
機器學習特徵工程之特徵抽取
阿新 • • 發佈:2019-01-07
1.資料集
資料集是特徵抽取的源資料。常用資料集的結構組成:特徵值+目標值。
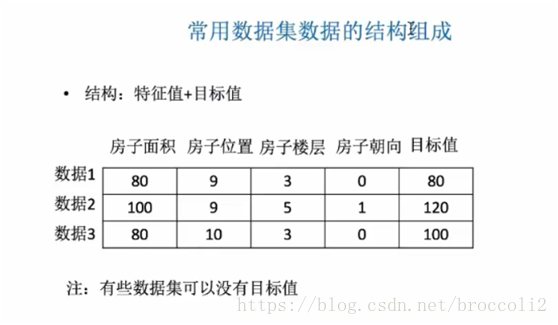
資料中對於特徵的處理
pandas:一個數據讀取非常方便以及基本的處理格式的工具。
sklearn:對於特徵的處理提供了強大的介面。
2.資料的特徵工程
2.1 特徵工程是什麼?
特徵工程是將原始資料轉換為更好的代表預測模型的潛在問題的特徵的過程,從而提高了對未知資料的預測準確性。
2.2 特徵工程的意義是什麼?
特徵工程直接影響預測結果。
2.3 特徵工程包含哪些步驟?
特徵工程包括資料的特徵抽取、資料的特徵與處理和資料的降維(資料降維就是篩選樣本特徵,去掉不重要的樣本特徵)
2.4 scikit-learn庫介紹
- python語言的機器學習工具。
- scikit-learn包括許多致命的機器學習演算法的實現。
scikit-learn文件完善,容易上手,豐富的API。
2.5 scikit-learn庫的安裝

3資料的特徵抽取
特徵抽取的目的是對文字進行特徵值化(為了讓計算機更好地理解資料)。
3.1字典特徵抽取
作用:對字典資料進行特徵值化將其轉換為One-hot編碼。
類:sklearn.feature_extraction.DicVectorizer
DicVectorizer語法:

流程:

One-hot編碼分析
3.2文字特徵抽取
作用:對文字資料進行特徵值化。
類:sklearn.feature_extraction.text.CountVectorizer
CountVectorizer語法

流程

- 統計所有文章中的所有的詞,重複的詞只看做一次。
- 對每篇文章,在詞的列表裡面進行統計每個詞出現的次數。
單個英文字母或漢字不統計。
英文文章可以直接進行統計,中文的文章要先進行分詞才能進行統計。
jieba分詞
對中文進行分詞處理,使用jieba分詞。

特徵抽取方式之詞語佔比
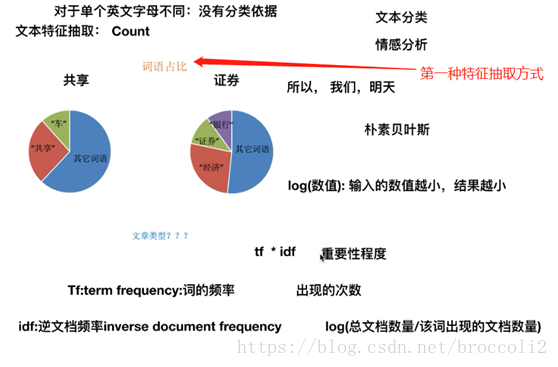
特徵抽取方式之TF-IDF
TF-IDF(TfidfVectorizer)是分類機器學習演算法的重要依據。
