
列表解析及生成器表示式的效率問題
阿新 • • 發佈:2019-01-07
列表解析(List Comprehensions),來自函式式的程式語言Haskell。是一個非常有用,簡單而且靈活的工具,可以動態地建立列表。自Python2.0,列表開始加入到Python中,裡面有lambda,map,filter等,使Python具備一個很重要的功能:函數語言程式設計。使Python語言有了個革命性的發展.也提供使用者一個強大工具,只用一行程式碼就可以建立包含特定內容的列表。
evaluation(延遲計算),所以它在記憶體使用上更有效。生成器表示式格式:
其基本格式:
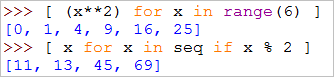
[expr
for item in iterable if
condition]
比如下面兩個例子,即可以用map, filter等來實現

也可以使用列表解析來實現
evaluation(延遲計算),所以它在記憶體使用上更有效。生成器表示式格式:
(expr for item in iterable if condition)
下面舉個例子來說明:
【測試檔案】
準備了四個檔案: 1.txt 2.txt 3.txt 4.txt
檔案大小分別為: 10M 100M 1G 10G
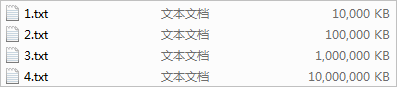
【測試內容】測試上述四個檔案所有非空字元的數目
【測試專案】列表解析
VS 生成器表示式
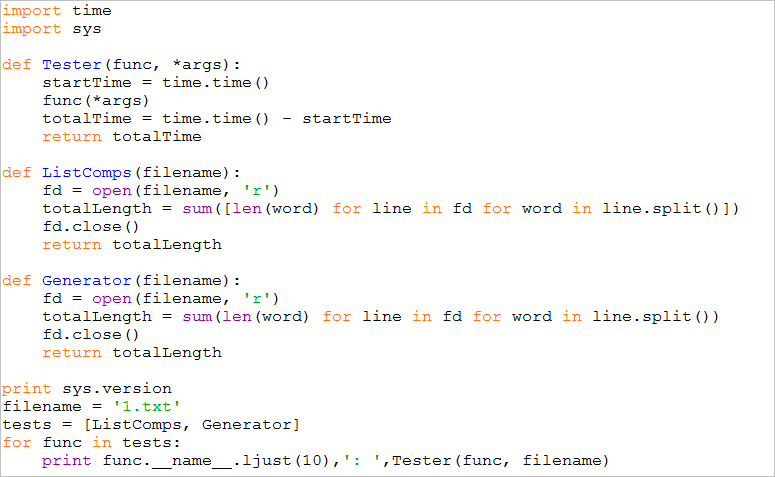
【測試指令碼】
【測試結果】
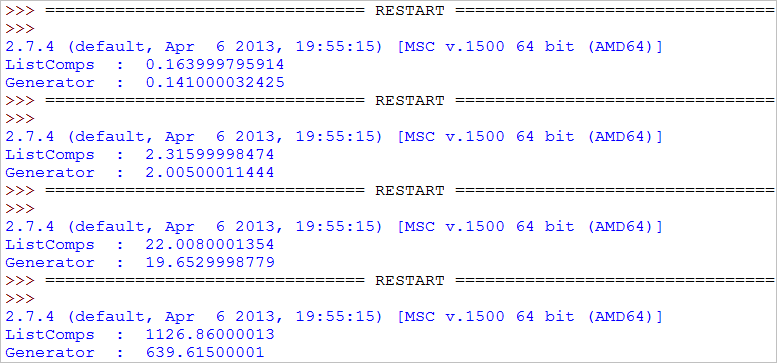
【測試分析】
1. 當資料比較小時,使用生成器表示式所耗時間比列表解析要稍微快些
2. 當資料比較大時,比如接近PC機記憶體的總量時,用後者速度要快的多!