
深度學習剖根問底:各種Loss大總結
1. 指數損失函式(Adaboost)
學過Adaboost演算法的人都知道,它是前向分步加法演算法的特例,是一個加和模型,損失函式就是指數函式。在Adaboost中,經過m此迭代之後,可以得到fm(x):
![]()
Adaboost每次迭代時的目的是為了找到最小化下列式子時的引數α和G:

而指數損失函式(exp-loss)的標準形式如下

可以看出,Adaboost的目標式子就是指數損失,在給定n個樣本的情況下,Adaboost的損失函式為:

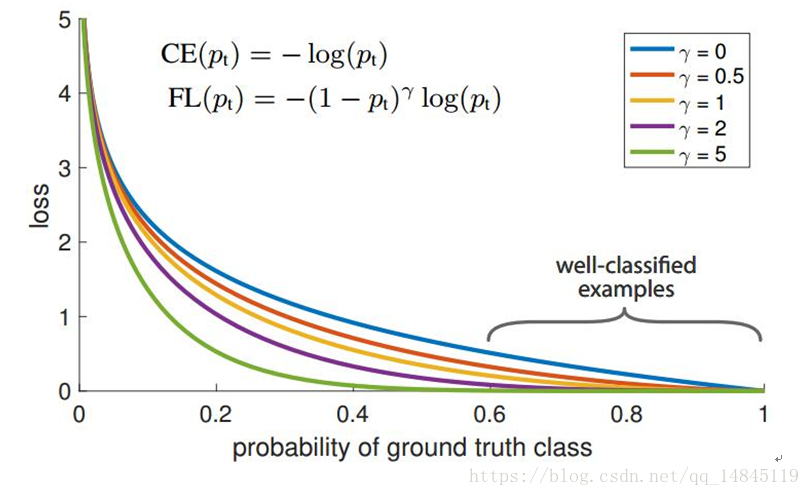
幾種損失函式的視覺化影象

引數越多,模型越複雜,而越複雜的模型越容易過擬合。過擬合就是說模型在訓練資料上的效果遠遠好於在測試集上的效能。此時可以考慮正則化,通過設定正則項前面的hyper parameter,來權衡損失函式和正則項,減小引數規模,達到模型簡化的目的,從而使模型具有更好的泛化能力。
2. log對數損失函式(邏輯迴歸)
有些人可能覺得邏輯迴歸的損失函式就是平方損失,其實並不是。平方損失函式可以通過線性迴歸在假設樣本是高斯分佈的條件下推導得到,而邏輯迴歸得到的並不是平方損失。在邏輯迴歸的推導中,它假設樣本服從伯努利分佈(0-1分佈),然後求得滿足該分佈的似然函式,接著取對數求極值等等。而邏輯迴歸並沒有求似然函式的極值,而是把極大化當做是一種思想,進而推匯出它的經驗風險函式為:最小化負的似然函式(即max F(y, f(x)) —-> min -F(y, f(x)))。從損失函式的視角來看,它就成了log損失函數了。
log損失函式的標準形式:
![]()
剛剛說到,取對數是為了方便計算極大似然估計,因為在MLE中,直接求導比較困難,所以通常都是先取對數再求導找極值點。損失函式L(Y, P(Y|X))表達的是樣本X在分類Y的情況下,使概率P(Y|X)達到最大值(換言之,就是利用已知的樣本分佈,找到最有可能(即最大概率)導致這種分佈的引數值;或者說什麼樣的引數才能使我們觀測到目前這組資料的概率最大)。因為log函式是單調遞增的,所以logP(Y|X)也會達到最大值,因此在前面加上負號之後,最大化P(Y|X)就等價於最小化L了。
邏輯迴歸的P(Y=y|x)表示式如下(為了將類別標籤y統一為1和0,下面將表示式分開表示):

將它帶入到上式,通過推導可以得到logistic的損失函式表示式,如下:
![]()
邏輯迴歸最後得到的目標式子如下:
![]()
上面是針對二分類而言的。這裡需要解釋一下:之所以有人認為邏輯迴歸是平方損失,是因為在使用梯度下降來求最優解的時候,它的迭代式子與平方損失求導後的式子非常相似,從而給人一種直觀上的錯覺。
3. 二分類交叉熵損失sigmoid_cross_entropy:
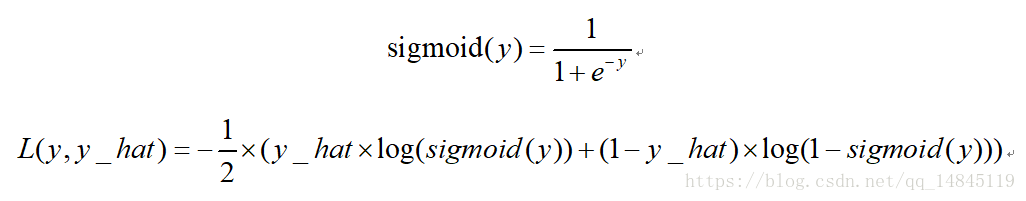
4. 二分類平衡交叉熵損失balanced_sigmoid_cross_entropy:
該損失也是用於2分類的任務,相比於sigmoid_cross_entrop的優勢在於引入了平衡引數 ,可以進行正負樣本的平衡,得到比sigmoid_cross_entrop更好的效果。
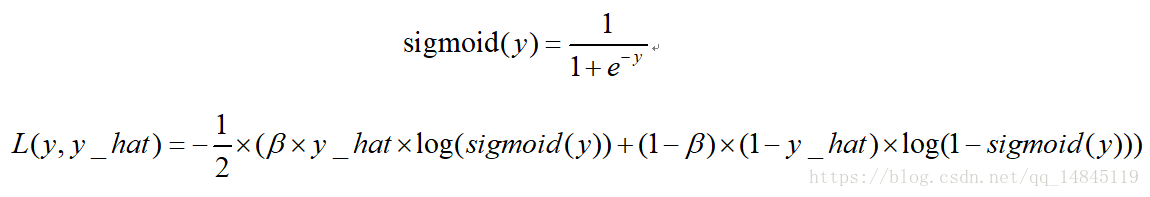
5. 多分類交叉熵損失softmax_cross_entropy:
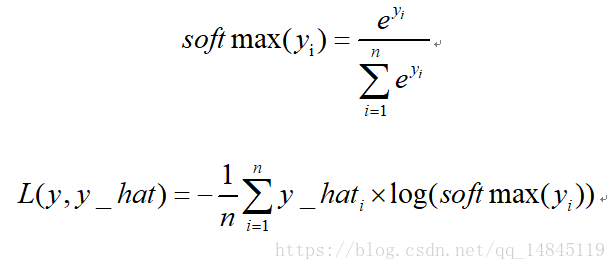
6. Focal loss:
focal loss為凱明大神的大作,主要用於解決多分類任務中樣本不平衡的現象,可以獲得比softmax_cross_entropy更好的分類效果。
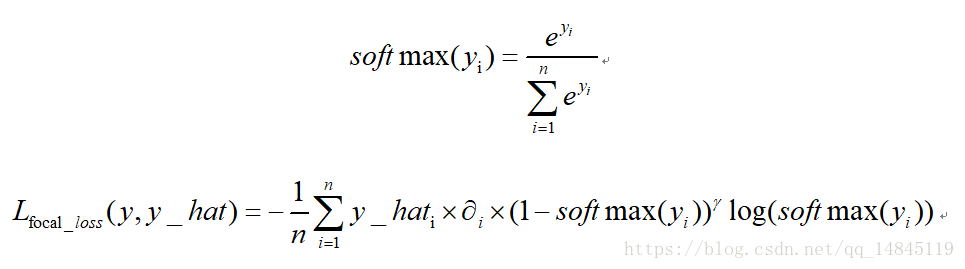
論文中α=0.25,γ=2效果最好。
7. 合頁損失hinge_loss:
也叫鉸鏈損失,是svm中使用的損失函式。
由於合頁損失優化到滿足小於一定gap距離就會停止優化,而交叉熵損失卻是一直在優化,所以,通常情況下,交叉熵損失效果優於合頁損失。
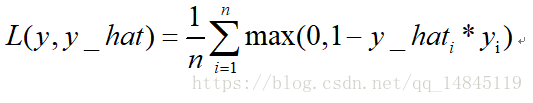
8. KL散度:
KL散度( Kullback–Leibler divergence),也叫相對熵,是描述兩個概率分佈P和Q差異的一種方法。它是非對稱的,這意味著D(P||Q) ≠ D(Q||P)。特別的,在資訊理論中,D(P||Q)表示當用概率分佈Q來擬合真實分佈P時,產生的資訊損耗,其中P表示真實分佈,Q表示P的擬合分佈。
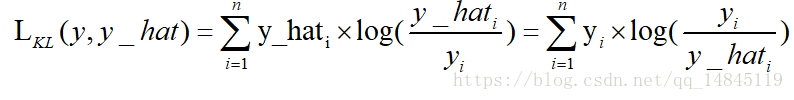
9. 最大間隔損失large margin softmax loss:
用於拉大類間距離的損失函式,可以訓練得到比傳統softmax loss更好的分類效果。
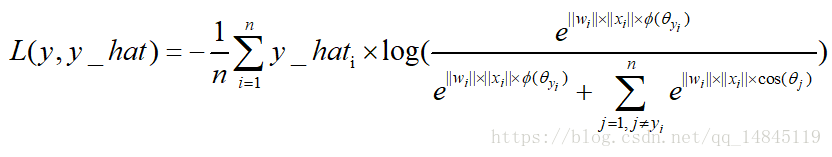
最大間隔損失主要引入了夾角cos值進行距離的度量。假設bias為0的情況下,就可以得出如上的公式。
其中fai(seita)需要滿足下面的條件。
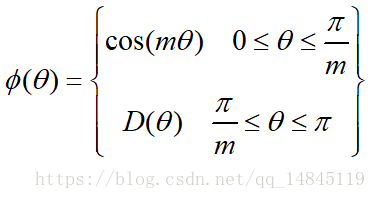
為了進行距離的度量,在cos夾角中引入了引數m。該m為一個正整數,可以起到控制類間間隔的作用。M越大,類間間隔越大。當m=1時,等價於傳統交叉熵損失。基本原理如下面公式

論文中提供的滿足該條件的公式如下
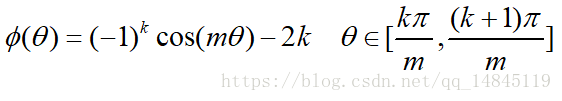
10. 中心損失center loss:
中心損失主要主要用於減少類內距離,雖然只是減少了累內距離,效果上卻可以表現出累內距離小了,類間距離就可以增大的效果。該損失不可以直接使用,需要配合傳統的softmax loss一起使用。可以起到比單純softmax loss更好的分類效果。
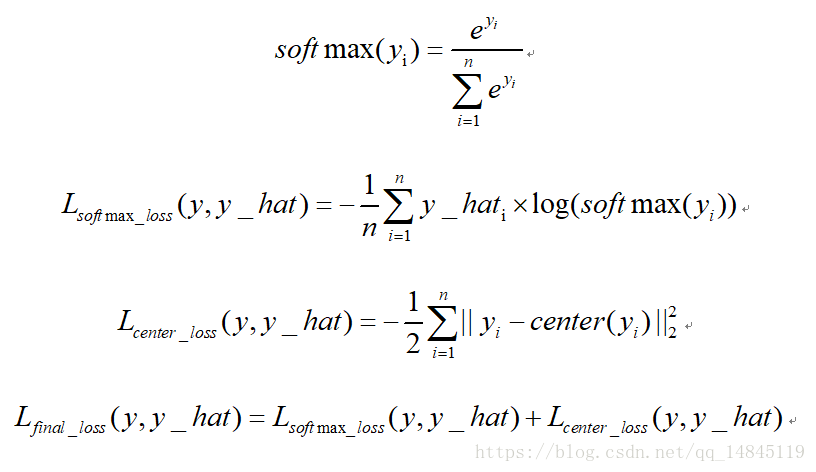
11. 迴歸任務loss:
均方誤差mean squareerror(MSE)和L2範數:
MSE表示了預測值與目標值之間差值的平方和然後求平均
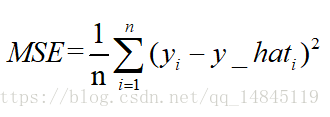
L2損失表示了預測值與目標值之間差值的平方和然後開更方,L2表示的是歐幾里得距離。
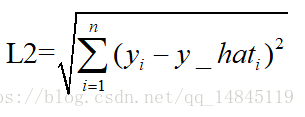
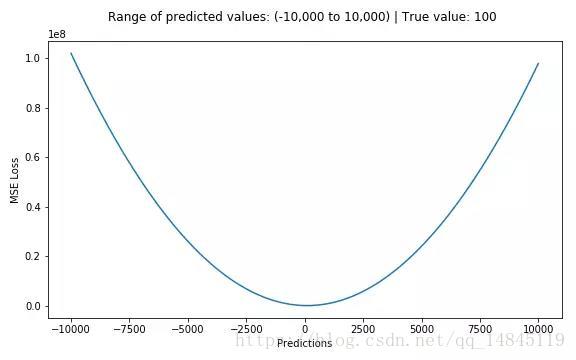
MSE和L2的曲線走勢都一樣。區別在於一個是求的平均np.mean(),一個是求的更方np.sqrt()
12. 平均絕對誤差meanabsolute error(MAE )和L1範數:
MAE表示了預測值與目標值之間差值的絕對值然後求平均
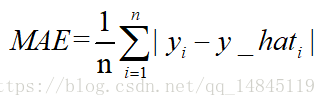
L1表示了預測值與目標值之間差值的絕對值,L1也叫做曼哈頓距離
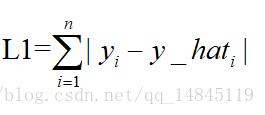
MAE和L1的區別在於一個求了均值np.mean(),一個沒有求np.sum()。2者的曲線走勢也是完全一致的。
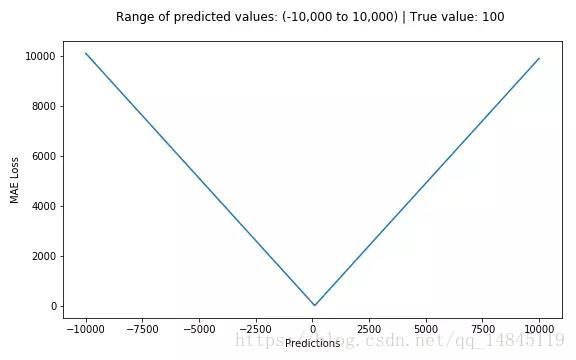
MSE,MAE對比:
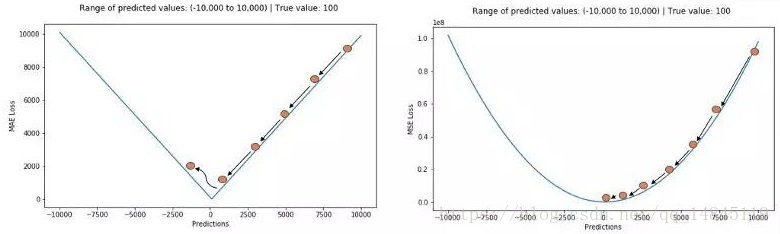
MAE損失對於局外點更魯棒,但它的導數不連續使得尋找最優解的過程低效;MSE損失對於局外點敏感,但在優化過程中更為穩定和準確。
13. Huber Loss和smooth L1:
Huber loss具備了MAE和MSE各自的優點,當δ趨向於0時它就退化成了MAE,而當δ趨向於無窮時則退化為了MSE。
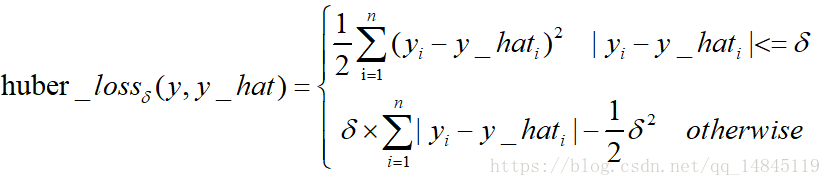
Smooth L1 loss也具備了L1 loss和L2 loss各自的優點,本質就是L1和L2的組合。
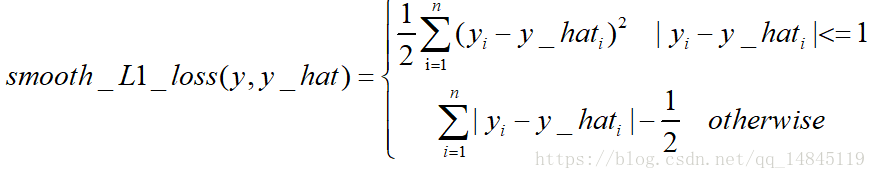
Huber loss和Smooth L1 loss具有相同的曲線走勢,當Huber loss中的δ等於1時,Huber loss等價於Smooth L1 loss。
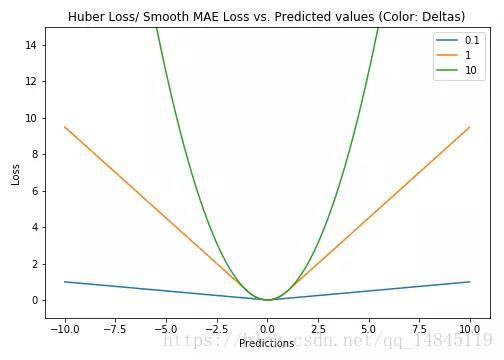
對於Huber損失來說,δ的選擇十分重要,它決定了模型處理局外點的行為。當殘差大於δ時使用L1損失,很小時則使用更為合適的L2損失來進行優化。
Huber損失函式克服了MAE和MSE的缺點,不僅可以保持損失函式具有連續的導數,同時可以利用MSE梯度隨誤差減小的特性來得到更精確的最小值,也對局外點具有更好的魯棒性。
但Huber損失函式的良好表現得益於精心訓練的超引數δ。
對數雙曲餘弦logcosh:
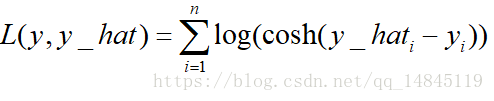
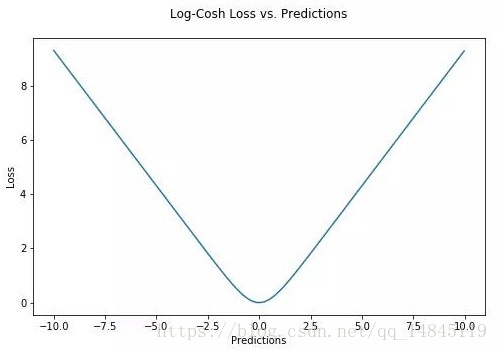
其優點在於對於很小的誤差來說log(cosh(x))與(x**2)/2很相近,而對於很大的誤差則與abs(x)-log2很相近。這意味著logcosh損失函式可以在擁有MSE優點的同時也不會受到局外點的太多影響。它擁有Huber的所有優點,並且在每一個點都是二次可導的。