
輕量化神經網路綜述
陳泰紅
研究方向:機器學習、影象處理
導言
深度神經網路模型被廣泛應用在影象分類、物體檢測等機器視覺任務中,並取得了巨大成功。然而,由於儲存空間和功耗的限制,神經網路模型在嵌入式裝置上的儲存與計算仍然是一個巨大的挑戰。
目前工業級和學術界設計輕量化神經網路模型主要有4個方向:
(1)人工設計輕量化神經網路模型;
(2)基於神經網路架構搜尋(Neural Architecture Search,NAS)的自動化設計神經網路;
(3)CNN模型壓縮;
(4)基於AutoML的自動模型壓縮。
本文首先介紹基本卷積計算單元,並基於這些單元介紹MobileNet V1&V2,ShuffleNet V1&V2的設計思路。其次,最後介紹自動化設計神經網路的主流方法和基本思路。最後概述CNN模型壓縮的主要方法,詳細說明基於AutoML的自動模型壓縮的相關演算法:AMC、PockFlow以及TensorFlow lite的程式碼實現。
1、基本卷積運算
手工設計輕量化模型主要思想在於設計更高效的“網路計算方式”(主要針對卷積方式),從而使網路引數減少,並且不損失網路效能。本節概述了CNN模型(如MobileNet及其變體)中使用的基本卷積運算單元,並基於空間維度和通道維度,解釋計算效率的複雜度。
1.1 標準卷積
圖1標準卷積計算圖
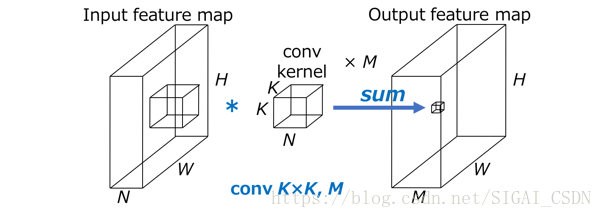
HxW表示輸入特徵圖空間尺寸(如圖1所示,H和W代表特徵圖的寬度和高度,輸入和輸出特徵圖尺寸不變),N是輸入特徵通道數,KxK表示卷積核尺寸,M表示輸出卷積通道數,則標準卷積計算量是HWNK²M。

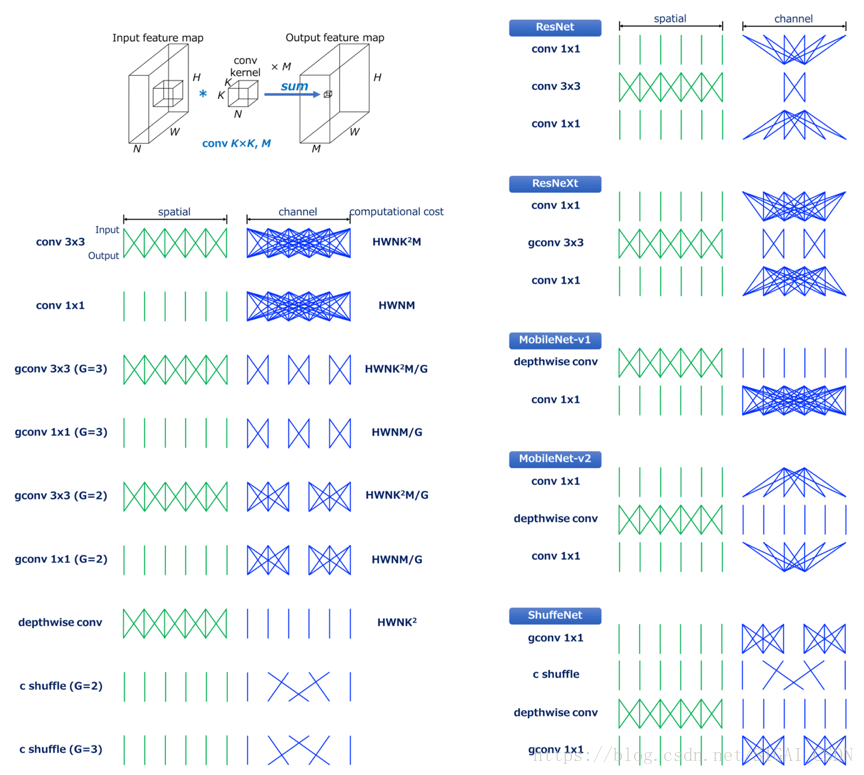
如圖3所示標準卷積在空間維度和通道維度直觀說明(以下示意圖省略“spatial“,”channel“,”Input“,”Output“),輸入特徵圖和輸出特徵圖之間連線線表示輸入和輸出之間的依賴關係。以conv3x3為例子,輸入和輸出空間“spatial”維度密集連線表示區域性連線;而通道維度是全連線,卷積運算都是每個通道卷積操作之後的求和(圖2),和每個通道特徵都有關,所以“channel”是互相連線的關係。

1.2 Grouped Convolution
分組卷積是標準卷積的變體,其中輸入特徵通道被為G組(圖4),並且對於每個分組的通道獨立地執行卷積,則分組卷積計算量是HWNK²M/G,為標準卷積計算量的1/G。

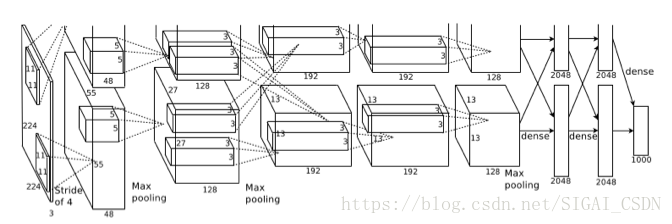
Grouped Convlution最早源於AlexNet。AlexNet在ImageNet LSVRC-2012挑戰賽上大顯神威,以絕對優勢奪得冠軍,是卷積神經網路的開山之作,引領了人工智慧的新一輪發展。但是AlexNet訓練時所用GPU GTX 580視訊記憶體太小,無法對整個模型訓練,所以Alex採用Group convolution將整個網路分成兩組後,分別放入一張GPU卡進行訓練(如圖5所示)。
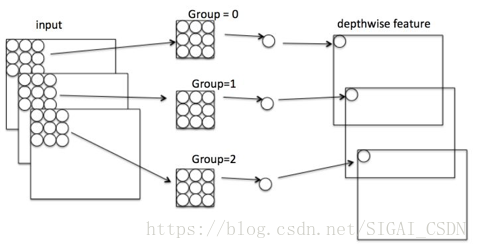
1.3 Depthwise convolution
Depthwise convolution[7]最早是由Google提出,是指將NxHxWxC輸入特徵圖分為group=C組(既Depthwise 是Grouped Convlution的特殊簡化形式),然後每一組做k*k卷積,計算量為HWK²M(是普通卷積計算量的1/N,通過忽略通道維度的卷積顯著降低計算量)。Depthwise相當於單獨收集每個Channel的空間特徵。

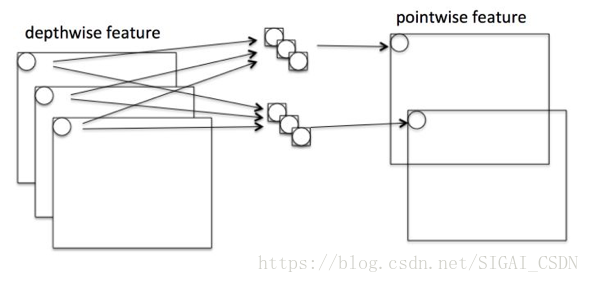
1.4 pointwise convolution
Pointwise是指對NxHxWxC的輸入做 k個普通的 1x1卷積,如圖8,主要用於改變輸出通道特徵維度。Pointwise計算量為HWNM。
Pointwise卷積相當於在通道之間“混合”資訊。

1.5 Channel Shuffle
Grouped Convlution導致模型的資訊流限制在各個group內,組與組之間沒有資訊交換,這會影響模型的表示能力。因此,需要引入group之間資訊交換的機制,即Channel Shuffle操作。
Channel shuffle是ShuffleNet提出的(如圖 5 AlexNet也有Channel shuffle機制),通過張量的reshape 和transpose,實現改變通道之間順序。

如圖10所示Channel shuffle G=2示意圖,Channel shuffle沒有卷積計算,僅簡單改變通道的順序。
2、人工設計神經網路
MobileNet V1&V2,ShuffleNet V1&V2有一個共同的特點,其神經網路架構都是由基本Block單元堆疊,所以本章節首先分析基本Block架構的異同點,再分析整個神經網路的優缺點。
2.1MobileNet V1
MobileNet V1是Google第一個提出體積小,計算量少,適用於移動裝置的卷積神經網路。MobileNet V1之所以如此輕量,背後的思想是用深度可分離卷積(Depthwise separable convolution)代替標準的卷積,並使用寬度因子(width multiply)減少引數量。
深度可分離卷積把標準的卷積因式分解成一個深度卷積(depthwise convolution)和一個逐點卷積(pointwise convolution)。如1.1標準卷積的計算量是HWNK²M,深度可分離卷積總計算量是:
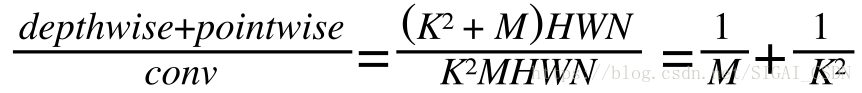
一般網路架構中M(輸出特徵通道數)>>K²(卷積核尺寸) (e.g. K=3 and M ≥ 32),既深度可分離卷積計算量可顯著降低標準卷積計算量的1/8–1/9。
深度可分離卷積思想是channel相關性和spatial相關性解耦圖12。


為了進一步降低Mobilenet v1計算量,對輸入輸出特徵通道數M和N乘以寬度因子α(α∈(0,1),d典型值0.25,0.5和0.75),深度可分離卷積總計算量可以進一降低為:

2.2 ShuffleNet V1
ShuffleNet是Face++提出的一種輕量化網路結構,主要思路是使用Group convolution和Channel shuffle改進ResNet,可以看作是ResNet的壓縮版本。
圖13展示了ShuffleNet的結構,其中(a)就是加入BatchNorm的ResNet bottleneck結構,而(b)和(c)是加入Group convolution和Channel Shuffle的ShuffleNet的結構。
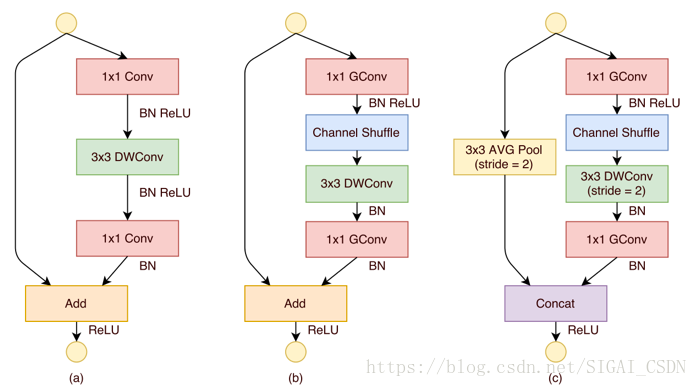

如所示,ShuffleNet block最重要的操作是channel shuffle layer,在兩個分組卷積之間改變通道的順序,channel shuffle實現分組卷積的資訊交換機制。
ResNet bottleneck計算量:
ShuffleNet stride=1計算量:

對比可知,ShuffleNet和ResNet結構可知,ShuffleNet計算量降低主要是通過分組卷積實現。ShuffleNet雖然降低了計算量,但是引入兩個新的問題:
1、channel shuffle在工程實現佔用大量記憶體和指標跳轉,這部分很耗時。
2、channel shuffle的規則是人工設計,分組之間資訊交流存在隨意性,沒有理論指導。
2.3 MobileNet V2
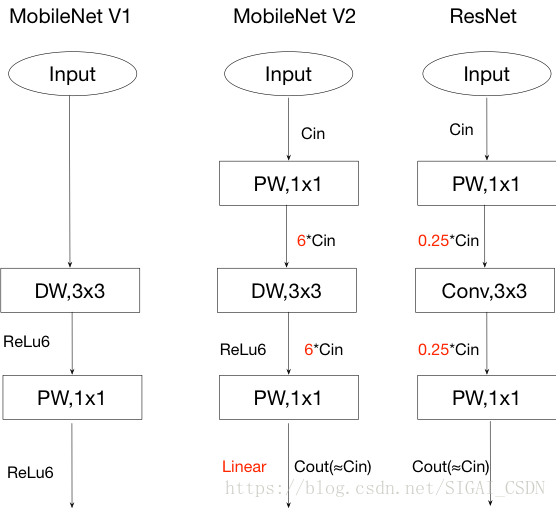
MobileNet V1設計時參考傳統的VGGNet等鏈式架構,既傳統的“提拉米蘇”式卷積神經網路模型,都以層疊卷積層的方式提高網路深度,從而提高識別精度。但層疊過多的卷積層會出現一個問題,就是梯度彌散(Vanishing)。殘差網路使資訊更容易在各層之間流動,包括在前向傳播時提供特徵重用,在反向傳播時緩解梯度訊號消失。於是改進版的MobileNet V2[3]增加skip connection,並且對ResNet和Mobilenet V1基本Block如下改進:
● 繼續使用Mobilenet V1的深度可分離卷積降低卷積計算量。
● 增加skip connection,使前向傳播時提供特徵複用。
● 採用Inverted residual block結構。該結構使用Point wise convolution先對feature map進行升維,再在升維後的特徵接ReLU,減少ReLU對特徵的破壞。
2.4 ShuffleNet V2
Mobile V1&V2,shuffle Net V1 在評價維度的共同特徵是:使用FLOPS作為模型的評價標準,但是在移動終端裝置時需要滿足各個條件:引數少、速度快和精度高,單一的引數少並不一定實現速度快和精度高。
Face++提出的ShuffeNet V2,實現使用直接指標(運算速度)代替間接評價指標(例如FLOPS),並在ARM等移動終端進行評估。並且基於減少計算量提出四個原則:
(1)使用輸入和輸出通道寬度不同增加捲積的計算量;
(2)組卷積增加MAC;
(3)多分支降低運算效率;
(4)元素級運算增加計算量。
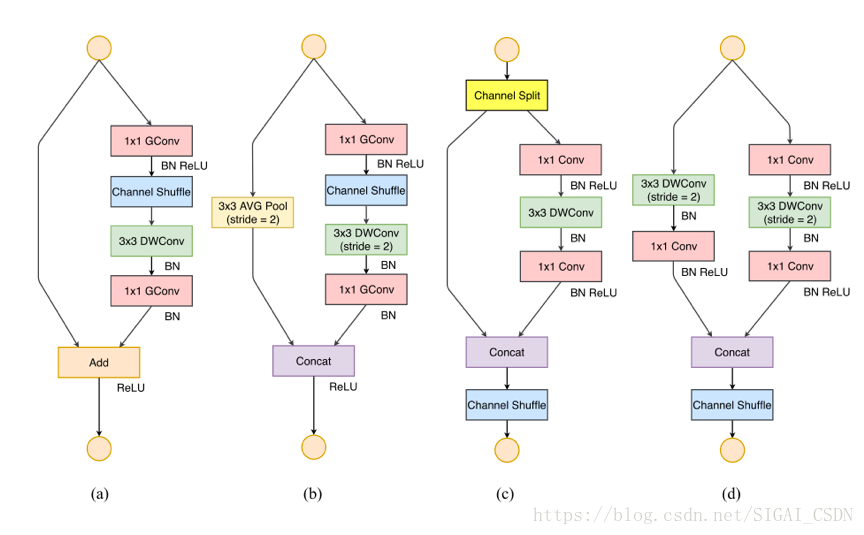
如圖16所示
(a)ShuffleNet 基本單元;
(b)用於空間下采樣 (2×) 的 ShuffleNet 單元;
(c)ShuffleNet V2 的基本單元;
(d)用於空間下采樣 (2×) 的 ShuffleNet V2 單元。
ShuffleNet V2 引入通道分割(channel split)操作, 將輸入的feature maps分為兩部分:一個分支為shortcut流,另一個分支含三個卷積(且三個分支的通道數一樣)。分支合併採用拼接(concat),讓前後的channel數相同,最後進行Channel Shuffle(完成和ShuffleNet V1一樣的功能)。元素級的三個運算channel split、concat、Channel Shuffle合併一個Element-wise,顯著降低計算複雜度。
ShuffleNet V2雖然提出減少計算量的四個原則,基本卷積單元仍採用Depthwise和Pointwise降低計算量,但是沒有提出如何實現提高準確率,推斷延遲等評價指標。
對比MobileNet V1&V2,ShuffleNet V1&V2模型(圖17),手工設計輕量化模型主要得益於depth-wise convolution減少計算量,而解決資訊不流暢的問題,MobileNet 系列採用了 point-wise convolution,ShuffleNet 採用的是 channel shuffle。
3、NAS與神經網路架構搜尋
卷積神經網路(CNN)已被廣泛用於影象分類、人臉識別、目標檢測和其他領域。然而,為移動裝置設計 CNN 是一項具有挑戰性的工作,因為移動端模型需要體積小、速度快,還要保持精準。儘管人們已經做了大量努力來設計和改進移動端模型,第二章所總結MobileNet系列、ShuffleNet系列。但手動設計高效模型仍然是一項挑戰,因為要考慮的因素太多。AutoML神經架構搜尋的發展促進移動端 CNN 模型的自動化設計。
NAS的演算法綜述可參看本人之前寫的一篇綜述文章《讓演算法解放演算法工程師----NAS綜述》[10]。在綜述文章中有關NAS的搜尋空間,搜尋策略,效能評估策略均已經做了總結,而且NAS的復現比較耗費GPU資源(NasNet做實驗時間使用500塊GPUx4天,一般專案組的資源難以望其項背),本章節主要是比較NAS設計的網路與傳統手工設計神經網路異同,以及NAS的發展方向。
3.1 NasNet
NasNet是基於AutoML方法,首先在CIFAR-10這種小資料集上進行神經網路架構搜尋,以便 AutoML 找到最佳卷積層並靈活進行多次堆疊來建立最終網路,並將學到的最好架構遷移到ImageNet影象分類和 COCO 物件檢測中。NAS在搜尋時使用的基本運算如下,包括常用的depthwise-separable,pool,3x3卷積等,使得block執行時對輸入尺寸沒有要求(例如卷積,pooling等操作)。這樣影象由cifar的32 x32到imagenet的大尺寸圖片均可實現分類任務。

NasNet設計基於人類的經驗,設計設計兩類 Cells:Normal cell 和Reduction cell(圖 19) 。Normal cell不改變輸入feature map的大小的卷積, 而reduction cell將輸入feature map的長寬各減少為原來的一半的卷積,是通過增加stride的大小來降低size。通過NasNet構建堆疊模組(cells)的深度實現架構的設計。
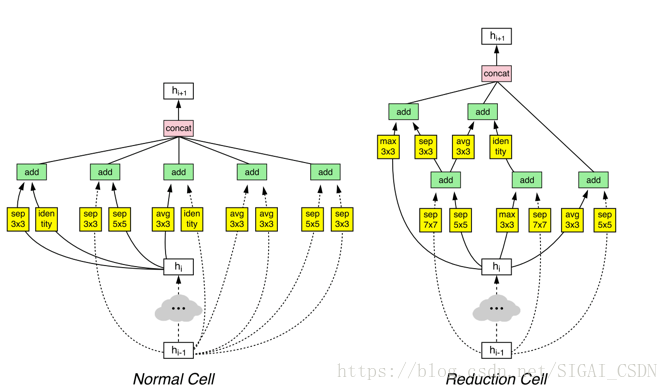
NasNet首先基於人類的一些先驗知識:卷積運算型別、Cell連線方式,Cell內的多分支拓撲結構,這些是積木。NasNet的搜尋演算法就是搭積木的過程,不斷嘗試各種可行的架構,通過代理評價指標確定模型的效能,實現全域性最優搜尋。
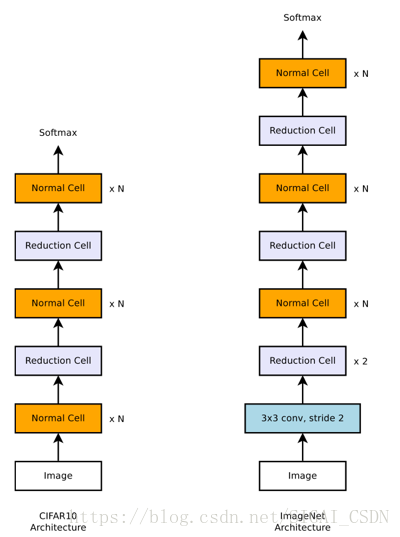

NasNet雖然實現準確率state-of-art水平,但是推斷延時較大,在移動端對實時性苛刻場景難以大規模運用。
3.2 MnasNet
MnasNet是Google提出的探索了一種使用強化學習設計移動端模型的自動化神經架構搜尋方法,並且實現準確率和運算速率突破。MnasNet 能夠找到執行速度比 MobileNet V2快 1.5 倍、比 NASNet 快 2.4 倍的模型,同時達到同樣的 ImageNet top-1 準確率。
MnasNet的搜尋空間與NasNet類似,但是搜尋目標函式同時考慮準確率和速率:

m 表示模型,ACC(m) 表示目標模型的準確率,LAT(m) 表示耗時,T 表示目標耗時。而論文提出一種策略,基於梯度的強化學習方法尋找帕雷託最優,同時對 ACC(m) 和 LAT(m) 帕雷託改善。

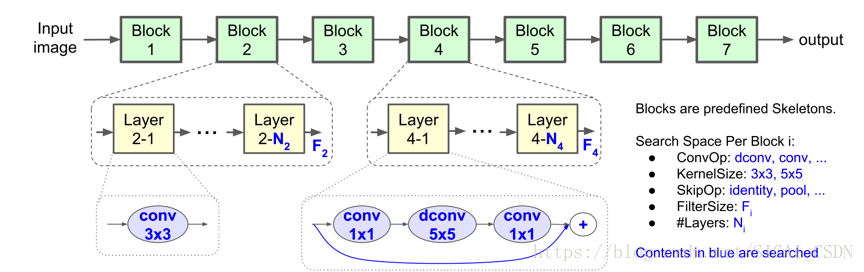
如圖21顯示了 MnasNet 演算法的神經網路架構,包含一系列線性連線 blocks,每個 block 雖然包含不同類別的卷積層,每一卷積層都包含 depthwise convolution 卷積操作,最大化模型的計算效率。但是和 MobileNet V1&V2 等演算法有明顯不同:
1、模型使用更多 5x5 depthwise convolutions。
2、層分級的重要性。很多輕量化模型重複 block 架構,只改變濾波器尺寸和空間維度。論文提出的層級搜尋空間允許模型的各個 block 包括不同的卷積層。
3、論文使用強化學習的思路,首先確定了 block 的連線方式,在每個 block 使用層級搜尋空間,確定每個卷積層的卷積型別,卷積核、跳躍層連線方式,濾波器的尺寸等。其基本策略還是延續人工設計神經網路思路。
3.3 NAS發展方向
1、NAS的搜尋空間有很大的侷限性。目前NAS演算法仍然使用手工設計的結構和blocks,NAS僅僅是將這些blocks堆疊。人工痕跡太過明顯,NAS還不能自行設計網路架構。NAS的一個發展方向是更廣泛的搜尋空間,尋找真正有效率的架構,當然對搜尋策略和效能評估策略提出更高的要求。
2、以google的NAS為基礎,很多模型專注於優化模型的準確率而忽視底層硬體和裝置,僅考慮準確率高的模型難以在移動終端部署。研究針對多工和多目標問題的 NAS,基於移動端的多目標神經網路搜尋演算法,評價指標從準確率擴充套件到功耗、推斷延時、計算複雜度、記憶體佔用、FLOPs等指標,解決移動端實際應用問題。
3、目前的NAS發展是以分類任務為主,在分類任務設計的模型遷移到目標檢測語義分割模型中。
Google在Cloud AutoML不斷髮力,相比較而言之前的工作只是在影象分類領域精耕細作,如今在影象語義分割開疆擴土,在arxiv提交第一篇基於NAS(Neural network architecture)的語義分割模型[12](DPC,dense prediction cell),已經被NIPS2018接收,並且在Cityscapes,PASCAL-Person-Part,PASCAL VOC 2012取得state-of-art的效能(mIOU超過DeepLabv3+),和更高的計算效率(模型引數少,計算量減少)。
如果讓強化學習自己選擇模型的架構,比如 Encoder-Decoder,U-Net,FPN等,相信在目標檢測、實體分割等領域會有更好的表現。
4、AutoML自動模型壓縮
CNN模型替代了傳統人工設計(hand-crafted)特徵和分類器,不僅提供了一種端到端的處理方法,不斷逼近計算機視覺任務的精度極限的同時,其深度和尺寸也在成倍增長。工業界不僅在設計輕量化模型(MobileNet V1&V2,ShuffleNet V1&V2系列),也在不斷實踐如何進一步壓縮模型,在行動式終端裝置實現準確率、計算速率、裝置功耗、記憶體佔用的小型化。
CNN模型壓縮是在計算資源有限、能耗預算緊張的移動裝置上有效部署神經網路模型的關鍵技術。本文簡介概述CNN模型壓縮主流演算法,重點介紹如何實現基於AutoML的模型壓縮演算法。
4.1 CNN模型壓縮概述
CNN模型壓縮是從壓縮模型引數的角度降低模型的計算量。
在第2節介紹的人工設計輕量型神經網路結構,多是依賴Grouped Convlution、Depthwise、Pointwise、Channel Shuffle這些基本單元組成的Block,但是這些設計方法存在偶然性,不是搜尋空間的最優解。
韓鬆提出的Deep compression[5]獲得 ICLR2016年的best paper,也是CNN模型壓縮領域經典之作。論文提出三種方法:剪枝、權值共享和權值量化、哈夫曼編碼。剪枝就是去掉一些不必要的網路權值,只保留對網路重要的權值引數;權值共享就是多個神經元見的連線採用同一個權值,權值量化就是用更少的位元數來表示一個權值。對權值進行哈夫曼編碼能進一步的減少冗餘。 作者在經典的機器學習演算法,AlexNet和VGG-16上運用上面這些模型壓縮的方法,在沒有精度損失的情況下,把AlexNet模型引數壓縮了35倍,把VGG模型引數壓縮了49倍,並且在網路速度和網路能耗方面也取得了很好的提升。
CNN模型壓縮沿著Deep compression的思路,壓縮演算法可分為四類:引數修剪和共享、低秩分解、遷移/壓縮卷積濾波器和知識蒸餾等。基於引數修剪(parameter pruning)和共享的方法關注於探索模型引數中冗餘的部分,並嘗試去除冗餘和不重要的引數。基於低秩分解(Low-rank factorization)技術的方法使用矩陣/張量分解以估計深層 CNN 中最具資訊量的引數。基於遷移/壓縮卷積濾波器(transferred/compact convolutional filters)的方法設計了特殊結構的卷積濾波器以減少儲存和計算的複雜度。而知識精煉(knowledge distillation)則學習了一個精煉模型,即訓練一個更加緊湊的神經網路以再現大型網路的輸出結果。
4.2 AMC
傳統的模型壓縮技術依賴手工設計的啟發式和基於規則的策略,需要演算法設計者探索較大的設計空間,在模型大小、速度和準確率之間作出權衡,而這通常是次優且耗時的。西安交通大學與Google提出了適用於模型壓縮的AMC[8](AutoML for Model Compres- sion,AMC),利用強化學習提供模型壓縮策略。
這種基於學習的壓縮策略效能優於傳統的基於規則的壓縮策略,具有更高的壓縮比,在更好地保持準確性的同時節省了人力成本。
1、Problem Definition
模型壓縮在維度上可分為Fine-grained pruning和Coarse-grained/structured pruning。Fine-grained pruning主要實現剪枝權重的非重要張量,實現非常高的壓縮率同時保持準確率。Coarse-grained pruning旨在剪枝權重張量的整個規則區域(例如,通道,行,列,塊等),例如在MobileNet V1&V2均存在寬度因子α對通道特徵進行瘦身,但是寬度因子α對每一層的通道特徵都固定比率壓縮。
假設權重張量是n x c x k x k,c,n分別是輸入輸出通道數,k是卷積核尺寸。對於fine-grained pruning,稀疏度定義為零元素的數量除以總元素的數量既zeros/(n x c x k x h),而channel pruning,權重張量縮小為n x c’ x k x k,既稀疏度為c’/c。
但是壓縮模型的精度對每層的稀疏性非常敏感,需要細粒度的動作空間。因此,論文在一個離散的空間上搜索,而是通過 DDPG agent 提出連續壓縮比控制策略(圖 20),通過反覆試驗來學習:在精度損失時懲罰,在模型縮小和加速時鼓勵。actor-critic 的結構也有助於減少差異,促進更穩定的訓練。
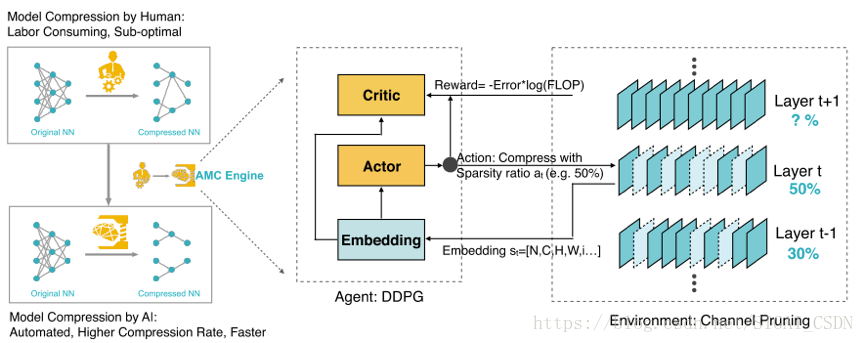
2、搜尋空間
AMC對每一層t定義了11個特徵表示st的狀態:
t是層序號,卷積核尺寸是n x c x k x k,輸入特徵尺寸是c x h x w,FLOPs[t]是Lt層的FLOPs,Reduced是上一層減少的FLOPs,Rest表示下一層的FLOPs,這些特徵全部歸一化到[0, 1]。
3、搜尋評估策略
通過限制動作空間既每一卷積層層的稀疏率(sparsity ratio),論文提出分別針對latency-critical和quality-critical應用提出兩種損失函式:
對於latency-critical的AI應用(例如,手機APP,自動駕駛汽車和廣告排名),AMC採用資源受限的壓縮(resource-constrained compression),在最大硬體資源(例如,FLOP,延遲和模型大小)下實現最佳精度;
對於quality-critical的AI應用(例如Google Photos),AMC提出精度保證的壓縮(accuracy-guaranteed compression),在實現最小尺寸模型的同時不損失精度。

3、結論
本文提出AutoML模型壓縮(AMC),利用增強學習自動搜尋設計空間,大大提高了模型壓縮質量。我們還設計了兩種新的獎勵方案來執行資源受限壓縮和精度保證壓縮。在Cifar和ImageNet上採用AMC方法對MobileNet、MobileNet-v2、ResNet和VGG等模型進行壓縮,取得了令人信服的結果。在谷歌Pixel1手機上,我們將MobileNet的推理速度從8.1fps提升到16.0 fps。AMC促進了移動裝置上的高效深度神經網路設計。
論文提出的壓縮方法,僅僅從通道特徵的稀疏度考慮,壓縮演算法粗放,沒有全域性考慮模型的其他能力,另外論文目前沒有公佈原始碼,論文的復現還需要一些細節需要商榷。
4.3 PocketFlow
騰訊AI Lab機器學習中心近日宣佈成功研發出世界上首款自動化深度學習模型壓縮框架——PocketFlow,但是截止筆記成稿時仍未公佈原始碼。
PocketFlow框架主要由兩部分元件構成,分別是模型壓縮/加速演算法元件和超引數優化元件,具體結構如所示。
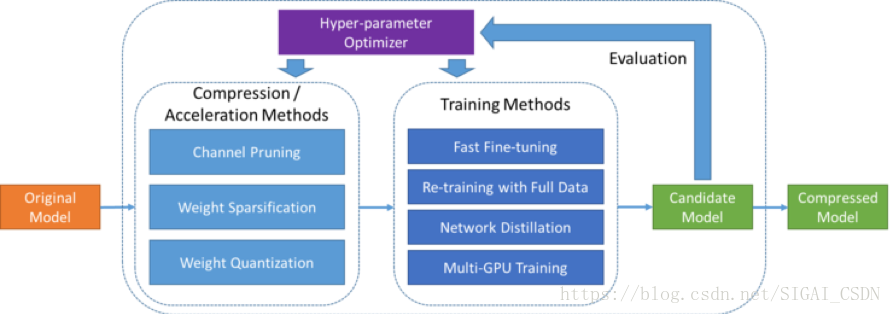
開發者將未壓縮的原始模型作為PocketFlow框架的輸入,同時指定期望的效能指標,例如模型的壓縮和/或加速倍數;在每一輪迭代過程中,超引數優化元件選取一組超引數取值組合,之後模型壓縮/加速演算法元件基於該超引數取值組合,對原始模型進行壓縮,得到一個壓縮後的候選模型;基於對候選模型進行效能評估的結果,超引數優化元件調整自身的模型引數,並選取一組新的超引數取值組合,以開始下一輪迭代過程;當迭代終止時,PocketFlow選取最優的超引數取值組合以及對應的候選模型,作為最終輸出,返回給開發者用作移動端的模型部署。
4.4 TensorFlow Lite
TensorFlow Lite近日釋出了一個新的優化工具包,引入post-training模型量化技術[9], 將模型大小縮小了4倍,執行速度提升了3倍!通過量化模型,開發人員還將獲得降低功耗的額外好處。這對於將模型部署到手機之外的終端裝置是非常有用的(注:目前無參考文獻論述TensorFlow Lite 的post-training模型量化原理,但是從原始碼可見壓縮方式是採用Int8)。
實驗環境需要解除安裝tensorflow並安裝tf-nightly。
pip uninstall -y tensorflow
pip install -U tf-nightly
量化壓縮模型實現很簡單,一下程式完成下載resnet_v2_101.tgz模型並解壓,設定converter.post_training_quantize = True,即可自動化實現,如所示, 作者在GPU M40實驗,量化輸出resnet_v2_101_quantized.tflite,僅用時3.76秒實現模型resnet_v2_101的量化壓縮,模型尺寸從179MB壓縮到45MB(圖22),優化後的模型在ImageNet top-1 準確率是76.8,與壓縮前模型準確率相同。

以上僅為個人閱讀論文後的理解,總結和一些思考,觀點難免偏差,望讀者以懷疑的態度閱讀,歡迎交流指正。
[1] Chollet, F.: Xception: Deep learning with depthwise separable convolutions. arXiv preprint (2016)
[2] Howard, A.G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., An- dreetto, M., Adam, H.: Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861 (2017)
[3] Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., Chen, L.C.: Inverted residuals and linear bottlenecks: Mobile networks for classification, detection and segmenta- tion. arXiv preprint arXiv:1801.04381 (2018)
[4] Zhang, X., Zhou, X., Lin, M., Sun, J.: Shufflenet: An extremely efficient convolu- tional neural network for mobile devices. arXiv preprint arXiv:1707.01083 (2017)
[5] Han, S., Mao, H., Dally, W.J., 2015a. Deep compression:Compressing deep neural networks with pruning,trained quantization and huffman coding. arXiv preprint arXiv:1510.00149(2015)
[6] Z. Qin, Z. Zhang, X. Chen, and Y. Peng, “FD-MobileNet: Improved MobileNet with a Fast Downsampling Strategy,” in arXiv:1802.03750, 2018.
[7] F. Chollet, “Xception: Deep Learning with Depthwise Separable Convolutions,” in Proc. of CVPR, 2017.
[8] Yihui He, Ji Lin, Zhijian Liu, Hanrui Wang, Li-Jia Li, and Song Han. AMC: AutoML for Model Compression and Acceleration on Mobile Devices. arXiv preprint arXiv: 1802.03494 (2018)
[9] https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/lite/tutorials/
[10] 讓演算法解放演算法工程師----NAS綜述,https://zhuanlan.zhihu.com/p/44576620
[11] Mingxing Tan, Bo Chen, Ruoming Pang, Vijay Vasudevan, and Quoc V Le. Mnasnet: Platform-aware neural architecture search for mobile. arXiv preprint arXiv:1807.11626, 2018.
[12] Liang-Chieh Chen,Maxwell D. Collins,Yukun Zhu,George Papandreou: Searching for Efficient Multi-Scale Architectures for Dense Image Prediction .arXiv preprint arXiv:1809.04184 (2018)