
Linux SPI匯流排和裝置驅動架構之四:SPI資料傳輸的佇列化
我們知道,SPI資料傳輸可以有兩種方式:同步方式和非同步方式。所謂同步方式是指資料傳輸的發起者必須等待本次傳輸的結束,期間不能做其它事情,用程式碼來解釋就是,呼叫傳輸的函式後,直到資料傳輸完成,函式才會返回。而非同步方式則正好相反,資料傳輸的發起者無需等待傳輸的結束,資料傳輸期間還可以做其它事情,用程式碼來解釋就是,呼叫傳輸的函式後,函式會立刻返回而不用等待資料傳輸完成,我們只需設定一個回撥函式,傳輸完成後,該回調函式會被呼叫以通知發起者資料傳送已經完成。同步方式簡單易用,很適合處理那些少量資料的單次傳輸。但是對於資料量大、次數多的傳輸來說,非同步方式就顯得更加合適。
對於SPI控制器來說,要支援非同步方式必須要考慮以下兩種狀況:
- 對於同一個資料傳輸的發起者,既然非同步方式無需等待資料傳輸完成即可返回,返回後,該發起者可以立刻又發起一個message,而這時上一個message還沒有處理完。
- 對於另外一個不同的發起者來說,也有可能同時發起一次message傳輸請求。
宣告:本博內容均由http://blog.csdn.net/droidphone原創,轉載請註明出處,謝謝!
/*****************************************************************************************************/
佇列化正是為了為了解決以上的問題,所謂佇列化,是指把等待傳輸的message放入一個等待佇列中,發起一個傳輸操作,其實就是把對應的message按先後順序放入一個等待佇列中,系統會在不斷檢測佇列中是否有等待傳輸的message,如果有就不停地排程資料傳輸核心執行緒,逐個取出佇列中的message進行處理,直到佇列變空為止。SPI通用介面層為我們實現了佇列化的基本框架。
spi_transfer的佇列化
回顧一下通用介面層的介紹,對協議驅動來說,一個spi_message是一次資料交換的原子請求,而spi_message由多個spi_transfer結構組成,這些spi_transfer通過一個連結串列組織在一起,我們看看這兩個資料結構關於spi_transfer連結串列的相關欄位:可見,一個spi_message結構有一個連結串列頭欄位:transfers,而每個spi_transfer結構都包含一個連結串列頭欄位:transfer_list,通過這兩個連結串列頭欄位,所有屬於這次message傳輸的transfer都會掛在spi_message.transfers欄位下面。我們可以通過以下API向spi_message結構中新增一個spi_transfer結構:struct spi_transfer { ...... const void *tx_buf; void *rx_buf; ...... struct list_head transfer_list; }; struct spi_message { struct list_head transfers; struct spi_device *spi; ...... struct list_head queue; ...... };
static inline void
spi_message_add_tail(struct spi_transfer *t, struct spi_message *m)
{
list_add_tail(&t->transfer_list, &m->transfers);
}通用介面層會以一個message為單位,在工作執行緒中呼叫控制器驅動的transfer_one_message回撥函式來完成spi_transfer連結串列的處理和傳輸工作,關於工作執行緒,我們留在後面討論。
spi_message的佇列化
一個或者多個協議驅動程式可以同時向控制器驅動申請多個spi_message請求,這些spi_message也是以連結串列的形式被過在表示控制器的spi_master結構體的queue欄位下面:
struct spi_master {
struct device dev;
......
bool queued;
struct kthread_worker kworker;
struct task_struct *kworker_task;
struct kthread_work pump_messages;
spinlock_t queue_lock;
struct list_head queue;
struct spi_message *cur_msg;
......
}extern int spi_async(struct spi_device *spi, struct spi_message *message);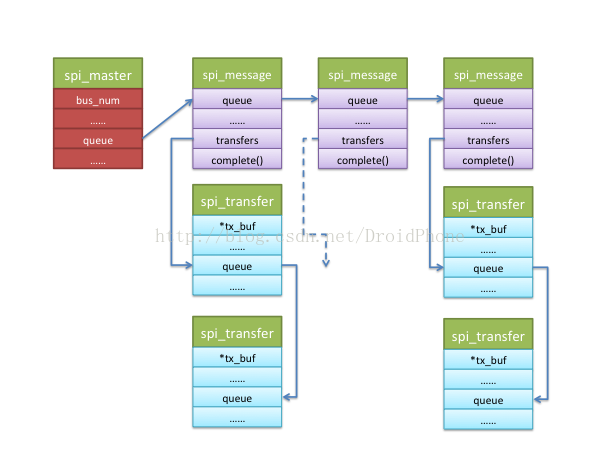
佇列以及工作執行緒的初始化
通過Linux SPI匯流排和裝置驅動架構之三:SPI控制器驅動這篇文章,SPI控制器驅動在初始化時,會呼叫通用介面層提供的API:spi_register_master,來完成控制器的註冊和初始化工作,和佇列化相關的欄位和工作執行緒的初始化工作正是在該API中完成的。我先把該API的呼叫序列圖貼出來:

圖2 spi_register_master的呼叫序列圖
如果spi_master設定了transfer回撥函式欄位,表示控制器驅動不準備使用通用介面層提供的佇列化框架,有關佇列化的初始化就不會進行,否則,spi_master_initialize_queue函式就會被呼叫:
/* If we're using a queued driver, start the queue */
if (master->transfer)
dev_info(dev, "master is unqueued, this is deprecated\n");
else {
status = spi_master_initialize_queue(master);
if (status) {
device_del(&master->dev);
goto done;
}
}static int spi_master_initialize_queue(struct spi_master *master)
{
......
master->queued = true;
master->transfer = spi_queued_transfer;
if (!master->transfer_one_message)
master->transfer_one_message = spi_transfer_one_message;
/* Initialize and start queue */
ret = spi_init_queue(master);
......
ret = spi_start_queue(master);
......
}static int spi_init_queue(struct spi_master *master)
{
......
INIT_LIST_HEAD(&master->queue);
......
init_kthread_worker(&master->kworker);
master->kworker_task = kthread_run(kthread_worker_fn,
&master->kworker, "%s",
dev_name(&master->dev));
......
init_kthread_work(&master->pump_messages, spi_pump_messages);
......
return 0;
}static int spi_start_queue(struct spi_master *master)
{
......
master->running = true;
master->cur_msg = NULL;
......
queue_kthread_work(&master->kworker, &master->pump_messages);
return 0;
}佇列化的工作機制及過程
當協議驅動程式通過spi_async發起一個message請求時,佇列化和工作執行緒被啟用,觸發一些列的操作,最終完成message的傳輸操作。我們先看看spi_async函式的呼叫序列圖:
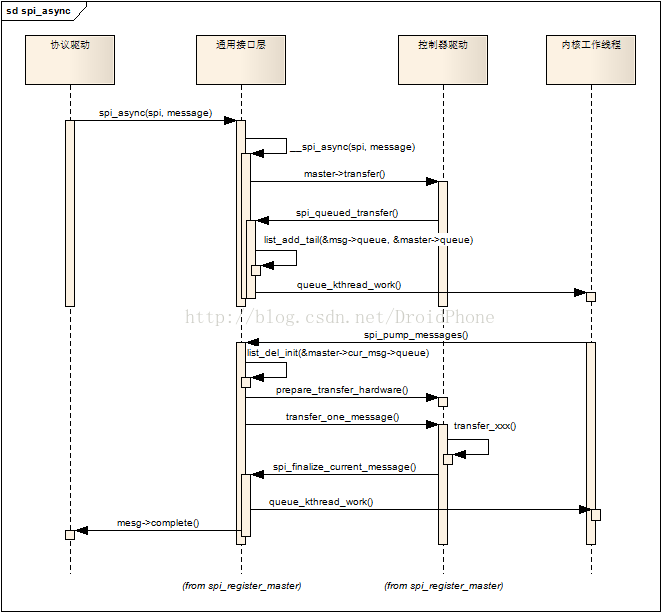
圖3 spi_async呼叫序列圖
spi_async會呼叫控制器驅動的transfer回撥,前面一節已經討論過,transfer回撥已經被設定為預設的實現函式:spi_queued_transfer,該函式只是簡單地把spi_message結構加入spi_master的queue連結串列中,然後喚醒工作執行緒。工作執行緒的工作函式是spi_pump_messages,它首先把該spi_message從佇列中移除,然後呼叫控制器驅動的prepare_transfer_hardware回撥來讓控制器驅動準備必要的硬體資源,然後呼叫控制器驅動的transfer_one_message回撥函式完成該message的傳輸工作,控制器驅動的transfer_one_message回撥函式在完成傳輸後,必須要呼叫spi_finalize_current_message函式,通知通用介面層繼續處理佇列中的下一個message,另外,spi_finalize_current_message函式也會呼叫該message的complete回撥函式,以便通知協議驅動程式準備下一幀資料。
關於控制器驅動的transfer_one_message回撥函式,我們的控制器驅動可以不用實現該函式,通用介面層已經為我們準備了一個標準的實現函式:spi_transfer_one_message,這樣,我們的控制器驅動就只要實現transfer_one回撥來完成實際的傳輸工作即可,而不用關心何時需壓氣哦呼叫spi_finalize_current_message等細節。這裡順便也貼出transfer_one_message的程式碼:
static int spi_transfer_one_message(struct spi_master *master,
struct spi_message *msg)
{
......
spi_set_cs(msg->spi, true);
list_for_each_entry(xfer, &msg->transfers, transfer_list) {
......
reinit_completion(&master->xfer_completion);
ret = master->transfer_one(master, msg->spi, xfer);
......
if (ret > 0)
wait_for_completion(&master->xfer_completion);
......
if (xfer->cs_change) {
if (list_is_last(&xfer->transfer_list,
&msg->transfers)) {
keep_cs = true;
} else {
cur_cs = !cur_cs;
spi_set_cs(msg->spi, cur_cs);
}
}
msg->actual_length += xfer->len;
}
out:
if (ret != 0 || !keep_cs)
spi_set_cs(msg->spi, false);
......
spi_finalize_current_message(master);
return ret;
}