6、java中的排序演算法
1、簡介
排序是將元素按著指定關鍵字的大小遞增或遞減進行資料的排列,排序可以提高查詢的效率
2、排序演算法的分類
排序演算法可大致分為四類七種,具體分類如下:
插入排序:直接插入排序、希爾排序
交換排序:氣泡排序、快速排序
選擇排序:直接選擇排序、堆排序
歸併排序
3、插入排序
演算法思想:每次將一個元素按著關鍵字大小插入到他前面已經排好序的子序列中,重複進行這個操作,直至插入所有資料。
3、1 直接插入排序
演算法描述:假設前i個元素構成的子序列是有序的,然後根據關鍵字大小順序將第i+1個元素a[i] 新增到已經排好序的子序列中,使得插入a[i]後的序列仍是一個有序序列,這樣當元素都插入序列時,則排序完成。
演算法實現:
/** * 直接插入排序 * @author chaizepeng */ private static void directInsertSort1(int[] array) { for (int i = 1; i < array.length; i++) { int temp = array[i];//拿到下一個需要插入的數值 for (int j = i-1; j >= 0; j--) {//遍歷已經排好序的集合 //將想要插入的元素和已經排好序的集合中的每一個進行比較 if (temp < array[j]) { array[j+1] = array[j]; }else { array[j+1] = temp; break; } } } } /** * 直接插入排序 * @author chaizepeng */ private static void directInsertSort2(int[] array) { for (int i = 1; i < array.length; i++) { int temp = array[i];//拿到下一個需要插入的數值 int j ; for (j = i-1; j >= 0 && temp < array[j]; j--) {//遍歷已經排好序的集合 //將想要插入的元素和已經排好序的集合中的每一個進行比較 array[j+1] = array[j]; } array[j+1] = temp; } }
演算法分析:

假設一個序列{1,2,3,4,5},使用直接插入排序時,每個個元素需要比較1次,移動兩次(現將第i個給temp,再將第temp給第i個)即可,則完成排序總需比較n-1次,移動2(n-1)次,時間複雜度是O(n)
再假設一個序列{5,4,3,2,1},使用直接插入排序時,第i個元素準備插入時,需要比較i-1次,移動2+(i-1)次(前一個元素往後移動一次,第i元素先給temp,然後temp再給第1個元素)也就是i+1次,所以n個元素總共許比較n(n-1)/2次,移動(n-1)(n+4)/2次,所以時間複雜度為O(n^2)
所以插入排序演算法的時間複雜度在O(n)到O(n^2)之間,其排序效率與比較次數和元素長度直接相關。
3、2 希爾排序
演算法描述:
程式碼實現:
/**
* 希爾排序
* @author chaizepeng
*/
private static void shellSort1(int[] array) {
int len = array.length;
int i,j,gap;
//步長每次除以2,使用步長來對陣列進行分組
//步長的直接意思就是,每隔len個元素則為同一組元素,步長在數值上等於組數
for (gap = len / 2 ; gap > 0 ; gap /= 2){
//因為每次都是除以2,所以當步長越小時,每組中的元素越多,越接近於有序
//這裡是遍歷根據步長分割的每一組
for (i = 0 ; i < gap ; i++){
//將每組中的元素進行排序,j是在i+gap開始的,因為每隔gap個數便是同一組資料
//這是遍歷每組中的每一個數據,組內資料進行比較,直接插入排序
//i+gap正好是獲取到陣列中的每一個數據
for (j = i + gap ; j < len ; j += gap){
if(array[j] < array[j - gap]){
int temp = array[j];
int k = j - gap;
while (k >= 0 && array[k] > temp){
array[k + gap] = array[k];
k -= gap;
}
array[k + gap] = temp;
}
}
}
}
}
/**
* 希爾排序
* @param array
*/
private static void shellSort2(int[] array){
int len = array.length;
int j , gap;
for (gap = len / 2 ; gap > 0 ; gap /= 2){
for (j = gap ; j < len ; j++){
if (array[j] < array[j - gap]){
int temp = array[j];
int k = j - gap;
while (k >= 0 && array[k] > temp){
array[k + gap] = array[k];
k -= gap;
}
array[k + gap] = temp;
}
}
}
}
/**
* 希爾排序
* @param array
*/
private static void shellSort3(int[] array) {
int i,j,gap;
int len = array.length;
for (gap = len / 2 ; gap > 0 ; gap /= 2){
for (i = gap ; i < len ; i++){
for (j = i - gap ; j>= 0 && array[j] > array[j+gap] ; j -= gap){
int temp = array[j];
array[j] = array[j+gap];
array[j+gap] = temp;
}
}
}
}演算法分析:

因為根據之前對直接插入排序的分析可以知道直接插入排序演算法的效率與比較次數和元素長度直接相關,可以看出希爾排序是對直接插入排序演算法做了優化,針對的就是比較次數和元素的長度,希爾排序講究先分組排序,這樣就見效了移動的次數,隨著元素長度的增加,序列趨於有序,減少了比較的次數,降低了時間複雜度。另外,希爾排序的時間複雜度是O(n*(logn)^2)。
排序演算法的穩定性:是對關鍵字相同的元素排序效能的描述,當兩個元素A,B相等,排序之前A在B前邊,如果排完排完序之後,A仍然在B前邊,則說明排序演算法是穩定的。自我感覺分析一個演算法穩定還是不穩定是可行的,但是如果說一個演算法是穩定還是不穩定的應該不準確吧?對於穩定性而言是不是就是對臨界元素的一種處理方式而已呢?不必糾結。
4、交換排序
4、1 氣泡排序
演算法描述:假設按著升序排序,就是從第一個元素開始比較相鄰兩個元素的值,如果前邊的比後邊的大,則交換兩個值得位置,然後繼續往後進行比較交換操作,一趟下來使得序列中最大的數在最後邊,假設長度是n,則第一趟將最大的數放在第n個位置上,然後再進行第二趟,第二趟下來之後保證除第n個數之外最大數在第n-1的位置,然後繼續下一趟,重複上邊操作,直到不需要繼續元素交換了便排序結束了。
演算法實現:
/**
* 氣泡排序
* @author chaizepeng
*/
private static void bubbleSort1(int[] array) {
int len = array.length;
//控制比較的長度,最長len-1
for (int i = len-1; i > 0; i--) {
//第二層迴圈控制比較大小和交換位置
for (int j = 0; j < i; j++) {
if (array[j] > array[j+1]) {//如果前一個數比後一個數大,則交換位置
int temp = array[j];
array[j] = array[j+1];
array[j+1] = temp;
}
}
System.out.println("共有"+len+"個元素,這是第"+(len - i)+"趟");
}
}
/**
* 氣泡排序
* @author chaizepeng
*/
private static void bubbleSort2(int[] array) {
int len = array.length;
//外層迴圈控制遍歷趟數,最多迴圈len-1次
for (int i = 0; i < len-1; i++) {
for (int j = 0; j < len - 1 - i; j++) {
//第二層迴圈控制比較大小和交換位置
if (array[j] > array[j+1]) {//如果前一個數比後一個數大,則交換位置
int temp = array[j];
array[j] = array[j+1];
array[j+1] = temp;
}
}
System.out.println("共有"+len+"個元素,這是第"+(i+1)+"趟");
}
}
/**
* 氣泡排序使用新增標記的方式進行優化,序列越接近有序,效率越高
* @author chaizepeng
*/
private static void bubbleSort3(int[] array) {
int len = array.length;
//標記
boolean flag;
//外層迴圈控制遍歷趟數,最多迴圈len-1次
for (int i = 0; i < len-1; i++) {
flag = true;
for (int j = 0; j < len - 1 - i; j++) {
//第二層迴圈控制比較大小和交換位置
if (array[j] > array[j+1]) {//如果前一個數比後一個數大,則交換位置
int temp = array[j];
array[j] = array[j+1];
array[j+1] = temp;
flag = false;
}
}
System.out.println("共有"+len+"個元素,這是第"+(i+1)+"趟");
//如果沒有進行資料交換,也就是flag==true
if (flag) {
break;//不再繼續下一趟
}
}
}演算法分析:氣泡排序記住一點,只要沒有元素交換了,則排序完成。

例如序列{1,2,3,4,5},第一趟比較4次,沒有元素移動,時間複雜度O(n)
再例如序列{5,4,3,2,1},第一趟比較4次,移動12次,時間複雜度為O(n^2)
所以氣泡排序演算法的時間複雜度在O(n)到O(n^2)之間,其時間複雜度與序列是否有序有直接關係,並且演算法是穩定的。此演算法每次都藉助了一個臨時的中間元素,用來交換兩個數。
4、2 快速排序
演算法描述:快速排序是對氣泡排序的優化,快速排序第一趟就根據某個元素將序列分成兩部分,一部分中所有資料比此元素小,另一部分的所有數比此元素大或等於此元素;然後再對這兩部分分別進行分割,整個過程可以遞迴進行,直到序列有序。
演算法實現:
/**
* 看圖理解程式碼,一下子就全明白了
* @author chaizepeng
*/
private static void quickSort1(int[] array) {
int i = 0;
int j = array.length - 1;
quickSort(i,j,array);
}
/**
* 遞迴實現快排演算法
* @author chaizepeng
*/
private static void quickSort(int i, int j, int[] array) {
int left = i;
int right = j;
int key = array[i];
while (i < j) {//只要不相等就迴圈比較,交換操作
//從右往左遍歷
while(i < j && array[j] >= key) {
j--;
}
if (array[j] < key) {//每次交換的都是一個小於key的元素和key所在位置上的值,也就是key值
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}
//從左往右遍歷
while(i < j && array[i] <= key) {
i++;
}
//交換i處和j處的資料
if (array[i] > key) {//每次交換的都是一個大於key的元素和key所在位置上的值,也就是key值
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}
}
//遞迴使用
if (i > left) {
quickSort(0, i, array);
}
if (j < right) {
quickSort(j + 1, array.length-1, array);
}
}演算法分析:

這裡寫的快排是不穩定,快速排序演算法效率受標記值(基準值)的影響,假如每次選擇的基準值都是最值的話,那麼就會導致被分割的子序列是不平衡的(一個裡邊就一個元素,另一個裡邊是其餘的n-1個元素),則需要比較的趟數就會增加,導致演算法效率低下,快排的時間複雜度在O(nlogn)到O(n^2)之間。所以想要提高快排的效率就要保證每次找的基準值是當前序列的中間值。
快排的空間複雜度在O(logn)到O(n)之間
5、選擇排序
5、1 直接選擇排序
演算法描述:以升序為例:從第一個元素開始,依次比較序列中的元素,將最小的元素放在第一個位置;接著在第二個元素開始,依次比較序列中的值,將最小的元素放在第二個位置,依次類推,直到排序結束。
演算法實現:
/**
* 以升序為例:從第一個元素開始,依次比較序列中的元素,將最小的元素放在第一個位置;接著在第二個元素開始,依次比較序列中的值,將最小的元素放在第二個位置,依次類推,直到排序結束
* 直接選擇排序
* @author chaizepeng
*/
private static void straightSelectSort(int[] array) {
//控制比較的趟數
for (int i = 0; i < array.length - 1; i++) {
int minFlag = i;//記錄一下最小值所在的下標
for (int j = i+1; j < array.length; j++) {//控制從何處開始比較,比較到何處結束
if (array[j] < array[minFlag]) {//比較當前值和之前記錄的最小下標對應的值
minFlag = j;
}
}
//將最小值放在最前邊
if (minFlag != i) {
int temp = array[minFlag];//最小值
array[minFlag] = array[i];//將當前值賦給最小值所在的位置
array[i] = temp;//當前位置放最小值
}
}
}演算法分析:

直接選擇排序,最多需要n-1趟,並且每一趟都需進行n-i此的比較,所以時間複雜度是O(n^2),並且直接選擇排序是不穩定的演算法。自我感覺這是最容易理解和實現的排序演算法。
5、2 堆排序
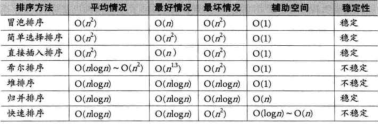
演算法描述:堆排序是對直接選擇排序的一種優化,直接選擇排序演算法在每一趟比較兩個數大小時, 只是比較大小沒有做任何操作, 而堆排序針對此處做了優化,他在比較的同時也將其他的元素(不是最小的元素)做了相應調整。堆排序是先使用待排序的序列構建一個堆,這裡用大頂堆來實現,然後根據大頂堆的特點,將根結點元素放到最後(這裡實現升序排序),然後將剩下的元素再構成一個大頂堆,依次進行,直到堆的長度為1結束排序。
說一下什麼是堆,堆是一種資料結構,首先是一個完全二叉樹(有右子樹必有左子樹的二叉樹),另外,這個完全二叉樹的各個結點上的數值從根結點到每一個葉子結點都會有一種規律:
父結點一定大於或者等於其孩子結點,這樣的稱為大頂堆
父結點一定小於或者等於其孩子結點,這樣的稱為小頂堆
演算法實現:
/**
*
* 堆排序:是對直接選擇排序的一種優化,直接選擇排序演算法在每一趟比較兩個數大小時, 只是比較大小沒有做任何操作,
* 而堆排序針對此處做了優化,他在比較的同時也將其他的元素(不是最小的元素)做了相應調整。堆排序是先使用待排序的序列構建一個堆,這裡用大頂堆來實現,
* 然後根據大頂堆的特點,將根結點元素放到最後(這裡實現升序排序),然後將剩下的元素再構成一個大頂堆,依次進行,直到堆的長度為1結束排序。
* 儲存堆時的資料下標在1開始,而不是0,因為可以直接使用二叉樹的性質進行堆的構建
* @author chaizepeng
*/
private static void heapSort(int[] array) {
//這裡已經-1了
int len = array.length-1;
//用待排序的序列構建一個大頂堆,因為排序是藉助堆結構進行的,這裡相當於初始化堆
//儲存序列的陣列下標必須在1開始,根據平衡二叉樹的順序儲存特性可以知道,len/2之後的是葉子節點,而len/2以及它前邊的結點是存在子結點的
//依次遍歷每一個存在子結點的結點,然後進行判斷、交換結點,使得構建一個堆
//1、初始化最大堆
for (int i = len/2; i > 0; i--) {
heapAdjust(array, i, len);
}
for (int i = 1; i < array.length; i++) {
System.out.print(array[i]+" ");
}
System.out.println("--------------------------");
//2、交換根結點和最後一個結點位置,將剩下的重新構建一個堆
for (int i = len; i > 1; i--) {
//交換元素
int temp = array[i];
array[i] = array[1];
array[1] = temp;
heapAdjust(array, 1, i-1);
}
}
/**
* 構建大頂堆
* 什麼是堆:
* 堆是一種資料結構,首先是一個完全二叉樹(有右子樹必有左子樹的二叉樹),另外,這個完全二叉樹的各個結點上的數值從根結點到每一個葉子結點都會有一種規律:
* 父結點一定大於或者等於其孩子結點,這樣的稱為大頂堆
* 父結點一定小於或者等於其孩子結點,這樣的稱為小頂堆
* @author chaizepeng
*/
private static void heapAdjust(int[] array, int i, int len) {
//遍歷當前操作結點對應的子結點
int j ;
for (j = i * 2; j <= len ; j *= 2) {
//記錄一下當前操作的結點
int temp = array[i];
//子結點的左孩子和右孩子進行比較
//這裡為什麼要比較一下呢?假設子結點比父節點大,則需要上浮子結點,但是有可能有左右兩個結點,這裡比較一下,確定哪一個結點上浮
//此處j < len 必須要加
if (j < len && array[j] < array[j+1]) {
++j;
}
//如果當前操作的結點 > 子結點 ,不操作
if (temp >= array[j]) {
break;
}
//交換父子結點的值
array[i] = array[j];
array[j] = temp;
//將需要判斷的元素下標改成下降的元素下標,用於與其子節點進行判斷
i = j;
}
}演算法分析:
堆排序的時間複雜度是O(n㏒n),演算法是不穩定的。堆排序演算法充分利用了完全二叉樹的性質,效率高,比較複雜,不容易理解,比較適合元素多的序列排序使用。
6、歸併排序
演算法描述:歸併排序使用的是演算法設計中分治的思想,分而治之,然後合併,將小的子序列進行排序,然後慢慢的將有序的子序列進行合併,最終使得整個序列有序,這裡介紹的是二路歸併演算法,也就是每次只將兩個子序列進行歸併。具體操作是這樣的,每次是將兩個序列A、B進行合併,這裡假設這兩個序列是有序的,首先初始一個長度為兩個序列長度之和的容器,然後宣告兩個標記位i,j,i指向序列A的第一個元素,j指向序列B的第一個元素,然後比較兩個陣列中標記位上數的大小,哪一個小就將標記位上的數放到初始的容器中,然後將標記位指向下一個元素,然後直至其中一個序列中的元素已被移動完畢,則將另一個序列中的元素複製到容器中,排序完畢,這只是核心的兩個序列歸併邏輯。
演算法實現:
public static void main(String[] args) {
int []array = {24, 27 ,41, 44, 19, 47 ,50 ,5,65, 93 ,94 };
for (int i = 0; i < array.length; i++) {
System.out.print(array[i]+" ");
}
System.out.println();
System.out.println("-----------------------------");
//從第一個元素開始,第一次歸併時,每一個歸併的序列長度是1(預設每一個序列長度為1的序列是有序的)
mergeSort(array,1);
for (int i = 0; i < array.length; i++) {
System.out.print(array[i]+" ");
}
}
/**
*
* @author chaizepeng
*
* @param array 排序總序列
* @param len 要歸併的序列的長度
*/
private static void mergeSort(int[] array ,int len) {
//序列{6,5,8,4,7,9,2,1,4}要進行歸併,第一次歸併時需要將相鄰的兩個元素進行排序歸併,分組如下
//6,5,8,4,7,9,2,1,4
//此時,需要比較兩個相鄰的元素,所以,就需要進行分組和排序
//6,5 8,4 7,9 2,1 4
//需要先判斷一下要分幾個組
int count = array.length / (len * 2);
//判斷一下count的值,如果=0的話,則說明len*2已經大於序列總長度,這時序列已經排序完成,結束即可
if (count == 0) {
return;
}
//然後依次歸併
for (int i = 0; i < count; i++) {
//i*len 第一個序列的第一個元素位置
//len 有序序列長度
//(2+i)*len 第二個序列的最後一個元素位置(不包括)
merge(array,i*len*2,(i+1)*len*2,len);
}
//在這裡判斷一下是否歸併正好兩兩對應,如果有剩下的,則也需要歸併一下(這裡是拿剩下的序列組和它的前一組進行歸併操作)
int rem = array.length % (len * 2);
if (rem != 0) {
merge(array, array.length-rem-len, array.length,len);
}
//進行完一次歸併後,繼續下一次操作
//子序列長度為len的已經歸併完成,下一次使用len*2作為長度繼續歸併
mergeSort(array,len * 2);
}
/**
* 一次歸併過程
* @author chaizepeng
*
* @param array
* @param leftBegin
* @param rightEnd
* @param len
*/
private static void merge(int[] array, int leftBegin, int rightEnd,int len) {
//標記位,用於複製陣列用
int flag = leftBegin;
//用一個數組來存一下需要合併的序列
int []temp = new int[rightEnd - leftBegin];
int leftEnd = leftBegin + len;
int rightBegin =leftEnd;//右邊序列開始的位置
//標記temp的下標
int j = 0;
//比較兩個序列中的元素大小,進行填充
while (leftBegin < leftEnd && rightBegin < rightEnd) {
if (array[leftBegin] > array[rightBegin]) {
temp[j++] = array[rightBegin++];
}else {
temp[j++] = array[leftBegin++];
}
}
//判斷一下前後兩個被比較的序列那個還有元素剩餘,則直接複製到temp中
while(leftBegin < leftEnd) {
temp[j++] = array[leftBegin++];
}
while(rightBegin < rightEnd) {
temp[j++] = array[rightBegin++];
}
//將temp中的資料填到array中
for (int k = 0; k < temp.length; k++) {
array[flag+k] = temp[k];
}
}演算法分析:
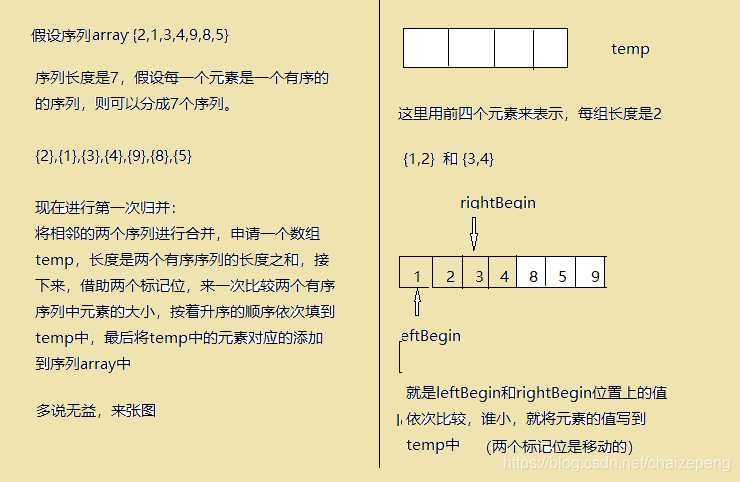
歸併演算法的時間複雜度是O(n㏒n),演算法是穩定的,效率較高。
7、效能比較
沒有絕對好的演算法,要根據具體的情況來分析那個演算法更好,平均情況下快排(個人比較喜歡快排)、堆排序和歸併排序效率高;如果排序的序列基本有序,那麼氣泡排序和直接插入排序效率比較高;如果序列基本逆序,則堆排序和歸併排序效率高;在空間複雜度上看,堆排序是最好的。但是快排是最常用的。
附加一張演算法指標對比表: