
k-中心點演算法(k-medoids)及Matlab程式碼實現
k-中心點演算法(k-medoids)及Matlab程式碼
1. 提出:
k-means演算法是每次選擇簇的均值作為新的中心點,迭代直到簇中心不再變化(趨於穩定)。其缺點是對離群點特別敏感,因為一個很大的極端值物件會扭曲資料分佈,使簇均值嚴重偏離;於是我們考慮新的簇中心不用均值表示而是選擇簇內的某個物件,只要使總的代價降低就行。。
2. 優化後的演算法:
PAM(圍繞中心點的劃分),具有代表性的k-medoids演算法。
演算法思想: 迭代選出簇中位置最中心的物件,試圖將N個物件給出k個劃分。
具體:
最初隨機選擇k個物件作為中心點,並代表初始簇,然後根據歐氏距離劃分其餘所有物件到各個中心點所代表的簇,得到初始簇劃分。
該演算法反覆利用資料D中所有非代表物件來替換當前代表物件,試圖找出更好的中心點,以改進聚類質量。 中心點也叫代表物件,其他物件叫非代表物件。
在每次迭代中,所有可能的物件都被分析,每一對替換中的一個物件是中心點,而另一個是非代表物件。如果一個當前的中心點被一個非代表物件所替換,代價函式將計算平方誤差值所產生的差別;替換的總代價是所有非中心物件去替換所產生的代價之和。
如果總代價為負值,則實際的平方誤差將會減少,則代表物件Oi可被非代表物件Oh替換。
中心點的定義:簇中某點的平均差異性在這一簇中所有點中最小。
3. 演算法描述:
輸入:
- k:簇的數目;
- N:包含N個物件的資料;
輸出:k個簇,使得所有物件與其距離最近的中心點的相異度總和
- 初始化:隨機選擇N個點中的k個點作為初始中心點;
- 將其餘各點根據歐式距離劃分到這k個類別中;
- 當損失值減少時:
對於每個中心點o,對於每個非中心點m;
a.)交換o和m,重新計算損失(損失值為,所有點到中心點的距離和);
b.)如果總的損失增加則不進行交換;
另外一種解釋:
1. 任選k個物件作為初始簇中心;
2. 劃分其餘物件給離它最近的中心點所表示的簇;
3. 選擇一個未被選擇的中心點Oi;
4. 選擇一個未被選擇的非中心點Oh;
5. 計算Oh替換Oi所產生的總代價並記錄在S中;
6. Utill 所有非中心點都被選擇過;
7. Utill 所有中心點都被選擇過;
8. if 在S中的所有替換所產生的總代價有負值存在,then 找出並用該非中心點替換對應的中心點,形成一個新的k箇中心點的集合;
9. Utill 沒有再發生簇的重新分配,即所有的S都大於0.
總的來說:與k均值演算法一樣,初始代表物件任意選取,反覆用一個非代表物件替換一個代表物件,試圖找出更好的中心點,以改進聚類質量。一箇中心點物件被可以產生誤差平方和減少的物件替換,再一次迭代中產生的最佳物件集合成為下次迭代中心點。
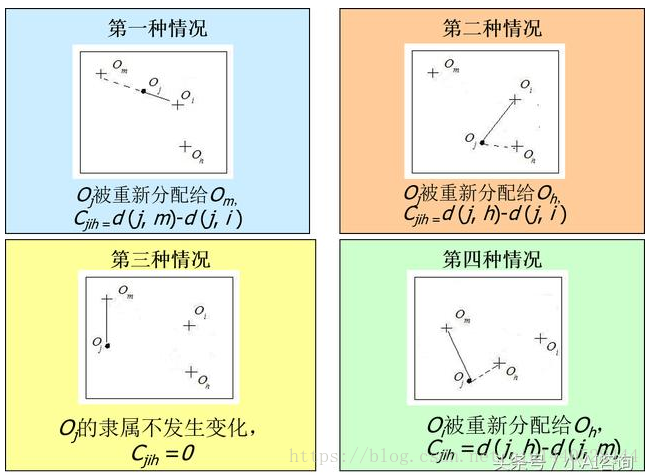
為判定一個非代表物件Oh是否是當前一個代表物件Oi的好的替換,對每個非中心點物件Oj,有以下四種情況:
第一種情況:Oj當前隸屬於中心點物件Oi。如果Oi被Oh所代替作為中心點,且Oj離某個中心點Om最近,i≠m,那麼Oj被重新分配給Om。
第二種情況:Oj當前隸屬於中心點物件Oi。如果Oi被Oh所代替作為中心點,且Oj離Oh最近,那麼Oj被重新分配給Oh。
第三種情況:Oj當前隸屬於中心點Om,m≠i。如果Oi被Oh代替作為中心點,而Oj依然離Om最近,那麼物件的隸屬不發生變化。
第四種情況:Oj當前隸屬於中心點Om,m≠i。如果Oi被Oh代替作為一箇中心點,且Oj離Oh最近,那麼Oi被重新分配給Oh。
每當重新分配發生時,絕對誤差E的差會對代價函式有影響。因此,如果一個當前的代表物件被非代表物件所替換時,則代價函式就計算絕對誤差值的差。交換的總代價是所有非代表物件所產生的代價之和。如果總代價為負,則實際的絕對誤差和會減少,Oi可以被Oh所替換作為新中心點。如果代價為正,則本次迭代無變化。
總代價定義如下:
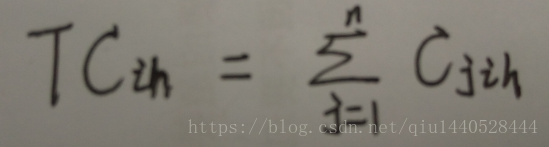
其中,TCih表示中心點Oi被非中心點Oh替換後產生的總代價。Cjih表示,Oj在Oi被Oh替換後產生的代價。下面將介紹上述四種情況中代價函式的計算公式,其中引用到的符號有:Oi和Om是兩個原中心點,Oh將替換Oi作為新的中心點。
代價函式計算圖示:
Matlab程式碼:
k_medoids.m檔案
clc;
clear;
%讀取資料檔案,生成點矩陣
fileID = fopen('E:\MySoftware\matlabWorks\textKMediods\sample.txt');
C=textscan(fileID,'%f %f'); %textscan函式讀取資料
fclose(fileID); %關閉一個開啟的fileID的檔案
%顯示陣列結果
%celldisp(C);
%將cell型別轉換為矩陣型別,這裡只假設原資料為二維屬性,且是二維的座標點
CC_init=cat(2,C{1},C{2});%用來儲存初始載入的值
CC=CC_init; %cat函式用於連線兩個矩陣或陣列
%獲得物件的數量
num=length(C{1});
%顯示初始分佈圖
grid on;%顯示錶格
scatter(C{1},C{2},'filled'); %filled為實心圓,該函式可以把C中所有座標的點都畫出來。
%%設定任意k個簇
k=3;
%臨時存放k箇中心點的陣列
C_temp=zeros(k,2);
%判斷所設定的k值是否小於物件的數量
if k<num
%產生隨機的k個整數
randC=randperm(num);
randC=randC(1:k);
%從原陣列中提出這三個點
for i=1:k
C_temp(i,:)=CC(randC(1,i),:);
end
%將原陣列中的這三個點清空
for j=1:k
CC(randC(1,j),:)=zeros(1,2);
end
idZero=find(CC(:,1)==0);
%刪除為零的行
[i1,j1]=find(CC==0);
row=unique(i1);
CC(row,:)=[];
%分配k個二維陣列,用來存放聚類點
%分配行為k的儲存單元
cluster=cell(k,1,1);
%將剔除的三個點加入到對應的三個儲存單元,每個單元的第一行置為0,為了儲存相對應的簇中心
for m=1:k
cluster{m}=C_temp(m,:);
end
%計算其他點到這k個點的距離,然後分配這些點,第一次遍歷
for i=1:num-k
%分別計算到三個點的距離
minValue=1000000;%最小值,要根據實際情況設定該值
minNum=-1;%最小值序號
for j=1:k
if minValue>sqrt((CC(i,1)-C_temp(j,1))*(CC(i,1)-C_temp(j,1))+(CC(i,2)-C_temp(j,2))*(CC(i,2)-C_temp(j,2)))
minValue=sqrt((CC(i,1)-C_temp(j,1))*(CC(i,1)-C_temp(j,1))+(CC(i,2)-C_temp(j,2))*(CC(i,2)-C_temp(j,2)));
minNum=j;
end
end
cluster{minNum}=cat(1,cluster{minNum},CC(i,:));
end
%隨機選擇p點
flag=1;
count=0;
while flag==1
randC=randperm(num-k);
randC=randC(1:1);
o_random=CC(randC,:);
%找出該隨機點所在的簇
recordN=0;
for i=1:k
for j=1:size(cluster{i},1)
cc=cluster{i}(j,:);
cc=cc-o_random;
if cc==0
recordN=i;
break;
end
end
end
%將選擇的隨機點從點集中刪除
CC(randC,:)=[];
%計算替換代價
o=cluster{recordN}(1,:);
o_rand_sum=0;
o_sum=0;
for i=1:length(CC)
o_rand_sum=o_rand_sum+sqrt((CC(i,1)-o_random(1,1))*(CC(i,1)-o_random(1,1))+(CC(i,2)-o_random(1,2))*(CC(i,2)-o_random(1,2)));
o_sum=o_sum+sqrt((CC(i,1)-o(1,1))*(CC(i,1)-o(1,1))+(CC(i,2)-o(1,2))*(CC(i,2)-o(1,2)));
end
%如果隨機選擇的點的代價小於原始代表點的代價,則替換該代表點,然後重新聚類
if o_rand_sum<o_sum
cluster{recordN}(1,:)=o_random;
%將代表點放入物件集
CC=cat(1,CC,o);
%對所有物件重新進行聚類
%將cluster除第一行之外的資料全部清空
for i=1:k
c=cluster{i}(1,:);
cluster{i}=[];
cluster{i}=c;
end
%重新聚類
for i=1:num-k
%分別計算到三個點的距離
minValue=1000000;%最小值,要根據實際情況設定該值
minNum=-1;%最小值序號
for j=1:k
if minValue>sqrt((CC(i,1)-C_temp(j,1))*(CC(i,1)-C_temp(j,1))+(CC(i,2)-C_temp(j,2))*(CC(i,2)-C_temp(j,2)))
minValue=sqrt((CC(i,1)-C_temp(j,1))*(CC(i,1)-C_temp(j,1))+(CC(i,2)-C_temp(j,2))*(CC(i,2)-C_temp(j,2)));
minNum=j;
end
end
cluster{minNum}=cat(1,cluster{minNum},CC(i,:));
end
else
%將隨機點重新放入物件集
CC=cat(1,CC,o_random);
%終止迴圈
flag=0;
end
count=count+1;
end
%繪製聚類結果
for i=1:k
scatter(cluster{i}(:,1),cluster{i}(:,2),'filled');
hold on
grid on;%顯示錶格
end
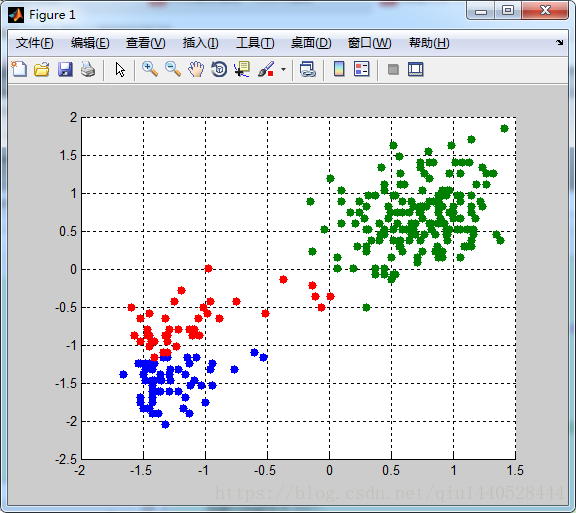
end 執行結果如下:
當K=3時:
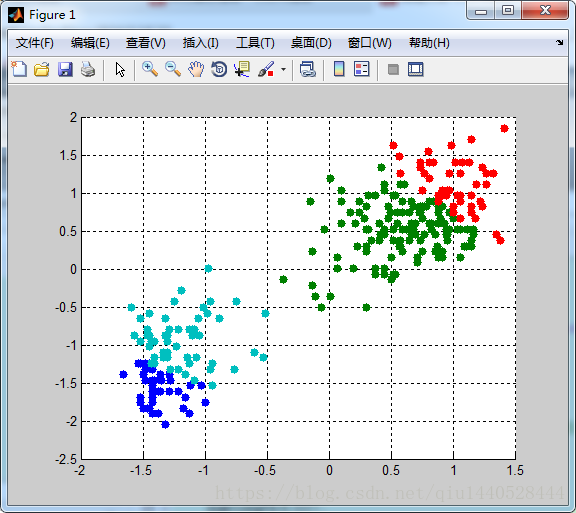
當K=4時:
參考文獻及例子:
歡迎掃描提問碼交流
CSDN程式碼下載地址: