
深度學習-淺談CNNs
偶爾看到了這篇文章,感覺作者寫的很容易理解,對於初步認識CNNs有很大的幫助,若想檢視原文,請點選此處。
關於神經網路的學習方法,總結起來的要點有以下幾點:
- BP演算法
- 激勵函式
- 正則化與交叉驗證等其他防止過擬合的方法
BP神經網路在之前的工作中取到了不錯的效果,但是在Micheal Nilson的數的第五章,描述了之前的神經網路在增加多個隱含層之後訓練效果會大大下降,也就是說,對於層數過多的網路訓練效果不理想,如何訓練深層的神經網路成了一個問題,這就是深度學習的由來。
深度學習近些年來很火,尤其是在自然語言處理領域,其取得的成就也是巨大的。之前我對深度學習是有畏懼心理的,因為我覺得挺難的,後來慢慢接觸,發現這個也是一個循序漸進的過程,還是要有信心。
深度學習一個最廣泛的應用就是卷積神經網路(deep convolutional neural networks),也就是CNN。這篇文章就簡要說一下CNN模型的基本模型。
1. Introduction of Convolutional Networks
還是以之前的手寫數字識別為基本,闡述CNN。
首先從之前的BP神經網路慢慢過渡到CNN,回顧之前的手寫識別問題,我們識別一副28*28的手寫圖片,我們將圖片轉換成畫素,然後手寫黑色點得畫素點標註為1,其他空白的畫素標註為0,因此形成了28*28個BP神經網路輸入層,然後我們設計了一個30個神經元的中間層,以及最後的10個神經元的輸入層,其典型結構如下:
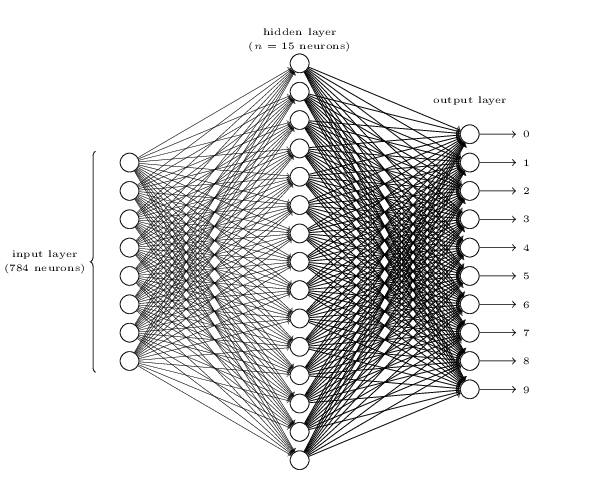
但是當我們想在這個模型上加了隱藏層層數的時候,其訓練結果就出現了很大的不穩定,在加入多個隱藏層之後需要學習的引數變得很多,這一方面增加了訓練的難度,也增加了訓練的不穩定性,在傳統的神經網路模型中,難以對深層的網路進行訓練,這就形成了一個瓶頸。因此需要一些新的模型,CNN就是這樣的新的模型。卷積神經網路的基本思想有以下三點:
- Local Receptive Fields (區域性視野)
- Shared Weights(權值共享)
- Pooling Layer(池化層)
2. Local Receptive Fields
在之前介紹的神經網路中,每個層的神經元總是與前面一層的所有神經元相連,也就是全相連,回想之前的BP神經網路,在隱藏層的神經元每個都和輸入層的28*28個直接相連,也就是說每個盛景園需要訓練 28*28+1個引數,但是在CNN中,隱藏層的神經元並不一定會和之前的所有神經元相連,以手寫數字識別為例,每個隱藏層的神經元都會和輸入層的部分神經元相連,如下圖:
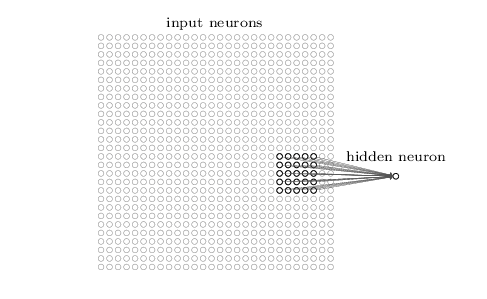
已上圖為例,隱藏層的神經元與輸入層的5*5個神經元相連,而這個5*5的區域就稱之為Local Receptive Fields,在上圖的隱藏層神經元中,需要訓練5*5+1個引數,也就是5*5個與上面對映區域的權重因子和一個偏移量bias。然後我們將上圖的5*5大小的視窗從上圖的左上角,按照從左到右,從上到下的規則逐漸移動到右下角,每次移動一個畫素點(這個是舉例,實際上可以改變這個值),因此我們可以得到如下的圖:
如上圖所示的移動方法,我們可以很順利的推出,隱藏層的結果是24*24個神經元(按照視窗移動法則)
明白了這點,我們就可以來了解shared weights and biases概念了。
3. Shared Weights and Biases
前面說到過,在隱藏層的每個神經元都是有5*5+1個引數,也就是25個權重w和一個偏移量b,但是之前沒有提到的是,在這個隱藏層中,所有的神經元的引數的值都是一樣的,也就是說,對於隱藏層的所有神經元,其輸出都是滿足下面的條件:
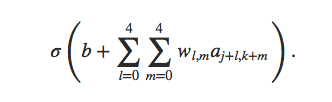
只不過,每個神經元對應的對映區域不一樣,也就是說上式的a值不同而已。注意上面式子的大括號左邊表示的是激勵函式,比如我們前面用到過的sigmoid函式。
為什麼這樣設計是有意義的,可以用一個簡單的比喻說明:一個貓的圖片的其中一個部分和其他的部分都是貓的一部分,也就是說都是貓的特徵,因此這兩個部分的特徵值(w,b)設定成一樣的。也是這樣,有時候,我們將從輸入層到隱藏層的對映稱之為 feature map(特徵對映)。shared weights 和bias經常被說成是 核心(kernel)或者過濾器(filter)。
實際應用中,我們可能會不只一個feature map,可能會有多個,如下圖所示:
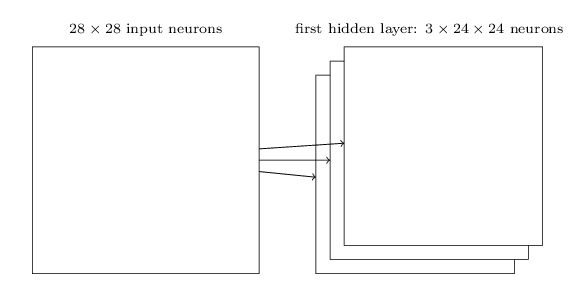
上圖就展示了從輸入層到隱藏層的三個feature map,每個map都有5*5+1個的訓練特徵,注意每一個map上的神經元的w和b是一樣的,但是不同的map之間則不一定(一般不一樣)。
4. Pooling Layer
Pooling Layer一般在卷基層後面(卷基層對應上面的隱藏層),該層的目的是為了簡化卷基層的訓練輸出資料。形象的說,pooling layer就是將卷基層進行壓縮一下,舉個例子,pooling layer的一個神經元可以對應卷積層的2*2區域的概括,具體的說,以最常用max pooling為例,在max pooling中,pooling層的每一個神經元的值對應卷積層的2*2的區域的最大輸出值,如下圖所示:
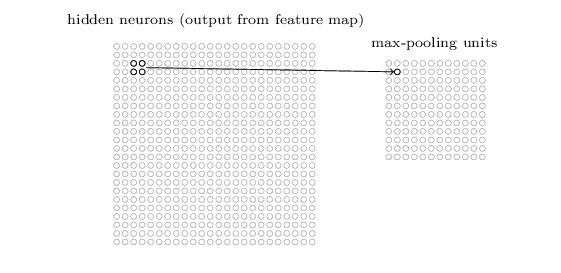
在24*24的卷積層壓縮之後,在pooling就只有12*12大小了。上文說過,卷積層的個數可能不止一個,因此一般會有下面的結構:
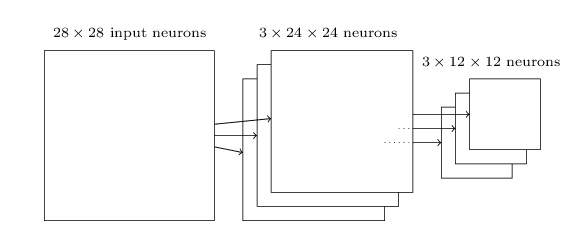
當然不止是max pooling一種技術用在了pooling layer,比如還有一種叫 L2 pooling的技術:其方法是取卷積層2*2區域輸出值的和值的開根號值,諸如此類。需要說明的是一直說的2*2區域只是為了描述隨便選的,並不是一定是2*2區域。
好了,現在可以將上面的所有元素組成一個整體了.我們可以使用下面的CNN網路模型:
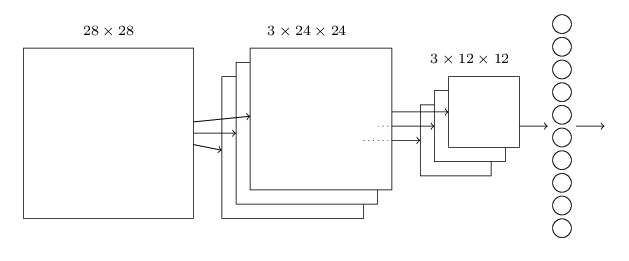
得到了模型,我們還是可以按照之前的梯度下降方法來求引數值,會在後面的學習中跟進這個部分。
上圖的最後一層是輸出層,也就是手寫識別的10個數字,需要說明的是這個輸出層和pooling層是全連線的,也就是說,輸出層的每個神經元都是和pooling層的所有神經元相連的。可以在中間多加幾個卷積層和pooling層。
這些是CNN的基本模型,而且也只是以單個卷積層和pooling層為例,實際中可能會有多個卷積層,而且對應的全連線情況也是變化很多,比如我們我可在輸出層之前再加一個全連線層。變化很多,因此這裡只是簡單的描述一下概念,後面會對CNN有更加深入的探討。