其與某一個閾值進行比對,以得到二選一的結論。例如,有兩個假設:
無效假設(null hypothesis)H0:兩參量間不存在“線性”相關。
備擇假設(alternative hypothesis)H1:兩參量間存在“線性”相關。
如果閾值是 0.05,計算出的 p 值很小,比如為 0.001,則可以說“有非常顯著的證據拒絕 H0 假設,相信 H1 假設。即兩參量間存在“線性”相關。p 值只用於二值化判斷,因此不能說 p=0.06 一定比 p=0.07 更好。
Q9. 下列哪些假設是我們推導線性迴歸引數時遵循的(多選)?
A. X 與 Y 有線性關係(多項式關係)
B. 模型誤差在統計學上是獨立的
C. 誤差一般服從 0 均值和固定標準差的正態分佈
D. X 是非隨機且測量沒有誤差的
答案:ABCD
解析:在進行線性迴歸推導和分析時,我們已經預設上述四個條件是成立的。
Q10. 為了觀察測試 Y 與 X 之間的線性關係,X 是連續變數,使用下列哪種圖形比較適合?
A. 散點圖
B. 柱形圖
C. 直方圖
D. 以上都不對
答案:A
解析:散點圖反映了兩個變數之間的相互關係,在測試 Y 與 X 之間的線性關係時,使用散點圖最為直觀。
Q11. 一般來說,下列哪種方法常用來預測連續獨立變數?
A. 線性迴歸
B. 邏輯回顧
C. 線性迴歸和邏輯迴歸都行
D. 以上說法都不對
答案:A
解析:線性迴歸一般用於實數預測,邏輯迴歸一般用於分類問題。
Q12. 個人健康和年齡的相關係數是 -1.09。根據這個你可以告訴醫生哪個結論?
A. 年齡是健康程度很好的預測器
B. 年齡是健康程度很糟的預測器
C. 以上說法都不對
答案:C
解析:因為相關係數的範圍是 [-1,1] 之間,所以,-1.09 不可能存在。
Q13. 下列哪一種偏移,是我們在最小二乘直線擬合的情況下使用的?圖中橫座標是輸入 X,縱座標是輸出 Y。
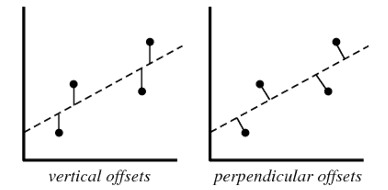
A. 垂直偏移(vertical offsets)
B. 垂向偏移(perpendicular offsets)
C. 兩種偏移都可以
D. 以上說法都不對
答案:A
解析:線性迴歸模型計算損失函式,例如均方差損失函式時,使用的都是 vertical offsets。perpendicular offsets 一般用於主成分分析(PCA)中。
Q14. 假如我們利用 Y 是 X 的 3 階多項式產生一些資料(3 階多項式能很好地擬合數據)。那麼,下列說法正確的是(多選)?
A. 簡單的線性迴歸容易造成高偏差(bias)、低方差(variance)
B. 簡單的線性迴歸容易造成低偏差(bias)、高方差(variance)
C. 3 階多項式擬合會造成低偏差(bias)、高方差(variance)
D. 3 階多項式擬合具備低偏差(bias)、低方差(variance)
答案:AD
解析:偏差和方差是兩個相對的概念,就像欠擬合和過擬合一樣。如果模型過於簡單,通常會造成欠擬合,伴隨著高偏差、低方差;如果模型過於複雜,通常會造成過擬合,伴隨著低偏差、高方差。
用一張圖來形象地表示偏差與方差的關係:
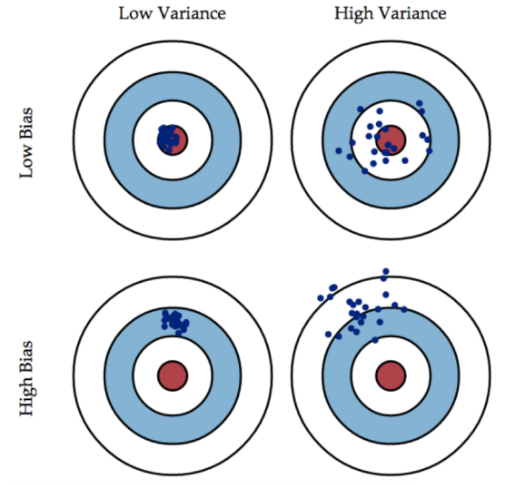
偏差(bias)可以看成模型預測與真實樣本的差距,想要得到 low bias,就得複雜化模型,但是容易造成過擬合。方差(variance)可以看成模型在測試集上的表現,想要得到 low variance,就得簡化模型,但是容易造成欠擬合。實際應用中,偏差和方差是需要權衡的。若模型在訓練樣本和測試集上都表現的不錯,偏差和方差都會比較小,這也是模型比較理想的情況。
Q15. 假如你在訓練一個線性迴歸模型,有下面兩句話:
1. 如果資料量較少,容易發生過擬合。
2. 如果假設空間較小,容易發生過擬合。
關於這兩句話,下列說法正確的是?
A. 1 和 2 都錯誤
B. 1 正確,2 錯誤
C. 1 錯誤,2 正確
D. 1 和 2 都正確
答案:B
解析:先來看第 1 句話,如果資料量較少,容易在假設空間找到一個模型對訓練樣本的擬合度很好,容易造成過擬合,該模型不具備良好的泛化能力。
再來看第 2 句話,如果假設空間較小,包含的可能的模型就比較少,也就不太可能找到一個模型能夠對樣本擬合得很好,容易造成高偏差、低方差,即欠擬合。
參考文獻:

相關推薦
機器學習筆試題精選(一)
機器學習是一門理論性和實戰性都比較強的技術學科。在應聘機器學習相關工作崗位時,我們常常會遇到各種各樣的機器學習問題和知識點。為了幫助大家對這些知識點進行梳理和理解,以便能夠更好地應對機器學習筆試包括面試。紅色石頭準備在公眾號連載一些機器學習筆試題系列文章,希
機器學習筆試題精選(三)
往期回顧: 機器學習是一門理論性和實戰性都比較強的技術學科。在應聘機器學習相關工作崗位時,我們常常會遇到各種各樣的機器學習問題和知識點。為了幫助大家對這些知識點進行梳理和理解,以便能夠更好地應對機器學習筆試包括面試。紅色石頭準備在公眾號連載一些機器
機器學習筆試題精選(七)
紅色石頭的個人網站:redstonewill.com 機器學習是一門理論性和實戰性都比較強的技術學科。在應聘機器學習相關工作崗位時,我們常常會遇到各種各樣的機器學習問題和知識點。為了幫助大家對這些知識點進行梳理和理解,以便能夠更好地應對機器學習筆試包括面試。紅色石頭準備
機器學習筆試題精選(五)
機器學習是一門理論性和實戰性都比較強的技術學科。在應聘機器學習相關工作崗位時,我們常常會遇到各種各樣的機器學習問題和知識點。為了幫助大家對這些知識點進行梳理和理解,以便能夠更好地應對機器學習筆試包括面試。紅色石頭準備在公眾號連載一些機器學習筆試題系列文章,希
知乎專欄 —機器學習筆試題精選試題總結(一)
機器學習筆試題精選試題一 1. 線上性迴歸問題中,利用R平方(R-Squared)來判斷擬合度:數值越大說明模型擬合的越好。數值在[0 1]之間。 隨著樣本數量的增加,R平方的數值必然也會增加,無法定量地說明新增的特徵有無意義。對於新增的特徵,R平方的值可能變大也可能
知乎專欄 —機器學習筆試題精選試題總結(二)
機器學習筆試題精選試題六 1. 對於大量的訓練資料以及特徵的維數比較大時,怎麼進行訓練模型呢?可以採用的方法有: 1) 對訓練集隨機取樣,在隨機取樣的資料上建立模型; 2)嘗試使用線上機器學習演算法; 3)使用 PCA 演算法減少特徵維度。 對於2)而言,離線學
.NET筆試題集(一)
table 分開 裏的 積累 run control scalar forever 類定義 題目來源於傳智播客和各大互聯網,復習、重新整理貼出來。 1、簡述 private、 protected、 public、 internal、protected internal
ng機器學習視頻筆記(一)——線性回歸、代價函數、梯度下降基礎
info 而且 wid esc 二維 radi pan 圖形 clas ng機器學習視頻筆記(一) ——線性回歸、代價函數、梯度下降基礎 (轉載請附上本文鏈接——linhxx) 一、線性回歸 線性回歸是監督學習中的重要算法,其主要目的在於用一個函數表
機器學習之數學基礎(一)-微積分,概率論和矩陣
系列 學習 python 機器學習 自然語言處理 圖片 clas 數學基礎 記錄 學習python快一年了,因為之前學習python全棧時,沒有記錄學習筆記想回顧發現沒有好的記錄,目前主攻python自然語言處理方面,把每天的學習記錄記錄下來,以供以後查看,和交流分享。~~
貝葉斯在機器學習中的應用(一)
需要 基礎 under 情況下 學生 意義 span 公式 ext 貝葉斯在機器學習中的應用(一) 一:前提知識 具備大學概率論基礎知識 熟知概率論相關公式,並知曉其本質含義/或實質意義
吳恩達老師機器學習筆記異常檢測(一)
明天就要開組會了,天天在辦公室划水都不知道講啥。。。 今天開始異常檢測的學習,同樣程式碼比較簡單一點 異常檢測的原理就是假設樣本的個特徵值都呈高斯分佈,選擇分佈較離散的樣本的作為異常值。這裡主要注意的是通過交叉驗證對閾值的選擇和F1score的應用。 原始資料: 程式碼如下:
機器學習筆試題精選 知識點
參考: https://www.analyticsvidhya.com/blog/2016/12/45-questions-to-test-a-data-scientist-on-regression-skill-test-regression-solution/ https://blog.
機器學習之數學系列(一)矩陣與矩陣乘法
1.對於矩陣的認識應當把它看成是多個向量的排列表或把矩陣看成行向量,該行向量中的每個元素都是一個列向量,即矩陣是複合行向量。如下圖所示。 2.對於下面這個矩陣的乘法有兩種看法: (1)矩陣將向量[b1,b2,b3].T進行了運動變換,這種變換可以是同空間內變換,也可以是不同空間間的變換;
【機器學習】softmax迴歸(一)
在 softmax迴歸中,我們解決的是多分類問題(相對於 logistic 迴歸解決的二分類問題),類標 可以取 個不同的值(而不是 2 個)。因此,對於訓練集 ,我們有 。(注意此處的類別下標從 1 開始,而不是 0)。例如,在 M
《機器學習實戰》 筆記(一):K-近鄰演算法
一、K-近鄰演算法 1.1 k-近鄰演算法簡介 簡單的說,K-近鄰演算法採用測量不同特徵值之間的距離的方法進行分類。 1.2 原理 存在一個樣本資料集合,也稱作訓練樣本集,並且樣本集中每個資料都存在標籤,即我們知道樣本集中每一資料 與所屬分類的對應關係。輸入沒有標籤的新資料
機器學習面試題總結(轉)
原文連結: https://blog.csdn.net/sinat_35512245/article/details/78796328 1.請簡要介紹下SVM。 SVM,全稱是support vector machine,中文名叫支援向量機。SVM是一個面向資料的分類演算法,它的目標是為確定一個
Python機器學習基礎教程筆記(一)
description: 《Python機器學習基礎教程》的第一章筆記,書中用到的相關程式碼見github:https://github.com/amueller/introduction_to_ml_with_python ,筆記中不會記錄。 為何選擇機器學習 人為制訂決
機器學習技法筆記總結(一)SVM系列總結及實戰
機器學技法筆記總結(一)SVM系列總結及實戰 1、原理總結 在機器學習課程的第1-6課,主要學習了SVM支援向量機。 SVM是一種二類分類模型。它的基本模型是在特徵空間中尋找間隔最大化的分離超平面的線性分類器。 (1)當訓練樣本線性可分時,通過硬間隔最大化,學習
秋招線上筆試題-測試(一)
1、白盒測試方法中,邏輯覆蓋發現錯誤的能力,從強到弱排序為: 路徑覆蓋、條件組合、判定+條件覆蓋、條件覆蓋、判定覆蓋、語句覆蓋 2、解決IP地址資源有限問題:當前使用最多的是NAT方式(多個內網共享一個IP),未來主要通過ipv6方式解決 3、malloc函式與fr
【機器學習+sklearn框架】(一) 線性模型之Linear Regression
前言 一、原理 1.演算法含義 2.演算法特點 二、實現 1.sklearn中的線性迴歸 2.用Python自己實現演算法 三、思考(面試常問) 參考 前言 線性迴歸(Linear Regression)基本上可以說是機器