
Excel圖表—標準正態分佈概率分佈圖(概率密度函式圖及累積概率分佈圖)的繪製
看似很簡單的一張Excel圖表,實際上也花了10多分鐘。這對於已經習慣了Spotfire這種資料視覺化軟體的我而言是不能接受的。
不過,功夫不負有心人,總算是畫出了教科書上的效果。
以下是一點小創新,如果提高資料粒度(資料粒度能夠滿足業務要求),有些問題的答案將一目瞭然。
比如,
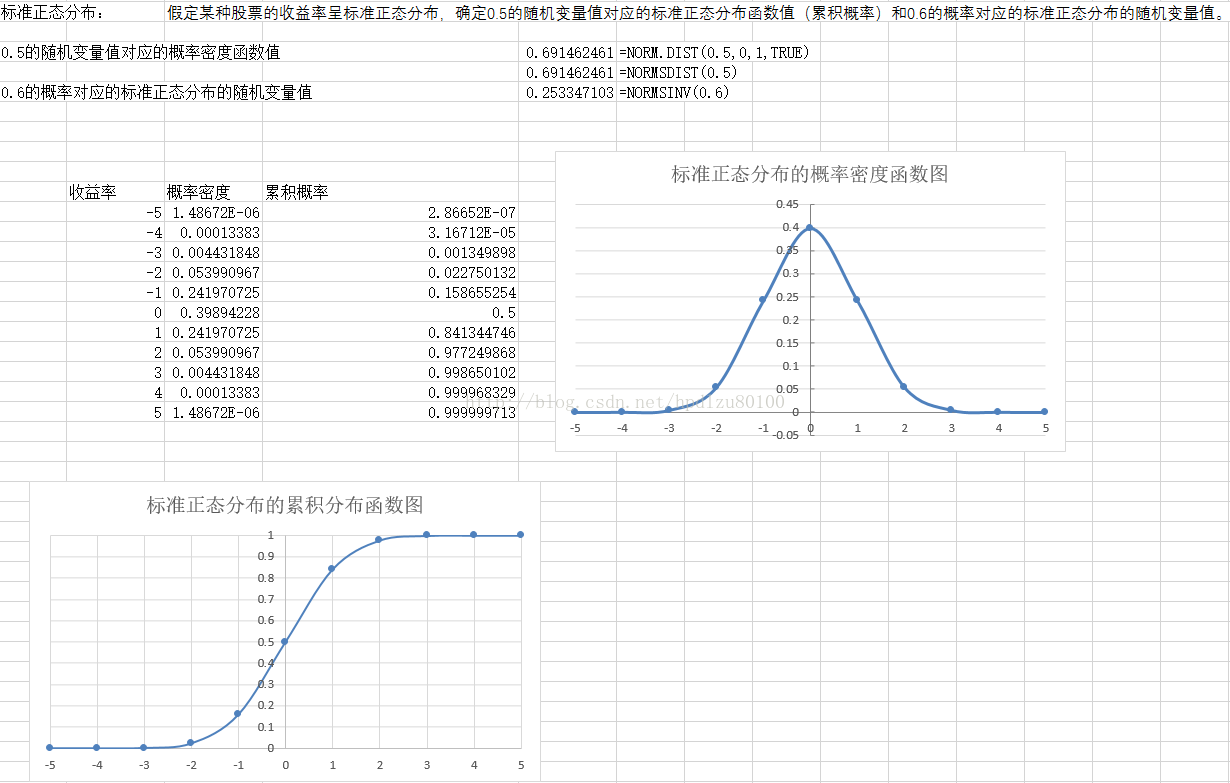
問題:假定某種股票的收益率呈標準正態分佈,確定0.5的隨機變數值對應的標準正態分佈函式值(累積概率)和0.6的累積概率對應的標準正態分佈的隨機變數值。
解答1(計演算法):
0.5的隨機變數值對應的標準正態分佈函式值=NORMDIST(0.5)=0.691
0.6的概率對應的標準正態分佈的隨機變數值= NORMSINV(0.6)=0.25
解答2:使用速查圖,在橫座標軸上找到隨機變數0.5,可立即對應的累積函式值為0.6915

相關推薦
Excel圖表—標準正態分佈概率分佈圖(概率密度函式圖及累積概率分佈圖)的繪製
看似很簡單的一張Excel圖表,實際上也花了10多分鐘。這對於已經習慣了Spotfire這種資料視覺化軟體的我而言是不能接受的。 不過,功夫不負有心人,總算是畫出了教科書上的效果。 以下是一點小創新,如果提高資料粒度(資料粒度能夠滿足業務要求),有些問題的答案將一目瞭然
標準正態分佈隨機變數的倒數的分佈
背景 看到有人在問這個問題,拿來算算。 自從有了CSDN-MarkDown之後,寫部落格舒服多了,尤其是數學公式部分。 原理 推薦的參考書是: Schaum’s outline of Probability and Statistics, 3rd
標準正態分佈的積分怎麼求?
標準正態分佈的積分求解如下: x=rcosθ y=rsinθ 是二重積分極座標代換 而dxdy,rdrdθ是積分分別在直角座標系和極座標系的面積元素 當重積分從直角座標向極座標轉換的時候要乘
【Scikit-learn】【模型預處理-2-資料整理】資料標準化調整:把資料調整為標準正態分佈
1.標準正態分佈概念詳細的概念可以www.baidu.com,或者看以前寫的文章。標準正態分佈又稱為u分佈,是以0為均數、以1為標準差的正態分佈,記為N(0,1)。如下圖,綠色綠色就代表了標準正態分佈:2.資料標準化調整2.1簡介許多機器學習演算法在具有不同範圍特徵的資料中呈
標準正態分佈函式表的程式實現
現在的很多程式中要想實現查詢正態分佈函式表,將幾百條資料用陣列存放起來 再在程式中查詢是非常笨拙的方法,現在提供一種實現的演算法(Java),可以避免這種笨拙的實現方式: /** * 根據分割積分法來求得積分值 * -3.89~3.89區間外的
標準正態分佈表(scipy.stats)
0. 標準正態分佈表與常用值 Z-score 是非標準正態分佈標準化後的 x即 z=x−μσz = \frac{x-\mu}{\sigma}z=σx−μ 表頭的橫向表示小數點後第二位,表頭的
C語言產生標準正態分佈或高斯分佈隨機數
1 #include <stdlib.h> 2 #include <stdio.h> 3 double gaussrand() 4 { 5 static double V1, V2, S; 6 static int phase = 0; 7
繼續隨機數:接受/拒絕方法(標準正態分佈)
前面在逆分佈函式法生成隨機數(以指數分佈和雙指數分佈為例)中已經說道了逆分佈函式方法生成隨機數,理論上來說的話,對於任意的分佈都是可以用逆分佈函式的方法得到的,因為分佈函式都是單調函式,也就是是說是可逆的,當然除了一些非常極端的情況,例如,函式雖然是遞增的但
[C#] 查標準正態分佈表
C#裡面要計算正態分佈是一件比較麻煩的事情,一般是通過查表來實現的。static double[] ayZTFB = null; /// <summary> /// 計算標準正態分佈表 /// </summary> /// <param nam
標準正態分佈函式的近似計算
之前想寫個程式自動分析資料的分佈,但卡在無法求正態分佈的分佈函數了,無意中複習概率論課程,發現在附錄中居然有近似的計算公式!太高興了記錄下來 #define pi(3.1415926535898) #define a0 (0.33267) #define a1 (0.4
均勻分佈生成標準正態分佈 python
一個分佈的隨機變數可通過把服從(0,1)均勻分佈的隨機變數代入該分佈的反函式的方法得到。均勻分佈的反函式卻求不了。所以我們就要尋找其他的辦法。 由均勻分佈生成標準正態分佈主要有3種方法
randn:產生正態分佈的隨機數或矩陣的函式
randn:產生均值為0,方差σ^2 = 1,標準差σ = 1的正態分佈的隨機數或矩陣的函式。用法:Y = randn(n):返回一個n*n的隨機項的矩陣。如果n不是個數量,將返回錯誤資訊。Y = randn(m,n) 或 Y = randn([m n]):返回一個m*n的隨
Excel圖表—二項分佈和正態分佈的對應關係
問題:假定某二項分佈對應引數為n=500, p=0.4,試分析與該二項分佈具有相同均值和標準差的正態分佈於該二項分佈的漸進關係。 結論:在實驗次數較大時(n=500),二項分佈已經與正態分佈基本
課堂練習--計算陣列的最大值,最小值,平均值,標準差,中位數;numpy.random模組提供了產生各種分佈隨機數的陣列;正態分佈;Matplotlib
#計算陣列的最大值,最小值,平均值,標準差,中位數 import numpy as np a=np.array([1, 4, 2, 5, 3, 7, 9, 0]) print(a) a1=np.max(a) #最大值 print(a1) a2=np.min(a) #最小值 print(a2) a3
PyTorch 生成隨機數Tensor(標準分佈、標準正態、離散正態……)
在使用PyTorch做實驗時經常會用到生成隨機數Tensor的方法,比如: torch.rand() torch.randn() torch.normal() torch.linespace() 均勻分佈 *torch.rand(sizes, out=None) → Tensor
MATLAB繪製正態分佈概率密度函式(normpdf)圖形
這裡是一個簡單的實現程式碼 x=linspace(-5,5,50); %生成負五到五之間的五十個數,行向量 y=normpdf(x,0,1); plot(x,y,‘k’); 圖片複製不過來。。就擺個連結好了 https://jingyan.baidu.com/article/6fb756ec
20.方差/標準差/數學期望/正態分佈/高斯函式(數學篇)--- OpenCV從零開始到影象(人臉 + 物體)識別系列
本文作者:小嗷 微信公眾號:aoxiaoji 吹比QQ群:736854977 本文你會找到以下問題的答案: 方差 標準差 數學期望 正態分佈 高斯函式 2.1 方差 方差描述隨機變數對於數學期望的偏離程度。(隨機變數可以
關於多元正態分佈的條件概率密度
多元正態分佈 多元正態分佈的密度函式如下 : fx(x1,...xn)=1(2π)k√|Σ|1/2exp(−12(x−μ)TΣ−1(x−μ)) (1) 其對應的矩母函式(也有稱動差函式)為exp(μTt+12tTΣt)。事實上,如果隨機向量[X1
【概率與統計】正態分佈(Normal Distribution)
連續型隨機變數最常用的分佈就是 正態分佈(normal distribution),也稱為高斯分佈(Gaussian distribution): N(x;μ,σ2)=12πσ2−−−−√exp(−12σ2(x−μ)2)N(x;μ,σ2)=12πσ2exp(−1
連續型概率分佈——正態分佈(一維)
今天想總結一下正太分佈,但是如果按照維基百科上面的講法,就太過複雜了,所以這裡著重講正態分佈在實際生活中的作用以及簡單的計算方法,也就是高中所學過的關於正態分佈的知識。在正式開始之前,還是把維基百科上面的科普拎出來過一遍正態分佈又名高斯分佈,是一個在數學、物理及工程等領域都非