
CNN+LSTM深度學習文字檢測
最近看到論文Detecting Text in Natural Image with Connectionist Text Proposal Network
這是作者的主頁
論文的閱讀可以看下這邊部落格:
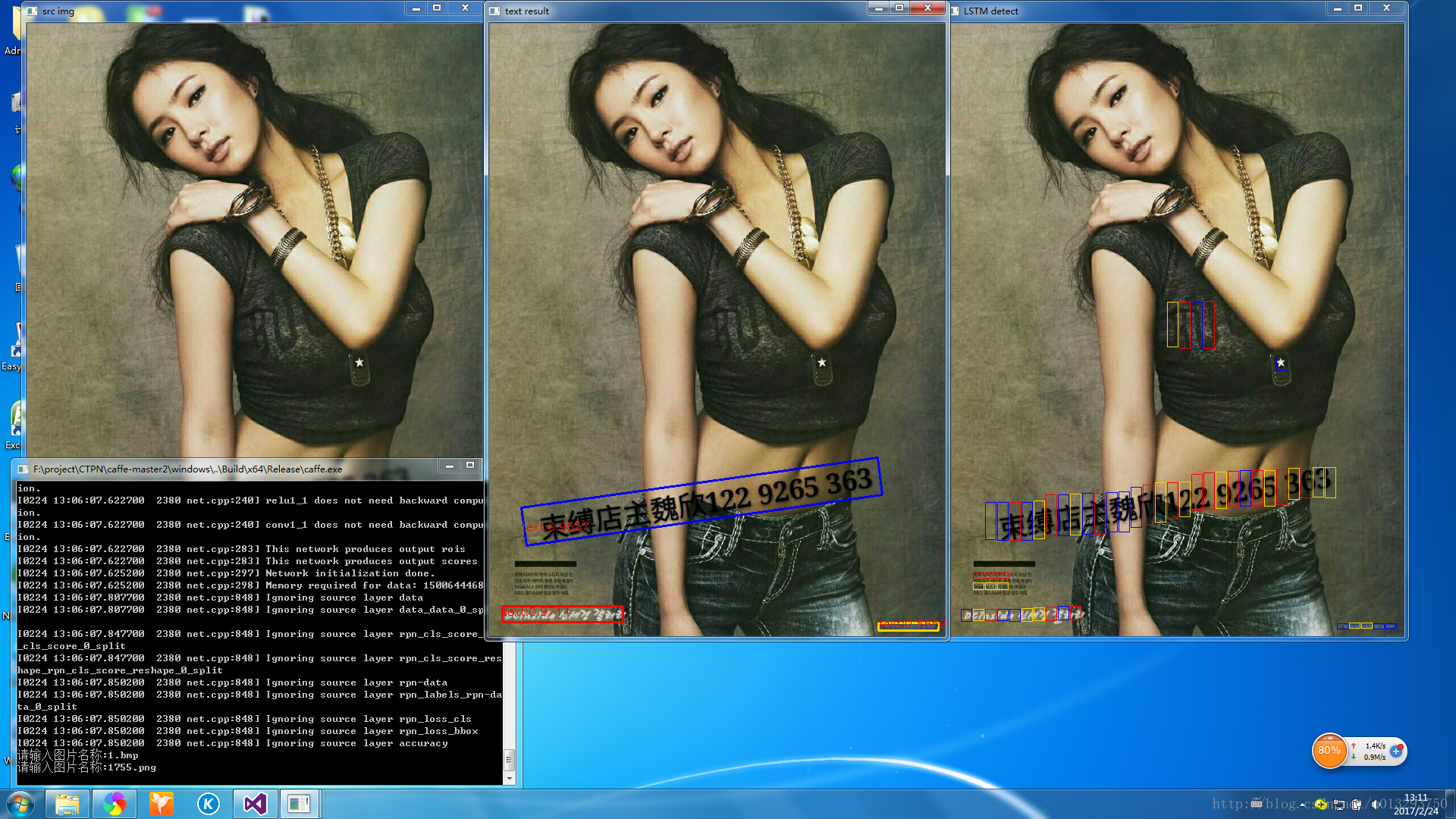
對文字的檢測效果挺不錯的,就把它移到了windows平臺上。在我的筆記本上cpu模式下大概要10s,gpu模式大概800ms吧。先看下論文執行的效果。
—-

整體效果還是挺好的,作者提供的程式碼沒有對傾斜進行處理,我對檢測完的結果稍微做了傾斜角度判斷。
網路結構
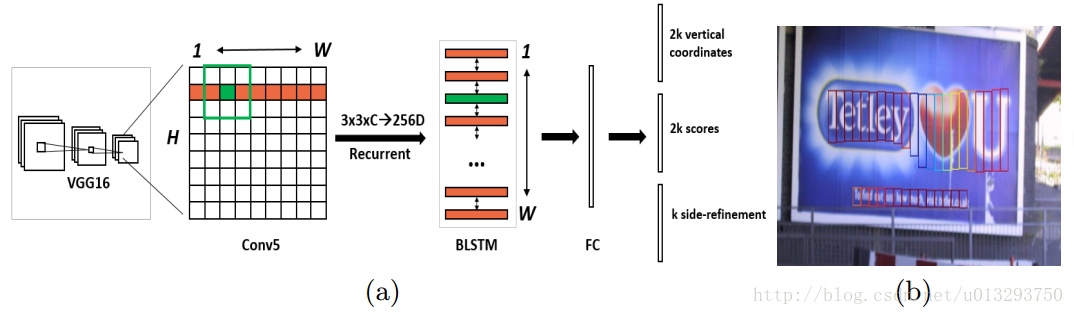
這是作者論文提供的圖片。其中side-refinement並沒有提供相應的程式碼,就不做分析了。
1: 輸入為3*600(h)*900(w),首先vgg-16提取特徵,到conv5-3時,大小為512*38*57。
2: im2col層 512*38*57 ->4608 * 38 * 57 其中4608為(512*9 (3*3卷積展開))
3 : 而後的lstm層 57*38*4608 ->57*38*128 reverse-lstm同樣得到的是57*38*128。(雙向lstm沒有去研 究,但我個人理解應該是左邊的結果對右邊會產生影響,同樣右邊也會對左邊產生影響,有空再去看)
merge後得到了最終lstm_output的結果 256* 38 * 57
4: fc層 得到512*38*57 fc不再展開,就是一個256*512的矩陣引數
5:rpn_cls_score層得到置信度 512*38*57 ->20*38*57
其中20 = 10 * 2 其中10為10個尺度 同樣為512*20的引數,kernel_size為1的卷積層
6:rpn_bbox_pre層 得到偏移 512*38*57 ->20*38*57。同樣是十個尺度 2 * 10 * 38 * 57
因為38*57每個點每個scale的固定位置我們是知道的。而它與真實位置的偏移只需兩個值便可以得到。
假設固定位置中點( Cx,Cy) 。 高度Ch。實際位置中點(x,y) 高度h
則log(h/Ch)作為一個值
(y-Cy) / Ch作為一個值
20 * 38 * 57 便是10個尺度下得到的這兩個值。有了這兩個值,我們便能知道真實的文字框位置了。
對檢測結果的處理
檢測完得到很多個寬度固定(16)的矩形框 conf>0.7

對得到的矩形框進行nms處理

按照作者提供的條件規則,對小矩形框進行連線,得到文字行
