
斯坦福自然語言處理習題課2---softmax函式詳解
從現在開始,我們就要正式開始向大家講解斯坦福大學CS224n作業的實現了。我們首先業看作業關於softmax函式實現部分。我們在這裡將先向大家介紹softmax函式的具體應用場景和物理意義,以及採用numpy和python實現中需要注意的地方,在下一篇文章中,我們再向大家介紹CS224n作業1中softmax的具體實現。之所以這樣安排,是因為數學是一個非常優雅的建模工具,可以非常優雅的描述物理過程,但是由於數學這方面太過優雅,也容易使人們只關注數學模型,而對後面的物理過程反而忽略了。所以在這裡我們首先強調物理過程,然後才是數學原理,最後是具體實現細節。
我們首先來看softmax函式的典型應用場景。softmax函式最典型的應用場景是作為多分類問題的神經網路輸出層的啟用函式。這句話很難理解,我們可以以一個具體的例子來加深同學們的理解。
我們以大家都很熟悉的MNIST手寫數字識別資料集為例,這個資料集基本相當於深度學習領域的Hello World。如下圖所示:
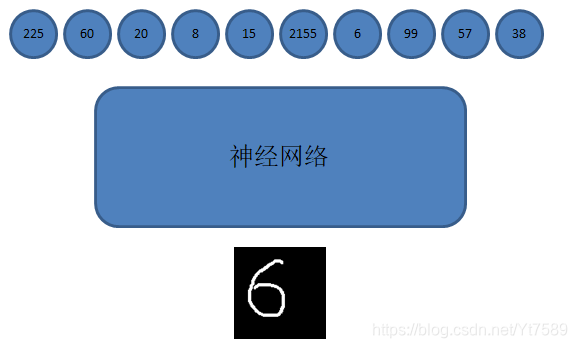
如圖所示,MNIST手寫資料集中,每個訓練樣本是一個黑底白字,解析度為2828的黑白圖片,將這個圖片784(784=2828)個畫素點,組成一個向量,就是神經網路的輸入訊號。神經網路可以取各種神經網路,如多層感知器MLP、卷積神經網路CNN等,這些網路的輸出層,通常設計有10個神經元,分別代表0~9這10個數字,並且我們可以訓練網路,使這10個神經元的值越大,表明該神經元所代表的數字出現的可能性越大,我們可以取這10個神經元中輸出值最大的那個神經元所代表數字作為識別結果。這就是一個神經網路多分類系統的一個簡單的描述。
但是直接使用輸出層神經元的輸出值,比較不直觀,這個數值本身沒有意義,只有與其他神經元的輸出值相比較後,才有意義。例如上圖中,第一個輸出層神經元的輸出為225,這個神經元代表數字0,僅知道第一個神經元的輸出為225,我們不能得出任何結論。比如說如果其他輸出層神經元輸出值只有幾個或幾十的話,這個值就比較大了,所以可以判定識別結果是數字0。但是如果其他輸出層神經元的輸出都是幾千幾萬,那麼225這個值就很小了,那麼識別結果就不可能為數字0了。由此可見,直接使用神經元的輸出訊號比較麻煩,這時我們就可以引入softmax函式。
softmax函式就是將輸出層神經元的輸出值,轉化為該神經元所代表的數字出現的概率,並且所有神經元的概率之和等於1,因為我們研究的問題性質決定識別結果必定是0~9這10個數字之一。如下圖所示:
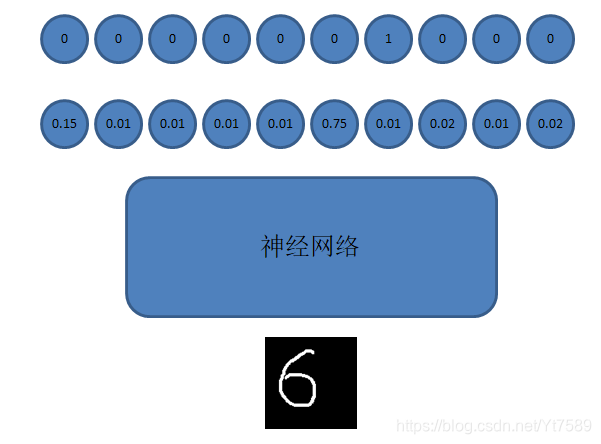
如上圖所示,圖中下面一層的圓圈代表神經網路的輸出,每個神經元的輸出表明該神經元所代表的數字出現的概率,這時我們還以第一個神經元為例,其值為0.15,表明數字0出現的概率是15%,所以識別結果就不太可能是數字0。出現概率最大的神經元是代表數字5的神經元,因此這個神經網路的識別結果就會是數字5。神經網路的識別結果是不是正確的呢?因為我們是監督學習,我們是有正確識別結果的,在上圖中就是最上面一層圓圈所示的結果,其中為1的圓圈就是這個訓練樣本對應的正確識別結果。我們看到正確識別結果是6,而我們神經網路的識別結果卻是5,這表明我們神經網路的識別結果是錯誤,需要訓練我們的神經網路,才能產生正確的結果。所以在實際應用中,會對上面兩層圓圈分別對應的神經網路輸出和正確輸出,做交叉熵(Cross Entropy),然後採用例如隨機梯度下降演算法,對神經網路的引數進行調整,達到能夠輸出正確識別結果的目的。這些內容我們將在後續課程中詳細講解,在本節中重點是向大家介紹softmax函式,大家也只需關注softmax函式相關內容即可,其他內容大致有個瞭解即可。
softmax函式
我們用代表輸出層為神經網路的第層第神經元的輸出訊號,則softmax函式定義為:
我們習慣稱神經網路的輸出為,而正確的結果為。
有了上面的函式定義,我們可以很容易的寫出求softmax函式的程式:
import numpy as np
def main():
z = np.array([3, 2, 1], dtype=np.float32)
z = np.exp(z)
denominator = np.sum(z)
z /= denominator
print(z)
if '__main__' == __name__:
main()
執行結果為:

這個程式非常簡單,同學們可能會有選這門課上當了的感覺。但是如果只有這麼簡單,那麼我們開這門課還會有什麼意義呢?我們來看下面這個程式:
import numpy as np
def main():
z = np.array([3, 2000000, 1], dtype=np.float32)
z = np.exp(z)
denominator = np.sum(z)
z /= denominator
print(z)
if '__main__' == __name__:
main()
程式一點沒變,只是陣列z的第2維由原來的2變為200000了,我們執行一下,結果如下所示:

這是怎麼回事呢?為了探究這個問題的原因,我們先來看一下指數函式曲線,如下所示:
import numpy as np
import matplotlib.pyplot as plt
def main():
x = np.linspace(-10, 10, 100)
y = np.exp(x)
plt.plot(x, y)
plt.show()
if '__main__' == __name__:
main()
在這個程式中我們使用matplotlib來繪製圖形,這個庫我們在課程後面會經常用到,功能非常強大,我們會在用到的時候再詳細給大家講解,這裡就用其最基本的繪圖功能。繪製出來的曲線如下所示:
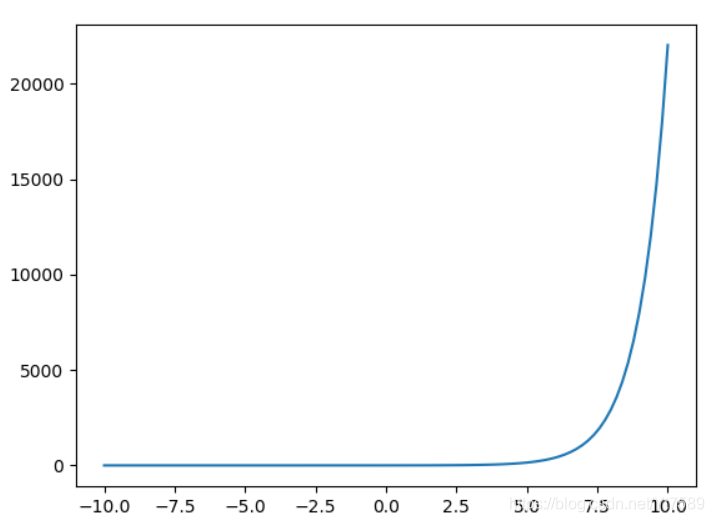
如圖所示,我們看到,當x的值大於5左右時,函式的值就開始劇烈增長了,當x=200000時,可想而知是一個多大的值了。我們知道計算機表示的數值是一定範圍的,對200000取e為底的指數時,計算機會產生溢位,會得到一個無窮大的結果。我們接著對這個數再做運算時,就會產生Not a Number錯誤,就是執行結果中的nan。這說明我們上面的softmax函式實現是有問題的。那麼怎麼來解決這個問題呢?其實斯坦福大學的老師在作業裡已經給了我們解決方案,大家看作業1的assignment1.pdf中,有這樣一個需要大家證明的問題:
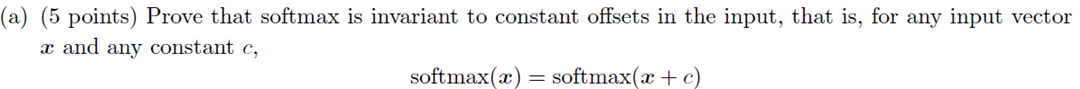
對於這個問題的證明,我們將在課程稍後時間來講解,這裡先給大家講解一下怎麼來用這個性質來解決我們softmax函式實現中的BUG。既然在softmax函式的每一項上加一下常量,softmax函式的值不變,那麼在每一項上減一個常數,softmax值也不會變。那麼我們可以在每一項上減去所有項的最大值,這樣softmax函式的每一項就變最大為0的數值了,這樣就不會出現溢位的問題了,基於這個思路,我們就有了第二版的softmax函式實現:
import numpy as np
def main():
z = np.array([3, 200000, 1], dtype=np.float32)
z -= np.max(z)
z = np.exp(z)
denominator = np.sum(z)
z /= denominator
print(z)
if '__main__' == __name__:
main()
可以看到,我們的程式並沒有進行大的修改,只是把z的每一項均減一下最大值,我們來看一下執行結果:

我們看這樣就可以得到正確的結果了。我們可以慶祝一下,我們終於做出了一個正確的softmax函式。但是其實即使是這個函式,我們也還是有可以改進的地方,如\ref{c000004}的第6行,我們使用z=np.exp(z)的形式,這樣就會返回一個與z維度相同的陣列,元素為z中元素取以e為底指數的值。為了提高效率,我們可以直接將取以e為底指數的值放到原始陣列z中,如下所示:
import numpy as np
def main():
z = np.array([3, 200000, 1], dtype=np.float32)
z -= np.max(z)
np.exp(z, z)
denominator = np.sum(z)
z /= denominator
print(z)
if '__main__' == __name__:
main()
softmax函式性質證明
接下來我們證明我們解決方案的正確性:
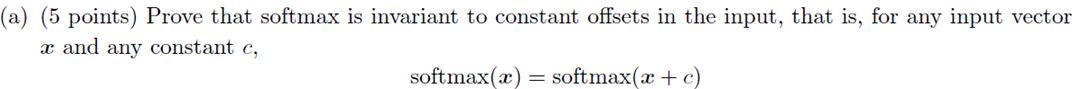
證明過程如下所示:
在下一節中,我們將帶領大家實現建立Python虛擬開發環境,將作業由python2移植到python3,採用in place方式提高計算效率,最後簡單介紹一下作業最後的測試驅動開發(TDD)的理念。
如果大家覺得觀看文章不夠直觀,請移步到我們的視訊課程:斯坦福自然語言處理習題課(https://study.163.com/course/introduction.htm?courseId=1006361019&share=2&shareId=400000000383016)