
輕量化網路:MobileNet-V2
MobileNetV2:
《Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation》
於2018年1月公開在arXiv(美[ˈɑ:rkaɪv]) :https://arxiv.org/abs/1801.04381
MobileNetV2是對MobileNetV1的改進,同樣是一個輕量化卷積神經網路。
創新點:
1. Inverted residuals,通常的residuals block是先經過一個1*1的Conv layer,把feature map的通道數“壓”下來,再經過3*3 Conv layer,最後經過一個1*1 的Conv layer,將feature map 通道數再“擴張”回去。即先“壓縮”,最後“擴張”回去。
而 inverted residuals就是 先“擴張”,最後“壓縮”。為什麼這麼做呢?請往下看。
2.Linear bottlenecks,為了避免Relu對特徵的破壞,在residual block的Eltwise sum之前的那個 1*1 Conv 不再採用Relu,為什麼?請往下看。
創新點全寫在論文標題上了!
由於才疏學淺,對本論文理論部分不太明白,所以選取文中重要結論來說明MobileNet-V2。
先看看MobileNetV2 和 V1之間有啥不同
(原圖連結)
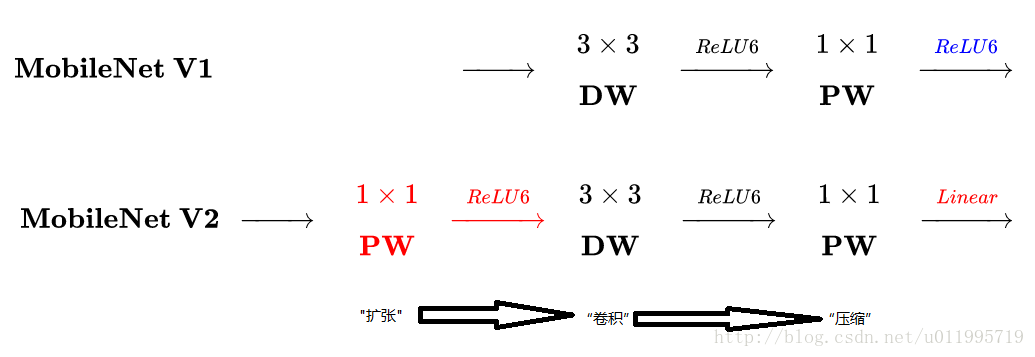
主要是兩點:
- Depth-wise convolution之前多了一個1*1的“擴張”層,目的是為了提升通道數,獲得更多特徵;
- 最後不採用Relu,而是Linear,目的是防止Relu破壞特徵。
再看看MobileNetV2的block 與ResNet 的block:
(原圖連結)
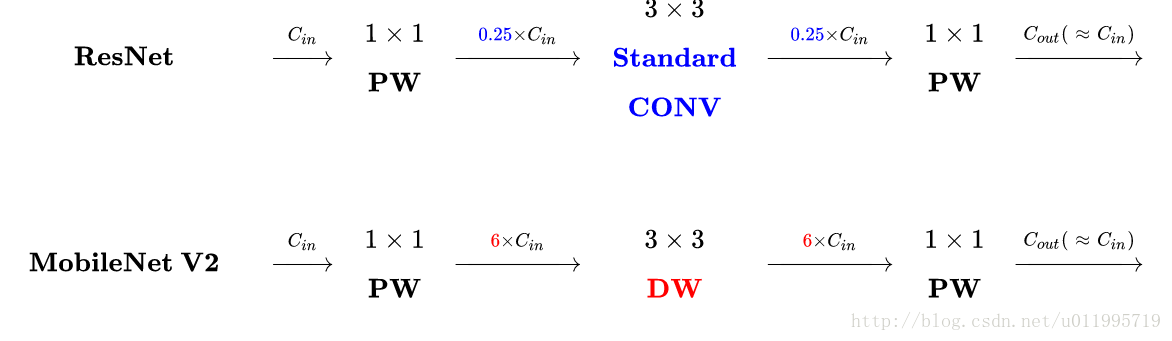
主要不同之處就在於,ResNet是:壓縮”→“卷積提特徵”→“擴張”,MobileNetV2則是Inverted residuals,即:“擴張”→“卷積提特徵”→ “壓縮”
正文:
MobileNet-V1 最大的特點就是採用depth-wise separable convolution來減少運算量以及引數量,而在網路結構上,沒有采用shortcut的方式。
Resnet及Densenet等一系列採用shortcut的網路的成功,表明了shortcut是個非常好的東西,於是MobileNet-V2就將這個好東西拿來用。
拿來主義,最重要的就是要結合自身的特點,MobileNet的特點就是depth-wise separable convolution,但是直接把depth-wise separable convolution應用到 residual block中,會碰到如下問題:
1.DWConv layer層提取得到的特徵受限於輸入的通道數,若是採用以往的residual block,先“壓縮”,再卷積提特徵,那麼DWConv layer可提取得特徵就太少了,因此一開始不“壓縮”,MobileNetV2反其道而行,一開始先“擴張”,本文實驗“擴張”倍數為6。 通常residual block裡面是 “壓縮”→“卷積提特徵”→“擴張”,MobileNetV2就變成了 “擴張”→“卷積提特徵”→ “壓縮”,因此稱為Inverted residuals
2.當採用“擴張”→“卷積提特徵”→ “壓縮”時,在“壓縮”之後會碰到一個問題,那就是Relu會破壞特徵。為什麼這裡的Relu會破壞特徵呢?這得從Relu的性質說起,Relu對於負的輸入,輸出全為零;而本來特徵就已經被“壓縮”,再經過Relu的話,又要“損失”一部分特徵,因此這裡不採用Relu,實驗結果表明這樣做是正確的,這就稱為Linear bottlenecks
MobileNet-V2網路結構
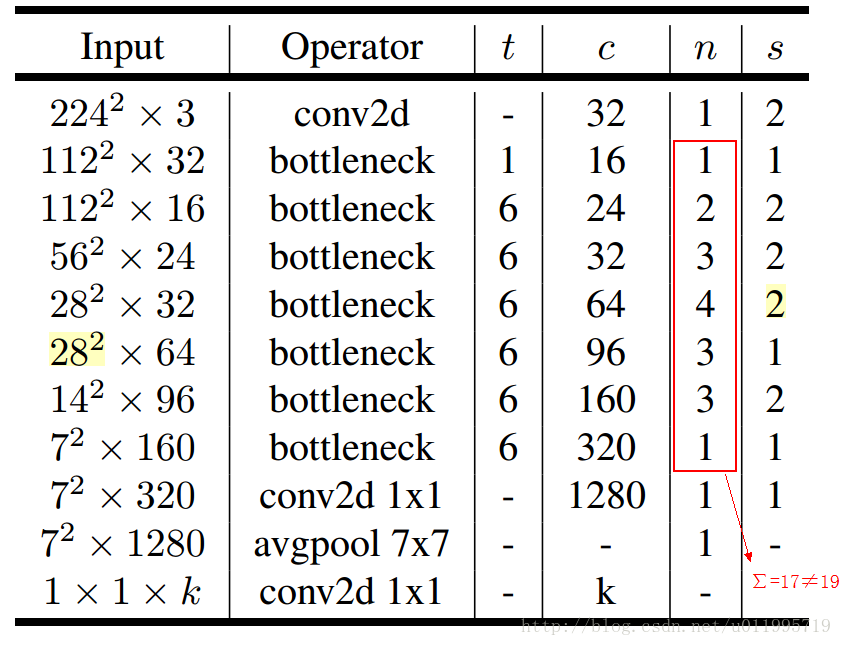
其中:t表示“擴張”倍數,c表示輸出通道數,n表示重複次數,s表示步長stride。
先說兩點有誤之處吧:
1. 第五行,也就是第7~10個bottleneck,stride=2,解析度應該從28降低到14;如果不是解析度出錯,那就應該是stride=1;
2. 文中提到共計採用19個bottleneck,但是這裡只有17個。
Conv2d 和avgpool和傳統CNN裡的操作一樣;最大的特點是bottleneck,一個bottleneck由如下三個部分構成:

這就是之前提到的inverted residuals結構,一個inverted residuals結構的Multiply Add=
h*w*d’ * 1*1*td’ +
h*w*td’ * k*k*1 +
h*w*t d’ * 1*1*d” =
h*w*d’*t(d’+ k*k + d”)
特別的,針對stride=1 和stride=2,在block上有稍微不同,主要是為了與shortcut的維度匹配,因此,stride=2時,不採用shortcut。 具體如下圖:
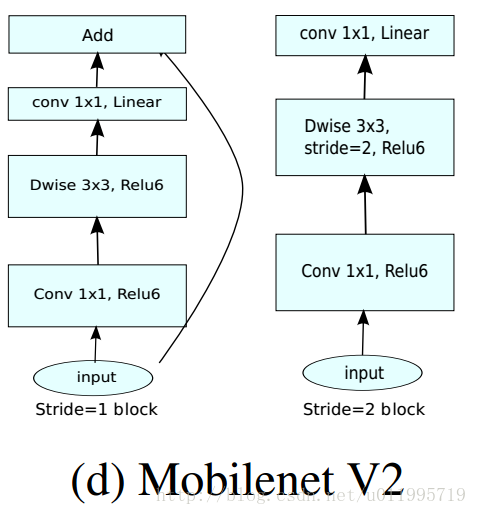
可以發現,除了最後的avgpool,整個網路並沒有採用pooling進行下采樣,而是利用stride=2來下采樣,此法已經成為主流,不知道是否pooling層對速度有影響,因此捨棄pooling層?是否有朋友知道那篇論文裡提到這個操作?
看看MobileNet-V2 分類時,inference速度:
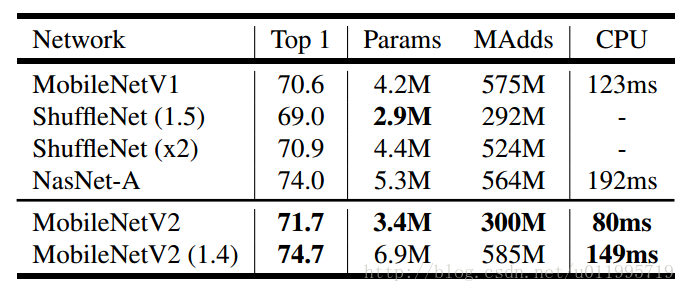
這是在手機的CPU上跑出來的結果(Google pixel 1 for TF-Lite)
同時還進行了目標檢測和影象分割實驗,效果都不錯,詳細請看原文。