微軟的深度殘差學習是否解決了梯度消失的問題?
阿新 • • 發佈:2019-02-17
這個偏導就是我們求的gradient,這個值本來就很小,而且再計算的時候還要再乘stepsize,就更小了所以通過這裡可以看到,梯度在反向傳播過程中的計算,如果N很大,那麼梯度值傳播到前幾層的時候就會越來越小,也就是梯度消失的問題
那DRN是怎樣解決這個問題的呢?
它在神經網路結構的層面解決了這個問題它將基本的單元改成了這個樣子
<img src="https://pic2.zhimg.com/50/90e58f36fc1b0ae42443b69176cc2a75_hd.png" data-rawwidth="435" data-rawheight="218" class="origin_image zh-lightbox-thumb" width="435" data-original="https://pic2.zhimg.com/90e58f36fc1b0ae42443b69176cc2a75_r.png">其實也很明顯,通過求偏導我們就能看到
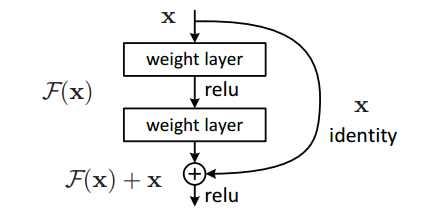
其實也很明顯,通過求偏導我們就能看到
這樣就算深度很深,梯度也不會消失了
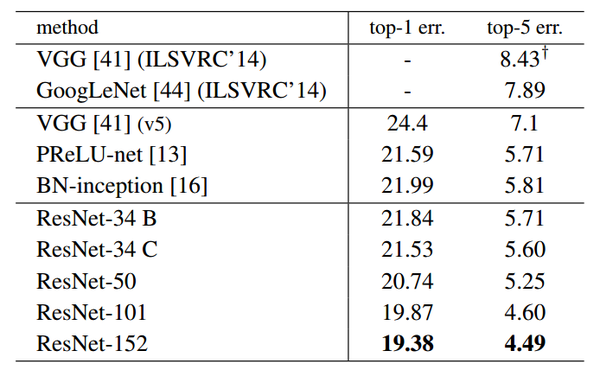
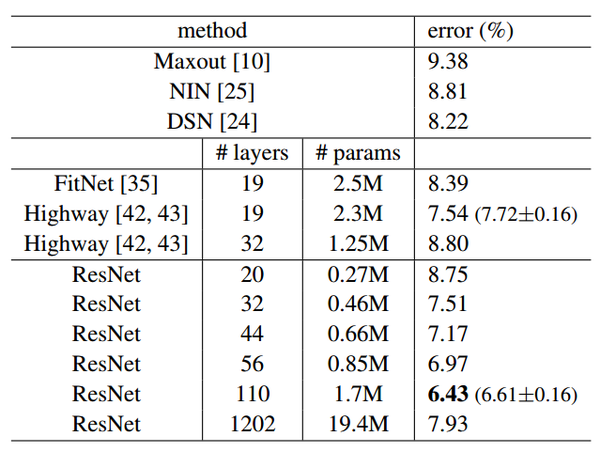
當然深度殘差這篇文章最後的效果好,是因為還結合了調引數以及神經網路的其他的細節,這些也很重要,不過就不是這裡我們關心的內容了可以看到,對於相同的資料集來講,殘差網路比同等深度的其他網路表現出了更好的效能
<img src="https://pic4.zhimg.com/50/v2-543d8c86899ec03d623e054b9d100cdb_hd.png" data-rawwidth="600" data-rawheight="370" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic4.zhimg.com/v2-543d8c86899ec03d623e054b9d100cdb_r.png">