
輕量化神經網路模型總結:SqueezeNet、Xception、MobileNet、ShuffleNet
總結今年來的幾個輕量化模型:SqueezeNet、Xception、MobileNet、ShuffleNet
下面給出時間軸:
- 2016.02 伯克利&斯坦福提出 SqueezeNet
- 2016.10 google提出 Xception
- 2017.04 google提出 MobileNet
- 2017.07 face++提出 ShuffleNet
其次,說一下模型輕量化的一些方法:
- 卷積核分解:使用1xN和NX1卷積核代替NXN卷積核;
- 使用深度壓縮deep compression方法:網路剪枝、量化、哈弗曼編碼;
- 奇異值分解;
- 硬體加速器;
- 低精度浮點數儲存;
小模型的好處有哪些:
- 在分散式訓練中,與伺服器通訊需求小;
- 引數少,從雲端下載模型的資料量小;
- 更適合在FPGA等記憶體首先的嵌入式、移動端裝置上部署;
1、SqueezeNet
地址連結:https://arxiv.org/pdf/1602.07360.pdf
1.1 核心思想
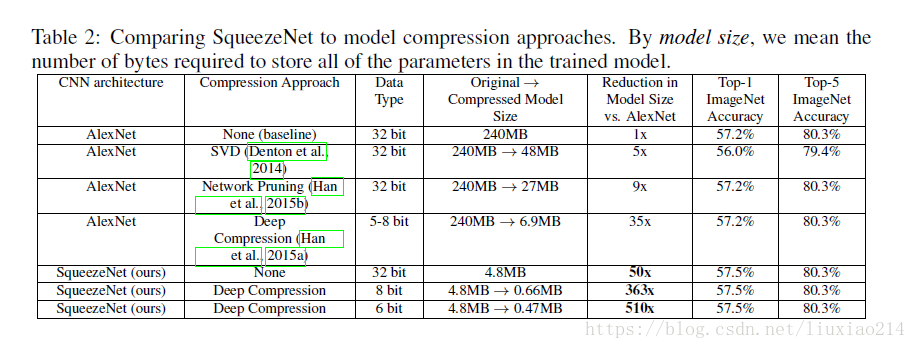
在ImageNet上實現了與Alexnet相似的效果,引數只有其1/50, 模型是0.5MB,佔其1/510。
SqueezeNet核心內容有以下幾點:
- 使用1x1卷積核代替3x3卷積核,減少引數量;
- 通過squeeze layer限制通道數量,減少引數量;
- 借鑑inception思想,將1x1和3x3卷積後結果進行concat;為了使其feature map的size相同,3x3卷積核進行了padding;
- 減少池化層,並將池化操作延後,給卷積層帶來更大的啟用層,保留更多地資訊,提高準確率;
- 使用全域性平均池化代替全連線層;
上述1-3是通過fire module實現的,fire module主要分為兩部分,如下圖所示
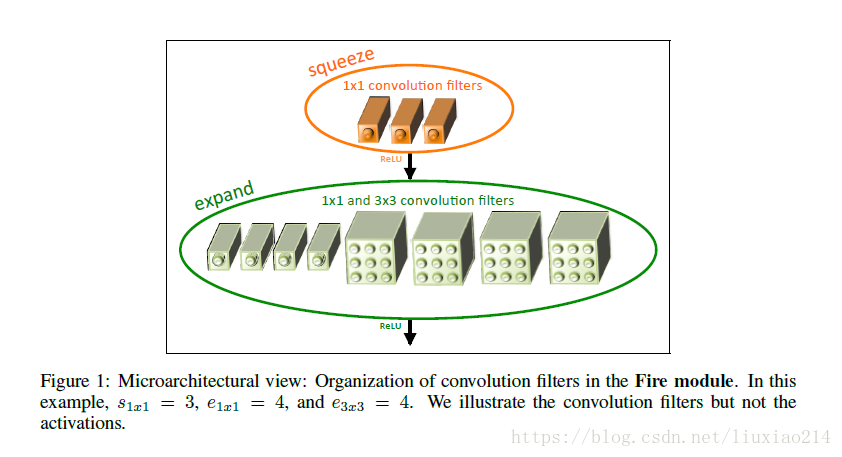
- squeeze:1x1卷積核,引數s_1x1表示卷積核數量
- expand:1x1卷積核和3x3卷積核,引數e_1x1和e_3x3分別表示兩種卷積核的數量
該模組一共三引數s_1x1、e_1x1、e_3x3,關係保持s_1x1< e_1x1+e_3x3
1.2 網路結構
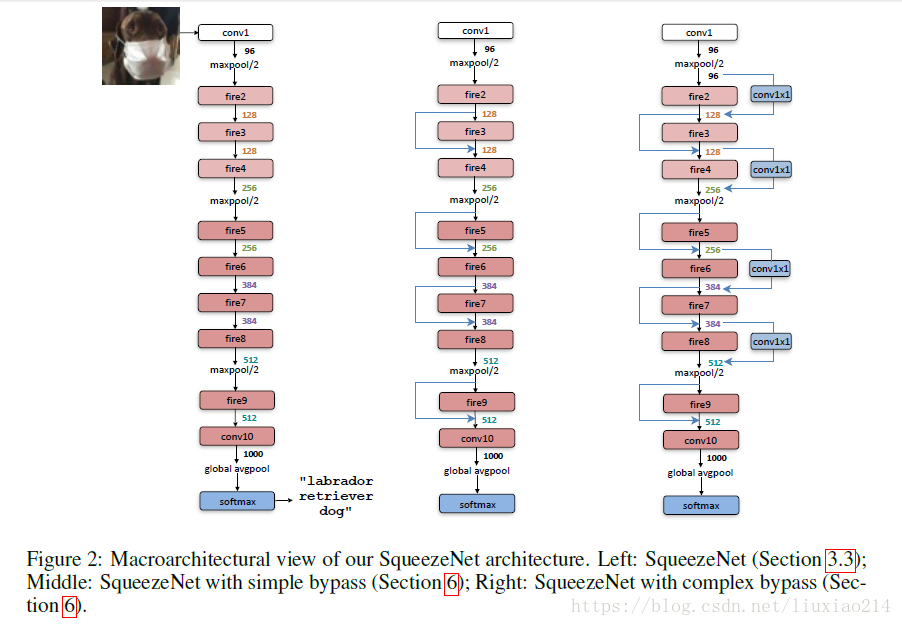
1.3 實驗結果
實驗結果表示模型小,且準確率不降,反而有點提高;
參考連結:
1、https://blog.csdn.net/csdnldp/article/details/78648543
2、https://blog.csdn.net/u011995719/article/details/78908755
2、Xception
地址連結:https://arxiv.org/abs/1610.02357
2.1 核心思想
雖然本文中方法可以降低引數量,但是論文加寬了網路結構,因此這篇論文不在於壓縮模型,旨在於提高效能,與同等引數量的inception v3相比,效果更好。
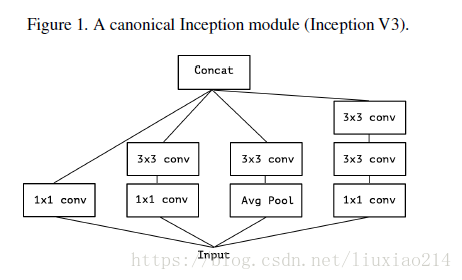
首先是inception v3的一系列延伸,見下圖:
1、版本1:最初的inception v3
2、版本2:對1進行簡化
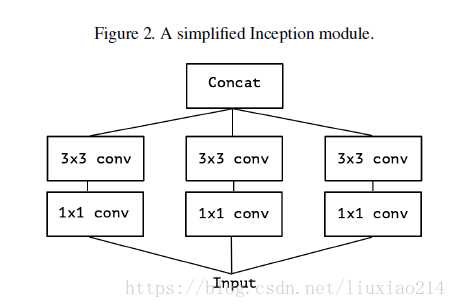
3、版本3:對2簡化,可以先使用一個統一的1x1卷積核,然後每個3x3卷積核的輸入只是1x1卷積後的feature map的一部分。本圖中是1/3;
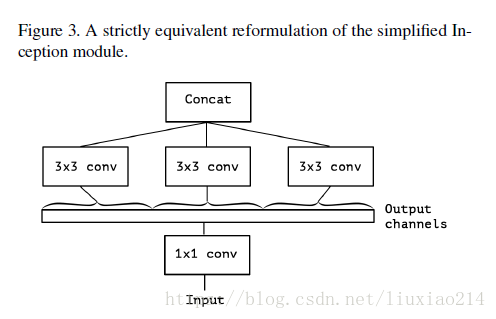
4、版本4:在3的基礎上進一步延伸,將1x1卷積後的所有feature map按通道全部劃分,每一個通道對應一個3x3卷積,即3x3卷積核的數量就是1x1卷積後feature map的通道數。
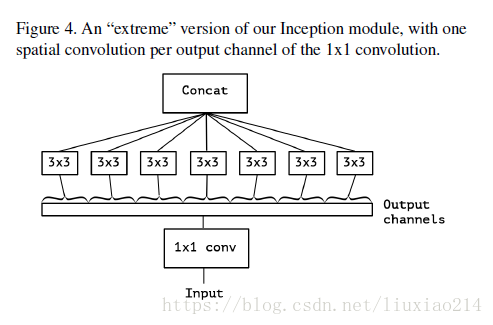
然後在xception中,主要採用depthwise separable convolution思想(這個後面在mobile net中詳細解釋,好奇怪,明明是mobile net後出現的,反正都是一家的,估計公佈先後的問題吧。)
首先xception類似於圖4,但是區別有兩點:
1、xception中沒有relu啟用函式;
2、圖4是先1x1卷積,後通道分離;xception是先進行通道分離,即depthwise separable convolution,然後再進行1x1卷積。
此外,進行殘差連線時,不再是concat,而是採用加法操作。
2.2 網路結構

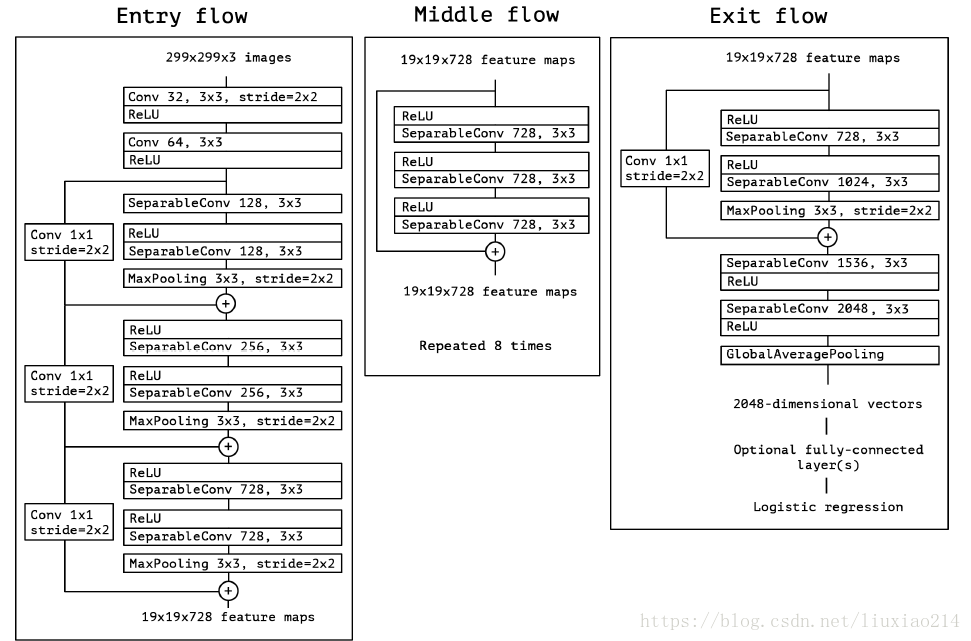
2.3 實驗結果
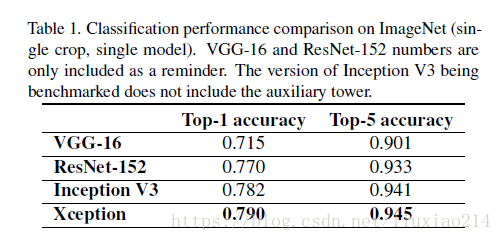
參考連結:
1、https://blog.csdn.net/u014380165/article/details/75142710
3、MobileNet
地址連結:https://arxiv.org/pdf/1704.04861.pdf
3.1 核心思想
主要是兩個策略:
- 採用depthwise separable convolution,就是分離卷積核;
- 設定寬度因子width multipler和解析度因子resolution multiplier;
3.1.1 depthwise separable convolution
假設上一層得到的feature map的size為D_K * D_K * M,本層的卷積核大小為D_K * D_K,卷積核個數為M。
1、首先介紹傳統卷積核的操作方式,如下圖。
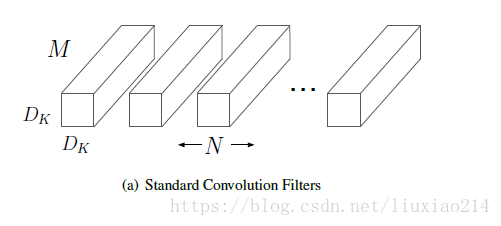
卷積核D_K * D_K需要在feature map的每個通道上進行D_K * D_K次卷積,然後一共M個卷積核,因此計算量為:
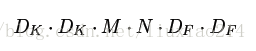
2、介紹depthwise separable convolution,如下圖

將卷積核進行拆解,分為兩步,首先用M個D_K * D_K卷積核在feature map進行卷積,計算量為
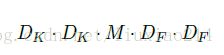
然後再使用N個1 * 1 * M卷積核在前面得到的結果上進行feature map,計算量為:
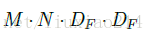
所以,進行分解後的總計算量為:
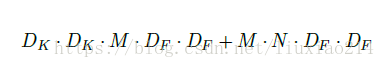
3、計算量比較
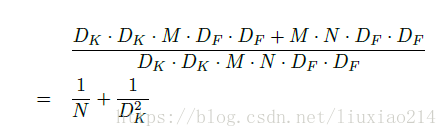
可以看到,隨著卷積核個數的增加,即通道數變多,feature map的大小,傳統方式的計算量比分解要大得多。
3.1.2 寬度因子和解析度因子
怎麼才能使網路進一步壓縮呢?可以進一步減少feature map的通道數和size,通過寬度因子減少通道數,解析度因子減少size。
1、寬度因子α
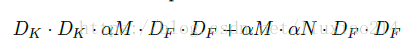
2、解析度因子β

兩個引數都屬於(0,1]之間,當為1時則是標準mobileNet。
3.2 網路結構
3.2.1 基本結構塊

3.2.2 網路結構
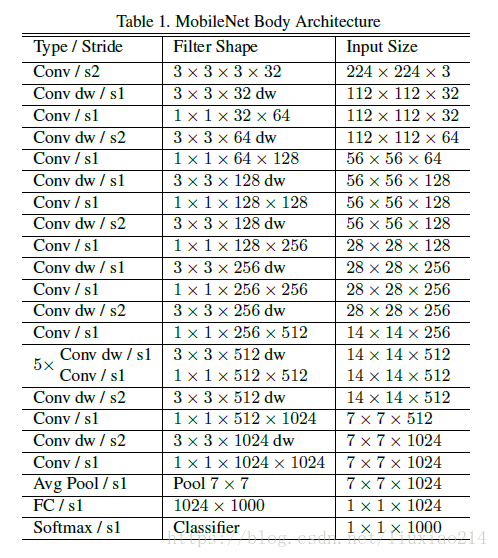
3.2.3 訓練細節
1、使用RMSprop優化器;
2、未做大量資料增強,因為引數量小過擬合不嚴重;
3、採用了隨機影象裁剪輸入;
4、使用較小的weight decay,或者不使用;
3.3 實驗結果
給出幾個基本的實驗比較結果。
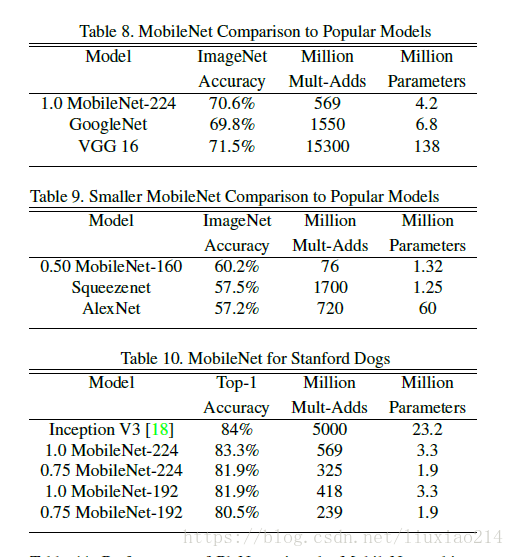
參考連結:
1、https://blog.csdn.net/t800ghb/article/details/78879612
2、https://blog.csdn.net/wfei101/article/details/78310226
3、https://blog.csdn.net/u014380165/article/details/72938047
4、ShuffleNet
地址連結:https://arxiv.org/pdf/1707.01083.pdf
4.1 核心思想
核心思想有兩點:
- 借鑑resnext分組卷積思想,但不同的是採用1x1卷積核;
- 進行通道清洗,加強通道間的資訊流通,提高資訊表示能力。
此外本篇論文中也採取了mobilenet的depthwise separasable convolution的方式。
4.1.1 逐點群卷積pointwise group convolution
這個就是採用resnext的思想,將通道分組,每組分別進行卷積操作,然後再把結果進行concat。但是不同於resnext的是,shufflenet採用的是1x1卷積核。
4.1.2 通道清洗channel shuffle
什麼是通道shuffle,就是在分組卷積後得到的feature map不直接進行concat,先將每組feature map按通道打亂,重新concat,如下圖所示:
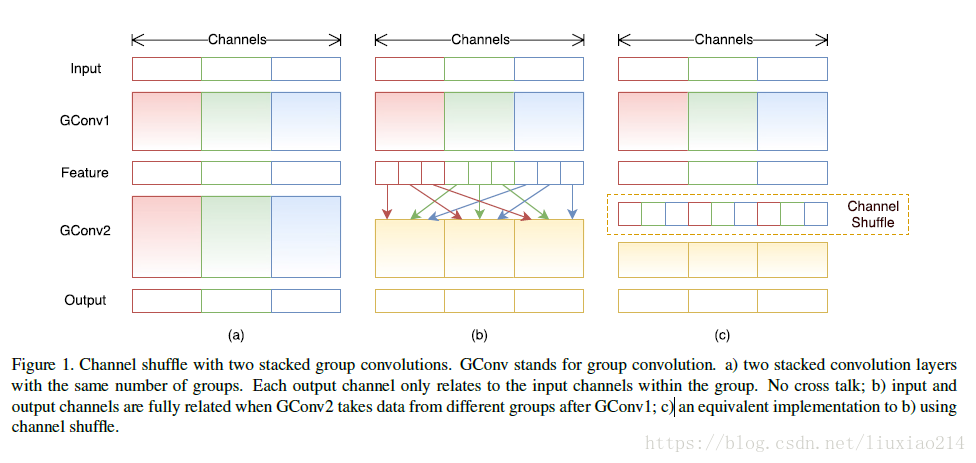
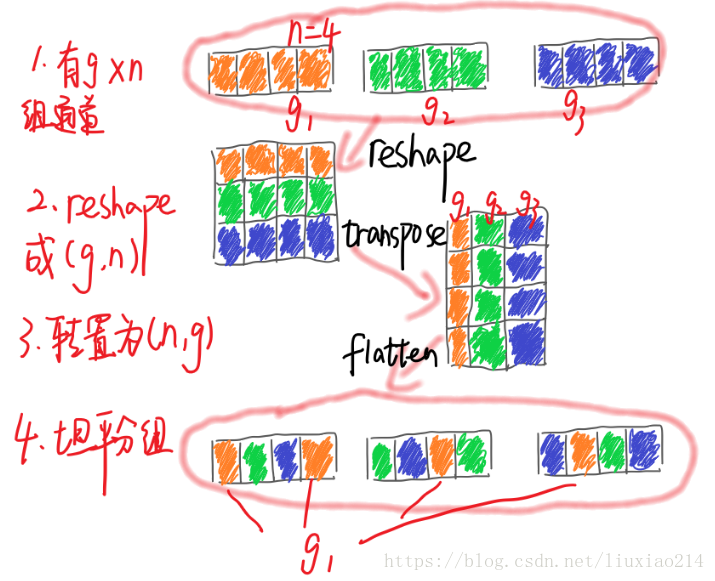
如何進行shuffle,這裡參考連結,
對於一個卷積層分為g組,
- 卷積後一共得到g×n個輸出通道的feature map;
- 將feature map 進行 reshape為(g,n);
- 進行轉置為(n,g);
- 對轉置結果flatten,再分回g組作為下一層的輸入。
4.2 網路結構
4.2.1 shuffle unit
下圖中,a是標準的殘差結構,不過是3x3卷積核使用了mobilenet中的depthwise convolution操作;
b是在a的基礎上加了本文的通道shuffle操作,先對1x1卷積進行分組卷積操作,然後進行channel shuffle;
c是在旁路加了一步長為2的3x3的平均池化,並將前兩者殘差相加的操作改為了通道concat,增加了通道數量。
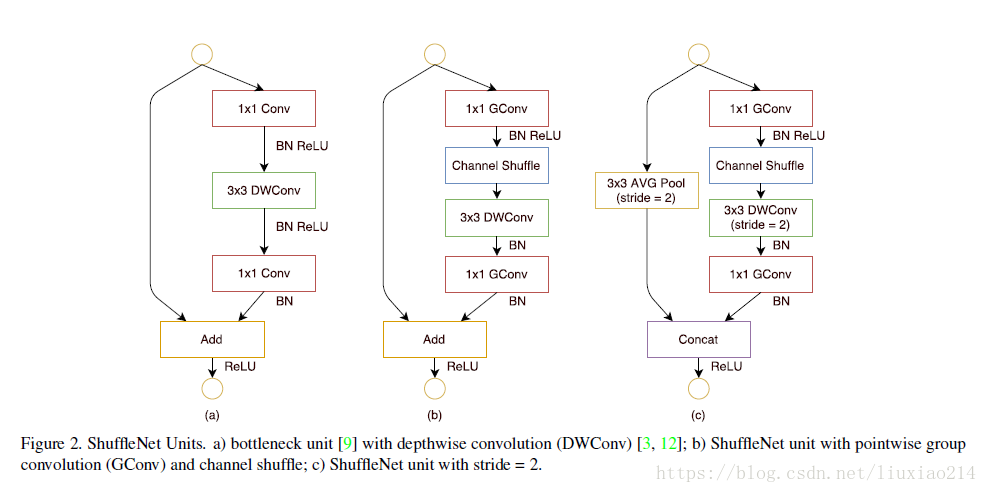
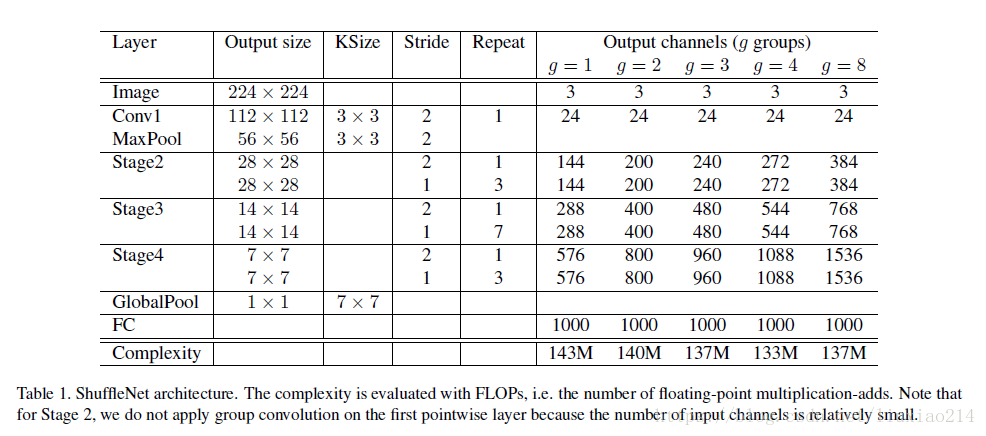
4.2.2 網路結構
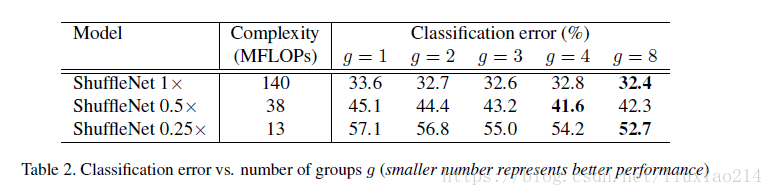
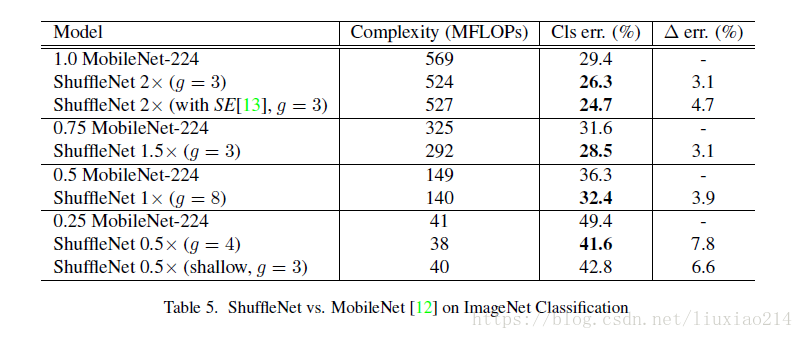
4.3 實驗結果
1、評估逐點組卷積:分組的效果均比沒有分組的效果好,但是某些模型隨著組數增加,效能有下降,這就是通道間失去聯絡帶來的問題;
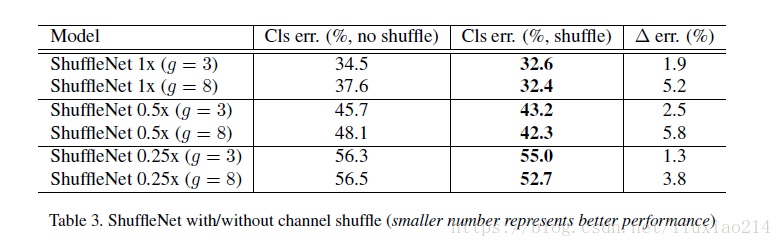
2、評估channel shuffle,shuffle會比沒有shuffle效果好,而且對於組數越大,效果越好,說明了shuffle的重要性,也說明了上圖中組數增加效能下降的問題。
3、與mobilenet的比較
參考連結: