
深度學習剖根問題:梯度消失/爆炸
一、梯度消失/梯度爆炸的問題
首先來說說梯度消失問題產生的原因吧,雖然是已經被各大牛說爛的東西。不如先看一個簡單的網路結構,
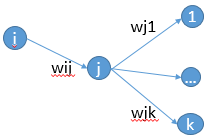
可以看到,如果輸出層的值僅是輸入層的值與權值矩陣W的線性組合,那麼最終網路最終的輸出會變成輸入資料的線性組合。這樣很明顯沒有辦法模擬出非線性的情況。記得神經網路是可以擬合任意函式的。好了,既然需要非線性函式,那乾脆加上非線性變換就好了。一般會使用sigmoid函式,得到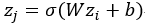 ,這個函式會把資料壓縮到開區間(0,1),函式的影象如下
,這個函式會把資料壓縮到開區間(0,1),函式的影象如下

可以看到,函式的兩側非常平滑,而且無限的接近0和1,僅僅是中間部分函式接近一條直線,順便說一下,這個函式的導數最值竟然真的是1啊,也就是x=0的位置,因而稱這個函式是雙端飽和的,而且它是處處可導。那麼,為什麼要選用它呢?看到有資料說是模擬神經學科的,但我不太懂這個,個人認為是因為
另外,有一個函式與sigmoid函式很類似,就是tanh()函式,它可以把資料壓縮到(-1,1)之間。
但是,我們要講的是梯度的消失問題哦,要知道,神經網路訓練的方法是BP演算法(不知道還有沒有其他的訓練方法。。。)。BP演算法的基礎其實就是導數的鏈式法則,這個估計不需要細說了,就是有很多乘法會連線在一起。在看看sigmoid函式的影象就知道了,導數最大是1,而且大多數值都被推向兩側飽和的區域,這些區域的導數可是很小的呀~~~~可以預見到,隨著網路的加深,梯度後向傳播到淺層網路時,就呵呵了,基本不能引起數值的擾動,這樣淺層的網路就學習不到新的特徵了。
那麼怎麼辦?我暫時看到了四種解決問題的辦法,僅僅是根據我自己看的論文總結的,並非權威的說法。第一種很明顯,可以通過使用別的啟用函式;第二種可以使用層歸一化;第三種是在權重的初始化上下功夫,第四種是構建新的網路結構~。但暫時不寫,我還想記錄一下看到的梯度消失/爆炸問題在另一個經典網路的出現。
二、選擇其他啟用函式
啟用函式有很多其他的選擇,常看見的有ReLU、Leaky ReLU函式。下面就說一說這兩個函式,對於ReLU,函式為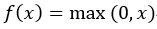 ,觀察一下它的函式影象
,觀察一下它的函式影象
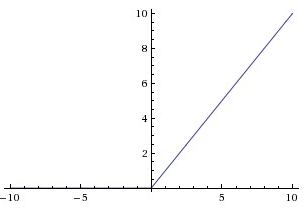
可以看到,它在負數的一段永遠是0啊。為什麼要使用這個函式呢?據說它是與神經學科有關的,這是因為稀疏啟用的,這表現在負數端是抑制狀態,正數興奮啟用。而且有理論也表明,稀疏的網路更準確,在googLeNet的實現中就是利用了神經網路的稀疏性。而且,在正數端導數永遠為1,這就很好地解決了梯度消失的問題了。可是,它沒有把資料壓縮,這會使得資料的範圍可能很大。
此外還有Leaky ReLU函式,這個我是在YOLO看到的,其實和ReLU差不多,就是在負數端不完全抑制了。影象如下:

三、層歸一化
這裡記錄的是Batch Normalization。主要參考的總結,可憐我只是個搬運工啊。
先說一說BN解決的問題,論文說要解決 Internal covariate shift 的問題,covariate shift 是指源空間與目標空間中條件概率一致,但是邊緣概率不同。在深度網路中,越深的網路對特徵的扭曲就越厲害(應該是這樣說吧……),但是特徵本身對於類別的標記是不變的,所以符合這樣的定義。BN通過把輸出層的資料歸一化到mean = 0, var = 1的分佈中,可以讓邊緣概率大致相同吧(知乎魏大牛說不可以完全解決,因為均值方差相同不代表分佈相同~~他應該是對的),所以題目說是reducing。
那麼BN是怎麼實現的呢?它是通過計算min batch 的均值與方差,然後使用公式歸一化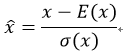 。例如啟用函式是sigmoid,那麼輸出歸一化後的影象就是
。例如啟用函式是sigmoid,那麼輸出歸一化後的影象就是
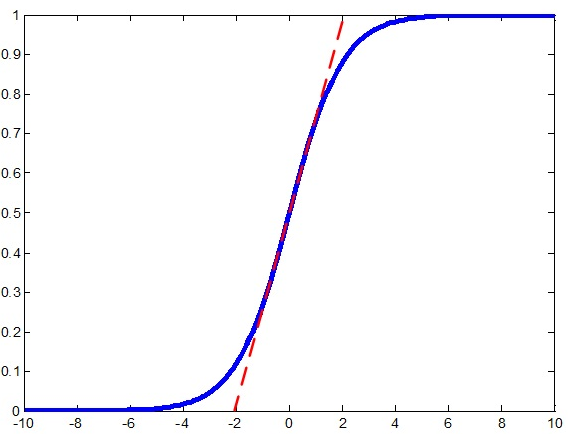
中間就是接近線性了,這樣,導數幾乎為常數1,這樣不就可以解決梯度消失的問題了嗎?
但是,對於ReLU函式,這個是否起作用呢?好像未必吧,不過我覺得這個歸一化可以解決ReLU不能把資料壓縮的問題,這樣可以使得每層的資料的規模基本一致了。上述(3)中寫到一個BN的優點,我覺得和我的想法是一致的,就是可以使用更高的學習率。如果每層的scale不一致,實際上每層需要的學習率是不一樣的,同一層不同維度的scale往往也需要不同大小的學習率,通常需要使用最小的那個學習率才能保證損失函式有效下降,Batch Normalization將每層、每維的scale保持一致,那麼我們就可以直接使用較高的學習率進行優化。這樣就可以加快收斂了。我覺得還是主要用來減少covariate shift 的。
但是,上述歸一化會帶來一個問題,就是破壞原本學習的特徵的分佈。那怎麼辦?論文加入了兩個引數,來恢復它本來的分佈![]() 這個帶入歸一化的式子看一下就可以知道恢復原來分佈的條件了。但是,如果恢復了原來的分佈,那還需要歸一化?我開始也沒想明白這個問題,後來看看別人的解釋,注意到新新增的兩個引數,實際上是通過訓練學習的,就是說,最後可能恢復,也可能沒有恢復。這樣可以增加網路的capicity,網路中就存在多種不同的分佈了。最後抄一下BP的公式:
這個帶入歸一化的式子看一下就可以知道恢復原來分佈的條件了。但是,如果恢復了原來的分佈,那還需要歸一化?我開始也沒想明白這個問題,後來看看別人的解釋,注意到新新增的兩個引數,實際上是通過訓練學習的,就是說,最後可能恢復,也可能沒有恢復。這樣可以增加網路的capicity,網路中就存在多種不同的分佈了。最後抄一下BP的公式:
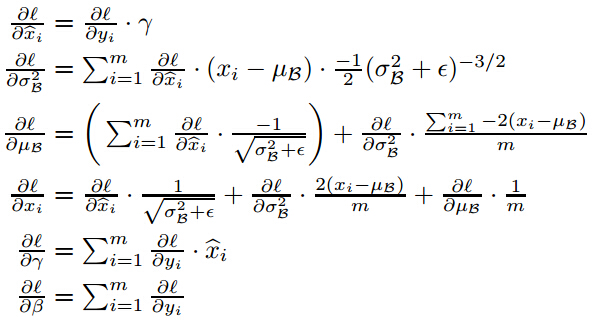
那麼在哪裡可以使用這個BN?很明顯,它應該使用在啟用函式之前。而在此處還提到一個優點就是加入BN可以不使用dropout,為什麼呢?dropout它是用來正則化增強網路的泛化能力的,減少過擬合,而BN是用來提升精度的,之所以說有這樣的作用,可能有兩方面的原因(1)過擬合一般發生在資料邊緣的噪聲位置,而BN把它歸一化了(2)歸一化的資料引入了噪聲,這在訓練時一定程度有正則化的效果。對於大的資料集,BN的提升精度會顯得更重要,這兩者是可以結合起來使用的。
最後貼一個演算法的流程,以及結構圖;

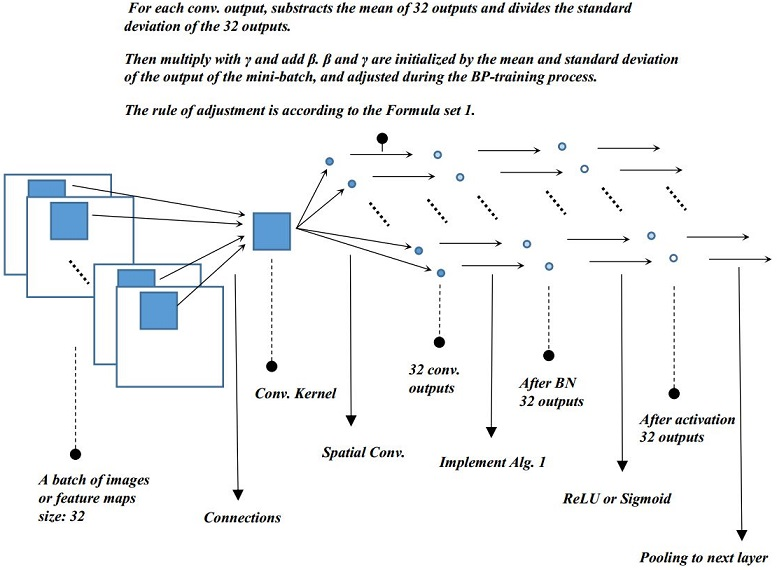
四、權值初始化
為了讓資訊可以更好的在網路中流動(不一定是梯度消失的問題),可以使用xavier的初始化方法。主要可以看知乎專欄。為了不重複別人的工作,我簡單總結一下算了。注意一個問題,xavier的初始化方法的前提假設是,啟用函式是線性的(其實歸一化後,可能把資料集中在了一處,就好像將BN的那張圖一樣)。
如果輸入資料x和權值w都滿足均值為0,標準差為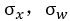 ,(x可以通過歸一化、白化實現)而且各資料是獨立同分布的。這樣,輸出為
,(x可以通過歸一化、白化實現)而且各資料是獨立同分布的。這樣,輸出為 ,根據概率公式,z 的均值依然為0,方差為
,根據概率公式,z 的均值依然為0,方差為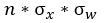 。
。
通過遞推公式可以得到 ,則
,則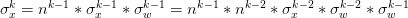 。於是,方差的計算公式為
。於是,方差的計算公式為![]() 。這裡又出現了連乘,還是按照之前與1比較的討論,那麼,最好是可以讓方差保持一致啦,這樣數值的幅度就不會相差太大,就好像上面BN說的那樣,可以收斂的更快。那麼就是讓連乘內的每一項都為1了,則可以推出權值的初始化為
。這裡又出現了連乘,還是按照之前與1比較的討論,那麼,最好是可以讓方差保持一致啦,這樣數值的幅度就不會相差太大,就好像上面BN說的那樣,可以收斂的更快。那麼就是讓連乘內的每一項都為1了,則可以推出權值的初始化為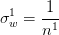 。
。
上面說的是前向的,那麼後向呢?後向傳播時,如果可以讓方差保持一致,同樣地會有前向傳播的效果,梯度可以更好地在網路中流動。由於假設是線性的,那麼迴流的梯度公式是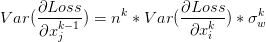 ,可以寫成
,可以寫成 。令迴流的方差不變,那麼權值又可以初始化成
。令迴流的方差不變,那麼權值又可以初始化成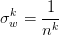 。注意一個是前向,一個是後向的,兩者的n 是不同的。取平均
。注意一個是前向,一個是後向的,兩者的n 是不同的。取平均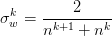 。
。
最後,是使用均勻分佈來初始化權值的,得到初始化的範圍 。
。
五、 調整網路的結構
Highway Network
Highway Network主要解決的問題是,網路深度加深,梯度資訊迴流受阻造成網路訓練困難的問題。先看下面的一張對比圖片,分別是沒有highway 和有highway的。
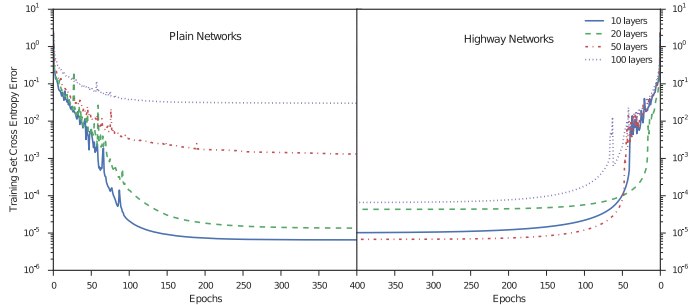
可以看到,當網路加深,訓練的誤差反而上升了,而加入了highway之後,這個問題得到了緩解。一般來說,深度網路訓練困難是由於梯度迴流受阻的問題,可能淺層網路沒有辦法得到調整,或者我自己YY的一個原因是(迴流的資訊經過網路之後已經變形了,很可能就出現了internal covariate shift類似的問題了)。Highway Network 受LSTM啟發,增加了一個門函式,讓網路的輸出由兩部分組成,分別是網路的直接輸入以及輸入變形後的部分。
假設定義一個非線性變換為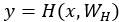 ,定義門函式
,定義門函式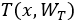 ,攜帶函式
,攜帶函式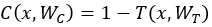 。對於門函式取極端的情況0/1會有
。對於門函式取極端的情況0/1會有 ,而對應的門函式使用sigmoid函式
,而對應的門函式使用sigmoid函式 ,則極端的情況不會出現。
,則極端的情況不會出現。
一個網路的輸出最終變為![]() ,注意這裡的乘法是element-wise multiplication。
,注意這裡的乘法是element-wise multiplication。
注意,門函式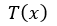 ,轉換
,轉換 ,
,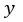 與
與 的維度應該是相同的。如果不足,可以用0補或者用一個卷積層去變化。
的維度應該是相同的。如果不足,可以用0補或者用一個卷積層去變化。
在初始化的時候,論文是把偏置 b 初始化為負數,這樣可以讓攜帶函式 C 偏大,這樣做的好處是什麼呢?可以讓更多的資訊直接回流到輸入,而不需要經過一個非線性轉化。我的理解是,在BP演算法時,這一定程度上增大了梯度的迴流,而不會被阻隔;在前向流動的時候,把允許原始的資訊直接流過,增加了容量,就好像LSTM那樣,可以有long - term temporal dependencies。
Residual Network
ResNet的結構與Highway很類似,如果把Highway的網路變一下形會得到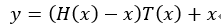 ,而在ResNet中,直接把門函式T(x)去掉,就得到一個殘差函式
,而在ResNet中,直接把門函式T(x)去掉,就得到一個殘差函式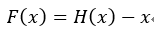 ,而且會得到一個恆等的對映 x ,對的,這叫殘差網路,它解決的問題與Highway一樣,都是網路加深導致的訓練困難且精度下降的問題。殘差網路的一個block如下:
,而且會得到一個恆等的對映 x ,對的,這叫殘差網路,它解決的問題與Highway一樣,都是網路加深導致的訓練困難且精度下降的問題。殘差網路的一個block如下:

是的,就是這麼簡單,但是,網路很強大呀。而且實驗證明,在網路加深的時候,依然很強大。那為什麼這麼強大呢?我覺得是因為identity map是的梯度可以直接回流到了輸入層。至於是否去掉門函式會更好呢,這個並不知道。在作者的另一篇論文《Identity Mappings in Deep Residual Networks》中,實驗證明了使用identity map會比加入卷積更優。而且通過調整啟用函式和歸一化層的位置到weight layer之前,稱為 pre-activation,會得到更優的結果。