
MeanShift 均值漂移演算法
前面說了K-Means聚類演算法,這裡我們介紹一種新的聚類演算法:MeanShift, 它常被用在影象識別中的目標跟蹤,資料聚類、分類等場景,前者的核函式使用了Epannechnikov核函式,後者使用了Gaussian(高斯核函式)
一 演算法的原理理解:
1 核函式
在Mean Shift演算法中引入核函式的目的是使得隨著樣本與被偏移點的距離的不同,其偏移量對均值偏移向量的貢獻也不同,下面看下核函式的定義

我的理解:這裡的K(x)相當於一個球型的剖面,它確定了一個區域
下面我們來介紹兩種核函式,高斯核函式:
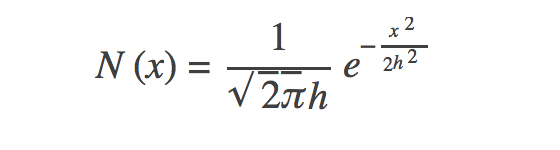
這裡的分母中的h,被稱為頻寬,不同頻寬的核函式如下圖所示:計算與畫圖程式碼如下:
import matplotlib.pyplot as plt import math def cal_Gaussian(x, h=1): molecule = x * x #分子 denominator = 2 * h * h #分母 left = 1 / (math.sqrt(2 * math.pi) * h) # math.sqrt開根號,math.pi派 return left * math.exp(-molecule / denominator) # math.exp 對應 底數e def basicPrinciple(): x = [] for i in range(-50, 50): x.append(i * 0.5) score_1 = [] scroe_2 = [] score_3 = [] score_4 = [] for i in x: score_1.append(cal_Gaussian(i, 1)) scroe_2.append(cal_Gaussian(i, 2)) score_3.append(cal_Gaussian(i, 3)) score_4.append(cal_Gaussian(i, 4)) ''' print('score_1=', score_1) print('scroe_2=', scroe_2) print('score_3=', score_3) print('score_4=', score_4) ''' plt.figure() plt.plot(x, score_1, color = 'blue', linestyle = '--', label = 'h = 1') plt.plot(x, scroe_2, color = 'red', linestyle = '--', label = 'h = 2') plt.plot(x, score_3, color = 'orange', linestyle = '--', label = 'h = 3') plt.plot(x, score_4, color = 'yellow', linestyle = '--', label = 'h = 4') plt.legend(loc="upper right") plt.xlabel('x') plt.ylabel('N') plt.show() return def workSpace(): basicPrinciple() return workSpace()

可以看到h越大x的寬度越大
2 Mean Shift演算法的核心演算法原理與思想
Mean Shift演算法和k-means相似,都是一個迭代的過程,即先算出當前點的偏移均值,將該點移動到該偏移均值,以此為新的起始點,繼續移動,直到滿足最終的條件。
下面給了張物理方面的圖示,來理解下:
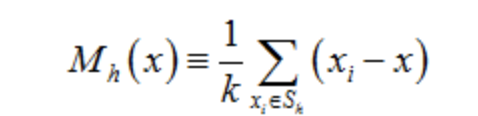
這裡的S(h)是一個半徑為h的高維球區域,滿足以下等式關係的y點的集合:
上面等式中的k值表示在這n個樣本點x(i)中,有k個點落入S(h)區域,在上式中,我們可以看到(x(i) - x)是樣本x(i)相對於點x的偏移向量,上面式子做的就是落入區域S(h)中的k個樣本點相對於點x偏移向量求和然後再平均,那麼如果樣本點x(i)從一個概率密度函
數f(x)中取樣得到,由於非零的概率密度梯度指向概率密度增大的最大的方向,因此從平均上來說,S(h)的樣本點更多的是落在沿著概率密度梯度的方向,因此,對應的,
Mean Shift向量M(x)應該指向概率密度梯度的方向。
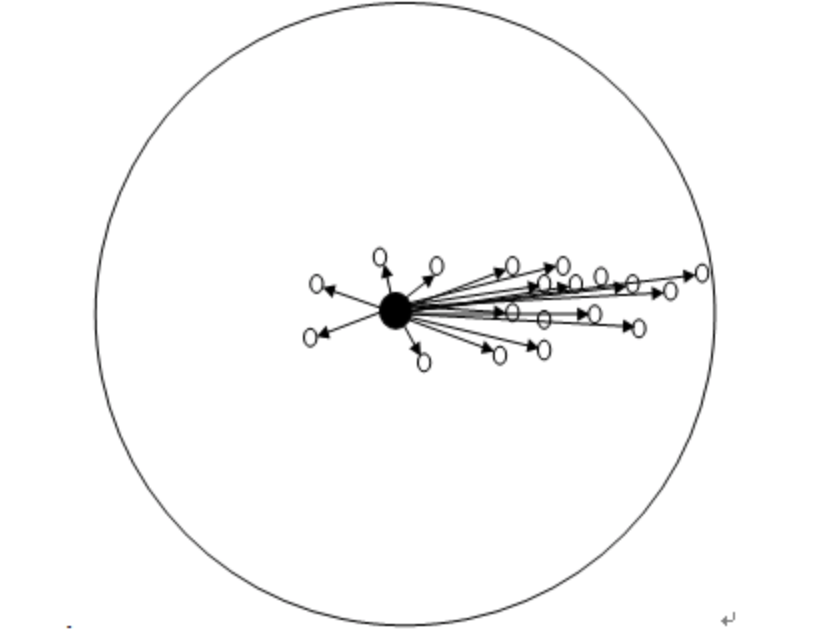
如上圖所示,大圓圈所圈住的是S區域,小圓圈表示落入S區域的樣本點x(i), 黑色的點就是Mean Shift的基準點x,箭頭表示樣本點相對於基準點x的偏移向量,很明顯我們可以看出,平均的偏移M(x)會指向樣本分佈最多的區域,也就是概率密度函式梯度的方向。
注:這裡,在上面式子中看到,只要是落入S區域的取樣點,無論其離中心點x的遠近,對最終M(x)的計算的貢獻是一樣的。然而在這個迭代的過程中,每個x(i)對於求解均值時的貢獻是不同的,所以這裡引入了其他型別的核函式。下面將下高斯核函式的方式。
3 用高斯核函式改進Mean Shift演算法
把高斯核函式和樣本權重加入M(x)的式子中,得到Mean Shift向量的新的形式:

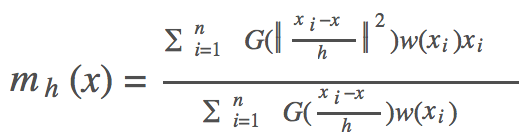
把mh代入Mh則可以得到下列公式,正好印證了梯度上升的過程:
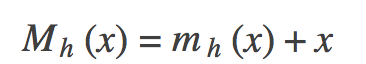
下面我們來看下高斯核函式是什麼樣子的:
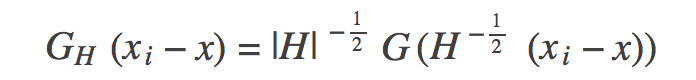

式子中的H如上面這個矩陣。
二 以下是個應用的例子,demo
參考部落格:http://blog.csdn.net/google19890102/article/details/51030884
https://www.cnblogs.com/ywsoftware/p/4434595.html