
Spark學習---Spark概述
起因:
我們實驗室是搞分散式計算的,所以我的目光就著落在了幾個大資料框架上:Spark, Storm, Flink等等。從中挑了了一個比較好做的就是spark了,目前還是基礎知識掌握階段,下週可能會定題目,看老師想法。這幾篇部落格完全由主觀撰寫,根據自己的想法覺得怎麼思考順利怎麼寫,如果對您有一點點幫助那太好了,沒有的話就權當自己練手。
首先說Google的三大馬車:Mapreduce,GFS,Bigtable,為分散式科技的發展邁上了新的臺階。其中mapreduce就是一個為分散式服務的很好的處理思想,並應用到Hadoop中成為重要的分散式計算一環。由此加州大學伯克利分校的AMP研究室以mapreduce為出發點改進並建立了新一代大資料框架Spark,並於2013年成為Apache的頂級專案,一步一步走向成熟成為現在應用很廣的處理框架。
與Hadoop相比,Spark的最大特點是基於記憶體運算並引入DAG(有向無環圖)執行引擎。其中第一個是對Map reduce的重大改進,中間資料壓縮儲存到記憶體,運算時間會比磁碟低兩個數量級。第二個是對RDD的建模,描述了RDD之間的依賴關係。
Spark生態系統是以Spark core為核心提供計算框架,Spark streaming實時處理資料流,進行高吞吐高容錯的流式處理,可同時進行批處理和流處理,Spark SQL即席查詢,MLlib的機器學習和GraphX的影象處理,而且Spark的適應性很強,能讀取很多框架的原生資料(歸功於RDD)。
所以正式因為Spark的速度快(雖然沒有Storm他們快),容錯性高,可拓展性強,迅速取代了上一代大資料框架Hadoop而成為新的大資料處理框架。
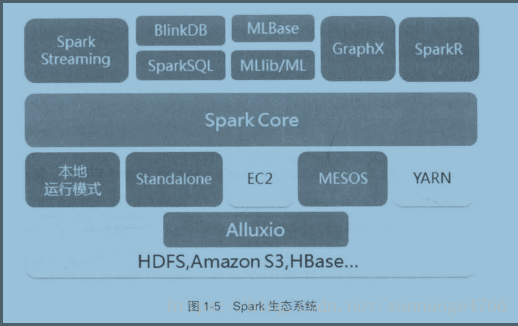
Spark應用Scala語言程式設計,其餘的各個組成部分與實際應用以後再慢慢學習。